在现代分布式系统中,全面掌握服务间的交互流程和性能瓶颈至关重要,而分布式追踪技术正是为此而生。OpenTelemetry 是当前广泛使用的一种开源工具链,能帮助开发者在多服务架构中轻松收集、分析和可视化系统运行数据。在本文中,我们将介绍如何使用 OpenTelemetry 的**零代码采集(Zero-code Instrumentation)**特性,结合 Java Agent 和 Grafana Tempo,实现对服务调用链的全面追踪。通过一系列配置和最佳实践,您可以在保持代码改动最小化的同时,快速上手分布式追踪,并获得对系统行为的深入洞察。
我们的目标:实现系统可观测性
让我们先来了解背景。作为开发人员,我们希望创建易于监控、评估和理解的软件系统。这正是实现 OpenTelemetry 的目的:最大化系统的可观测性。
传统的监控方法
通常,我们通过手动记录事件、指标和错误来获取应用性能数据:
 图片
图片
市场上有许多框架支持日志管理,相信大家都配置了用于收集、存储和分析日志的系统。
我们已经全面配置了日志系统,因此未使用 OpenTelemetry 提供的日志功能。
另一种常见的监控方式是通过 指标(Metrics):
 图片
图片
我们也已经配置了完整的指标收集与可视化系统,因此同样未使用 OpenTelemetry 的指标功能。
不过,对于获取和分析系统数据,追踪(Traces) 是一种较少被使用的工具:

追踪描述了请求在系统中的完整生命周期路径,通常从系统接收到请求开始,到生成响应结束。追踪由多个 跨度(Spans) 组成,每个跨度表示特定的工作单元,由开发人员或库定义。这些跨度形成一个层次结构,有助于直观了解系统如何处理请求。
本文我们将重点讨论 OpenTelemetry 的追踪功能。
OpenTelemetry 的背景介绍
OpenTelemetry 项目由 OpenTracing 和 OpenCensus 合并而来。它为多种编程语言提供基于标准的全面组件,定义了一套 API、SDK 和工具,旨在生成、收集、管理和导出数据。
需要注意的是,OpenTelemetry 本身并未提供数据存储后端或可视化工具。
由于我们关注追踪功能,我们探索了以下开源解决方案来存储和可视化追踪数据:
- Jaeger
- Zipkin
- Grafana Tempo
最终,我们选择了 Grafana Tempo,因为它提供了优秀的可视化功能、快速的开发进展,以及与我们现有的 Grafana 指标可视化设置的无缝集成。统一工具带来了极大的便利。
OpenTelemetry 的组件
让我们进一步剖析 OpenTelemetry 的核心组件。
规范部分
- API:定义数据类型、操作和枚举。
- SDK:规范的实现,提供不同语言的 API(各语言的 SDK 稳定性状态可能不同,从 Alpha 到稳定版)。
- 数据协议(OTLP) 和 语义约定。
Java API 和 SDK
- 代码自动化库:用于自动插桩的工具。
- 导出器(Exporters):用于将生成的追踪数据导出到后端。
- 跨服务传播器(Cross Service Propagators):用于将执行上下文传播到进程(JVM)外部。
此外,还有一个重要组件:OpenTelemetry 收集器(Collector),它是一个代理,用于接收、处理和转发数据。接下来我们将详细了解这一组件。
OpenTelemetry 收集器(Collector)
对于每秒处理数千个请求的高负载系统,管理数据量至关重要。追踪数据的量级通常超过业务数据,因此需要优先考虑哪些数据需要收集和存储。这就需要通过数据处理和过滤工具来确定重要数据,例如:
- 响应时间超过特定阈值的追踪。
- 处理过程中出现错误的追踪。
- 包含特定属性的追踪,例如经过某些微服务的请求。
- 一部分随机选择的普通追踪,用于了解系统的正常行为并识别趋势。
 图片
图片
两种主要采样方法:
- 头部采样(Head Sampling):在追踪开始时决定是否保留。
- 尾部采样(Tail Sampling):在完整追踪数据可用后才决定。这种方法适用于依赖后续数据的决策,例如包含错误跨度的情况。
OpenTelemetry 收集器帮助配置数据收集系统,确保只保存必要的数据。稍后我们将探讨它的配置。现在,让我们看看需要进行哪些代码更改来生成追踪数据。
零代码监控
通过零代码实现跟踪生成实际上只需要极少的编码工作——只需使用 Java Agent 启动应用程序,并指定配置文件:
OpenTelemetry 支持大量库和框架,因此,在使用 Agent 启动应用程序后,我们立即获得了有关服务之间请求处理阶段、数据库管理系统(DBMS)等的跟踪数据。
在我们的 Agent 配置中,我们禁用了不希望在跟踪中看到的库,同时为了获取代码运行的数据,我们使用注解标记代码:
在这个示例中,@WithSpan 注解被用于方法,表示需要为该方法创建一个名为“acquire locks”的新 Span。在方法主体中,还为创建的 Span 添加了一个名为“locks”的属性。
当方法运行完成时,Span 会被关闭。对于异步代码,这一点需要特别注意。如果需要获取异步代码中 lambda 表达式的运行数据,建议将这些 lambda 表达式分离到单独的方法中,并标记上附加的注解。
我们的跟踪数据收集配置
接下来,我们来讨论如何配置完整的跟踪数据收集系统。我们所有的 JVM 应用程序都使用 Java Agent 启动,并将数据发送到 OpenTelemetry 收集器。
然而,单个收集器无法处理大量的数据流,因此该系统需要进行扩展。如果为每个 JVM 应用程序启动一个单独的收集器,尾部采样(tail sampling)将无法正常工作,因为跟踪分析必须在一个收集器上完成。如果请求跨越多个 JVM,单个跟踪的不同 Span 将会被分散到不同的收集器上,无法进行统一分析。
在这种情况下,一个作为负载均衡器的收集器配置派上用场。
最终,我们获得了如下系统架构:每个 JVM 应用程序将数据发送到同一个负载均衡收集器,该收集器的唯一任务是将来自不同应用程序但属于同一跟踪的数据分配到同一个收集器处理器(collector-processor)。然后,收集器处理器将数据发送到 Grafana Tempo。
 图片
图片
接下来,我们详细分析系统中各组件的配置。
负载均衡收集器
在负载均衡收集器的配置中,我们配置了以下主要部分:
- Receivers:配置收集器接收数据的方法。在这里我们仅配置了以 OTLP 格式接收数据(还可以通过多种协议接收数据,例如 Zipkin、Jaeger)。
- Exporters:配置数据负载均衡的部分。该部分会根据跟踪标识符的哈希值,在指定的处理器收集器间分配数据。
- Service 部分:配置服务的工作方式,仅处理跟踪数据,使用上方配置的 OTLP 接收器并以负载均衡模式传输数据,而不进行处理。
数据处理收集器
处理器收集器的配置更为复杂,让我们详细了解:
与负载均衡收集器类似,处理器收集器也包含 Receivers、Exporters 和 Service 部分。但这里重点是 Processors 部分,它定义了数据的处理方式。
- tail_sampling部分:配置了用于存储和分析所需数据的筛选规则:
a.latency500-policy:筛选延迟超过 500 毫秒的跟踪。
b.error-policy:筛选在处理过程中发生错误的跟踪,查找 Span 中名为“error”的字符串属性,其值为“true”或“True”。
c.probabilistic10-policy:随机选择 10% 的所有跟踪,用于分析正常操作、错误和长时间请求的处理情况。
- resource/delete 部分:删除不必要的属性,以减少存储和分析的冗余数据。
最终效果
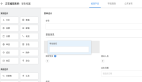
通过 Grafana 的跟踪搜索窗口,我们可以按各种条件筛选数据。例如,下图显示了来自处理游戏元数据的 Lobby 服务的跟踪列表:
 图片
图片
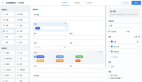
在跟踪视图窗口中,可以看到 Lobby 服务执行的时间轴,包括构成请求的各种 Span:
 图片
图片
查看 Span 时,可以看到详细属性,例如数据库查询:
 图片
图片
Grafana Tempo 的一个有趣功能是服务图,它以图形化方式展示导出跟踪的所有服务、它们之间的连接、请求速率和延迟:
 图片
图片
总结
通过本文的实践,我们展示了如何利用 OpenTelemetry 的零代码采集功能,实现对分布式系统中服务交互的高效追踪。使用 Java Agent 和 Grafana Tempo,我们能够轻松集成并可视化跨服务的调用链路。更重要的是,通过灵活的 Collector 配置,我们实现了高效的尾采样策略,为后续的性能分析和问题排查提供了可靠的数据支持。
分布式追踪不仅提升了系统的可观测性,更为优化服务性能、增强系统可靠性奠定了基础。借助 OpenTelemetry 和 Grafana Tempo 的可视化能力,开发团队可以快速发现和解决性能瓶颈,使系统能够更好地应对复杂业务场景的挑战。未来,我们期待结合更多功能扩展,如日志关联和指标分析,进一步完善系统的可观测性工具链。