Kafka是大型架构的必备中间件,也是大厂必备技能,下面我就重点详解高并发场景下,Kafka实现高并发的关键技术@mikechen
Kafka架构设计
Kafka 通过分布式架构、分区机制、以及集群管理,实现了高并发性能。
Kafka 架构,由多个 Broker(服务器节点)组成,每个 Broker 负责存储、和管理部分消息。
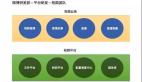
整体架构,如下图所示:
 图片
图片
其中,Topic 分区(Partitioning) 是 Kafka 分布式设计的核心,它将消息分散存储在不同节点上。
Kafka 支持水平扩展,可以通过增加 Broker 节点,来提升系统的容量和性能。
新增的 Broker 会自动参、与分区的存储和管理,分担原有节点的压力。
例如:一个拥有 10 个分区的主题,理论上可以支持 10 倍于单分区主题的并发读写操作。
所以,分区使得 Kafka 天然支持并行处理,大大提升了系统的并发能力。
Kafka高并发关键技术
Kafka 之所以能够实现高吞吐量、和低延迟的消息处理,其核心设计还有是磁盘顺序写(Sequential Disk Writes)。
 图片
图片
磁盘顺序写:指的是在磁盘上按照顺序依次写入数据,而不是随机地在不同位置写入。
传统的机械硬盘由盘片、磁头臂、磁头等部件组成,数据存储在盘片的不同磁道和扇区上。
当进行随机写操作时,磁头需要频繁地移动到不同的位置,这个过程涉及寻道和旋转延迟,会极大地影响写入性能。
而顺序写时,磁头可以沿着一个方向连续地写入数据,减少了寻道和旋转延迟,从而提高了写入效率。
Kafka正是利用了这一点,极大的提升了数据写入性能。
Kafka 通过将消息,顺序追加(Append)到日志文件末尾,充分利用了这一特性,从而,避免了随机寻址的开销。
零拷贝
零拷贝(Zero-Copy)是一种计算机技术,其核心目标是减少、或消除数据,在传输过程中的拷贝。
在传统的数据传输过程中,数据通常需要在用户空间(User Space)、和内核空间(Kernel Space)之间多次拷贝。
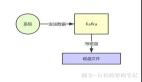
如下图所示:
 图片
图片
首先,数据从磁盘读取到内核空间的缓冲区。
其次,内核空间的缓冲区,将数据复制到用户空间的缓冲区。
然后,用户空间的缓冲区,再将数据写入到网络接口、或其他输出设备。
这种多步复制,会消耗大量 CPU 资源,并增加延迟。
而零拷贝技术,通过优化数据传输路径,减少数据在用户空间和内核空间之间的多次拷贝,
比如:通过Linux的mmap() 系统调用,可以将文件或设备的内存空间,映射到用户空间的地址空间。
然后,应用程序可以像访问内存一样直接访问文件内容;
接着,使用 write() 系统调用将数据从用户空间的缓冲区发送到网络套接字。
在这个过程中,避免了从内核缓冲区、到用户空间缓冲区、再到内核套接字缓冲区的两次拷贝。
所以,减少了数据在不同存储区域之间的移动次数,提高了数据传输的吞吐量,也提升了并发性能。