上一篇我们将redis哨兵初始化分析完成,接下来我们就可以开始分析redis如何通过raft完成哨兵leader选举,并完成主从节点故障转移工作,因为篇幅原因,关于redis故障转移的内容将分为两个篇章,而这篇讨论的是哨兵如何完成主观下线的判定。

一、详解哨兵的主观认定下线的流程
1. 简述raft协议
在正式开始后续的文章讨论前,我们先来简单介绍一下分布式共识raft协议,这个是分布式系统中保证高可用的选举协议。该协议将所有分布式系统的节点分为3个角色:
- leader: 当前分布式集群中的主节点,即集群中的领导角色,负责承载当前系统中的核心业务。
- follower: 从节点,作为leader节点的跟随节点。
- candidate:一旦leader发生故障被slave感知,那么这些节点会将自身角色转为Canadian,并发起选举,得票数最多的Canadian将转为新的leader。
正常情况下,被选举为leader的节点会向follower节点发送心跳,告知自己当前还未下线:

一旦follower感知到leader下线,就会将自己身份转换为candidate,通过选举竞争leader,每一个candidate都会给自己投一票然后向其他选举节点获取选票,在选举计时时间以内,超过半数以上得票的candidate就会被选举为新的leader节点,其余candidate收到此leader的心跳消息后身份就会转为最新leader节点的follower:

2. redis中的raft协议与核心流程
与传统raft协议实现有所不同,redis哨兵在未发生选举时地位是对等并无leader和follower等概念,只有感知到监听主节点下线时才会借助raft的协议触发选举,选举出一个哨兵作为leader完成故障转移之后,leader哨兵会再次回归对等地位。
redis哨兵执行的生命周期还是交由时间事件定时执行,它的整体工作流程为:
- 检查自己所监听的master连接情况,检查是否与监听的master节点断开连接,如果发现连接断开则进行断线重连。
- 再对master节点进行消息通信,这期间哨兵会发送ping与主节点保持通信,再发送info请求master最新信息。
- 一旦发现master长时间未与自己进行心跳,则主观视为监听节点下线,并通过频道告知其他哨兵获取其他哨兵对于主节点的结果判断。
- 如果哨兵一致认定当前监听节点下线,则会选举出一个哨兵作为leader进行故障转移,即在所有从节点中找到一个优先级最高的从节点作为新的master。

对此我我们给出程序执行的入口来查看这块核心的主流程,可以看到serverCron定时执行的时间时间会每100ms执行一次哨兵的时间事件sentinelTimer,对此我们不妨步入sentinelTimer查看实现细节:
步入sentinelTimer,该函数会先判断哨兵执行时间是否过长,如果发现时钟回拨或者长时间才进行处理则触发tilt模式,该模式下哨兵只会定期发送和接收消息,不做其他任务处理。
再调用sentinelHandleDictOfRedisInstances遍历哨兵中的master开始开始进行我们上述所说的判断与master连接状态、进行通信和info消息获取、主观下线判断、客观下线判断、故障转移。
完成这些步骤之后,更新下一次的执行时间,可以看到redis对于这个时间设置做了一个巧妙的设计,我们都知道哨兵判定节点下线后就会发起选举,为了避免哨兵集群所有节点同时发起选举投票从而得到相同票数的情况而导致本轮选举失败而进行反复选举的情况,redis会在哨兵本次时间事件执行完成之后,通过随机种子调整哨兵时间下一次的执行时机,尽可能避免选举时反复出现选票一致的情况:

对此我们也给出sentinelTimer的实现细节:
我们再次步入核心方法sentinelHandleDictOfRedisInstances它会遍历每一个master节点,然后调用sentinelHandleRedisInstance处理每一个哨兵所监听的master实例:
步入sentinelHandleRedisInstance即可看到我们上文所说的而核心逻辑,它对于笔者上文的每一个流程都做了抽象,可以看到它会先尝试和断线的master建立连接,然后发送ping和info获取master节点的确认和master实时消息,最后在检查master是否超时未回复发起主观下线,然后再发起客观下线请求确认其他哨兵回复。 最后明确master节点确实下线之后再发起选举,得出leader后由leader进行故障转移,挑选出新的master承载核心业务。
3. 断线重连检查
基于上文我们了解哨兵时间事件执行的大体流程,接下来我们会针对每一个流程进行详细的分析,首先我们先来了解一下对于断线重连检查方法,对于断线重连检查,redis哨兵通过两个异步的连接进行处理,它通过cc这个异步连接和master建立通信完成PING和INFO的消息发送,再通过pc处理各种广播消息:

我们都知道redis将哨兵中每一个维护的master封装成sentinelRedisInstance ,这其中就有cc和pc两个连接指针,用于和当前哨兵建立连接和通信:
此时我们再来查看sentinelReconnectInstance方法内部,即非常直观了解到其内部对于断开或者为空的连接会调用redisAsyncConnectBind方法通过外部遍历master传入的master结构体信息发起异步连接重建:
4. 消息通信
完成连接重建之后,在所有连接正常的情况下,哨兵会检查当前发送上次ping间隔是否超过指定间隔,如果是则通过cc指指针向master发送ping。 同理如果info消息超过发送间隔也会生成当前哨兵ip端口等基本信息通过cc通道发送给masrter:

对此我们给出命令定期发送函数sentinelSendPeriodicCommands的入口,可以看到它会依次检查ping和hello消息的间隔逻辑,然后按需通过cc发送ping或者hello消息:
我们步入sentinelSendPing可以看到其内部逻辑比较简单,通过cc发送ping然后更新上次发送ping的时间戳字段last_ping_time:
同理我们给出sentinelSendHello函数,可以看到其内部会组装当前哨兵的ip和端口以及master的地址信息通过cc发送到__sentinel__:hello这个频道中进行广播:
5. 判定主观下线
然后就开始主观下线的检查,可以看到redis一旦发现master长时间未与当前哨兵进行通信,亦或者在很长一段时间都被报告为从节点,则将主观判定其下线,再通过或预运算符将ri的flags标志位注明这个master已经主观的被认定为下线。最后通过通过 +sdown这个channel 发送主观下线的消息,让他们各自检查,从而开始后续客观下线检查及选举和故障转移等操作:

对应的我们也给出sentinelCheckSubjectivelyDown函数的实现,可以我们补充弄一下down_after_period 这个是就是决定Sentinel判断实例进入主观下线所需的时间长度,默认情况下是30000毫秒,如果需要修改我们可以在redis.conf中用down-after-milliseconds指定:
二、小结
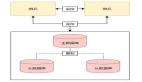
自此我们将redis哨兵主观下线的核心流程分析完成,我们来简单小结一下哨兵判断主观下线的流程:
- 哨兵实例随机一个hz参数作为定时器执行间隔,即执行一个哨兵定时事件sentinelTimer,
- sentinelTimer会定期调用sentinelHandleDictOfRedisInstances遍历检查监控的master进行定时的交互。
- 哨兵实例定期发送ping和hello亦或者info请求给master。
- master超过down_after_period设置的时间没有回应,或者其他角色长时间报告这个master已经是slave,则当前哨兵会主观认定其下线,并将消息发送到+sdown中。
- 结束一次定时任务后,定时器sentinelTimer执行完后设置下一次随机执行时间,保证在主观与客观认定master下线后通过随机性提升选举的效率。