从2024年12月DeepSeek出圈以来,DeepSeek风潮越刮越勇,已有席卷全球之势。各个大厂纷纷宣布自家接入DeepSeek,甚至有机顶盒企业也宣布自家产品接入了,市场情绪一度高涨。
在自媒体上,以DeepSeek为噱头卖课的,教人如何使用DeepSeek提示词的,或者利用DeepSeek+其他AI工具做自媒体赚快钱的,各种案例不胜枚举。
各个技术群的聊天话题也集中于DeepSeek,好像不聊这个话题就要被开除技术籍。
DeepSeek很火爆,我也并非资深的人工智能领域从业人员,但我却想泼一泼冷水。
首先思考一个问题:DeepSeek在功能和性能上,有远超其他大模型产品的表现吗?
答案很明显,并没有。DeepSeek官方于今年1月20日推出的DeepSeek R1版本,也只是在性能上对标Open AI o1正式版。
用DeepSeek官方的话来说:
“DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。”
官方论文: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
且这段时间大家应该都体验过DeepSeek,使用体验肯定很好,但其本身的工程能力(特指稳定性)却无法匹配其功能和性能的表现。换句话说,DeepSeek更像一个在某方面极其突出的年轻少侠,而非全方位无死角的六边形战士。
OpenAI的o1是什么时候发布的呢?以下是从多个公开信息源找到的信息:
1、OpenAI于2024年9月12日首次发布了o1的预览版(o1-preview)和轻量版(o1-mini)。这一版本主要面向ChatGPT Plus、Team用户以及API开发者开放,特点是强化了推理能力,适用于科学、数学和编程等复杂任务。
2、完整版的o1(或称“满血版”)于2024年12月5日至6日在OpenAI的“12天12场直播”首日活动中正式推出。该版本进一步优化了性能,错误率降低34%,响应速度提升50%,并支持多模态输入(文本+图像)。
总结:DeepSeek R1的发布是后发先至,在数学、代码、自然语言推理等任务上暂时取得了领先。
再来思考第二个问题:为什么DeepSeek会如此火爆,受到追捧?
按照业内的普遍共识,人工智能领域有三大底座(或者说三要素)是算力+模型+数据,也就是说只要你算力够多,模型够好,喂进去的数据量足够大,就可以迭代出我们预期的AI产品。
在三大底座之上,喂数据是训练过程,大规模应用是最终结果。在训练和大规模应用之间,还存在这样一个25年之前未被解决的问题,即:盈利模式。但DeepSeek的出现,带来了新的契机。
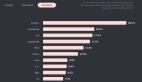
按照DeepSeek官方说法,他们在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了6个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
 图片
图片
HuggingFace 链接: https://huggingface.co/deepseek-ai
这一消息目前已经被证实,且国内外各家科技企业巨头的大模型都已开始接入DeepSeek,证明其成本相较于GPT-4确实有极大规模的下降。而成本的下降会带来这两点显著的直接收益:降低训练硬件需求,降低应用成本。
换句话说,降低训练需求等于打破了高算力的垄断门槛,降低应用成本意味着进入AI领域落地应用的门槛变低,会有更多的人有机会参与到探索应用落地的道路上。
从目前各种消息来看,模型降本已经指向了应用层的爆发,腾讯、阿里等大厂的走势已经说明了一切。
可能以后生活中的每台电子设备都会内置DeepSeek这种水平的大模型,而这也意味着AI+的爆款应用,大概率会在2025年横空出世!
除此之外DeepSeek火出圈的另一个原因在于:前两年各家公司的大模型逐渐同化,在数据层面没有显著差异的情况下,算力成为了唯一的决胜因素,而国产算力相比于英伟达,目前确实稍有不足。
DeepSeek的出现打破了过去两年的唯算力论,也让国内各大芯片厂商对追赶甚至超越“英伟达”重新燃起了希望。
这也是为什么前段时间,媒体报道说DeepSeek是“国运级”的产品。
回到本文的主题,即DeepSeek为什么会如此火爆?
一方面是人性使然导致的造神论,这点自古至今从未变过。另一方面,互联网自媒体时代,媒体和社区会不断助涨这种氛围,甚至说难听点,这是一种捧杀行为,严重点说实在扼杀整个中国的创新氛围。
DeepSeek引起全球关注甚至诧异本身是件好事,但是这种整个产业界甚至全国性质的捧杀,我个人并不认同。
在大模型的方向、技术路线、资源投入各方面,每个公司都有差异。
比如有的公司坚持长期主义选择dense模型,有的公司选择扩展探索面在各种模态上都发展业务,至于像Deepseek押注moe,以及deepseek首先突破应用了预训练fp8(之前有mla),也确实是一直走在一流团队的前沿。
借用DeepSeek创始人梁文峰话来说:大部分中国公司习惯follow,而不是创新。中国AI和美国真实的gap是原创和模仿的差距。如果这个不改变,中国永远只能是追随者,所以有些探索是逃不掉的。英伟达的领先,不只是一个公司的努力,而是整个西方技术社区和产业共同努力的结果。创新首先是一个信念问题,OpenAI并不会一直领先。
同理,DeepSeek暂时领先也很难说会一直领先!
我很敬佩梁文峰先生的务实和专注风格,也很希望国内出现越来越多的像DeepSeek这样的产品。很多的前沿创新都是基于务实和专注才会出现,希望大家能对当前对DeepSeek的造神保持警惕。
真正的科技创新型社会是百花齐放,百舸争流。