













DeepSeek 引爆 AI 社区后,人们都在尝试本地部署和各领域应用,在新模型基础上持续改进的方向也被不断提出。与此同时,英伟达却在尝试用 DeepSeek 给大模型 pipeline 本身搞自动化。
本周三,英伟达在博客中介绍了利用 DeepSeek-R1 和推理时扩展技术来自动生成优化 GPU 内核的最新研究成果,效果异常的好。

对此有人评价道:难不成英伟达在自拆护城河?
也有人已经开始担心自己的工作会不会被 AI 代替了。

随着 AI 大模型规模不断扩展,能力持续进步,测试时扩展(TTS:Test-Time Scaling)或推理时扩展(Inference-Time Scaling)法则正在兴起。这项技术也被称为 AI 推理或长思考,它通过在推理过程中分配额外的计算资源来评估多种可能的结果,然后选择最佳的一个,从而提高模型整体性能。
推理能力的加强使得 AI 初步掌握了类似于人类剖析复杂问题的能力,能逐个解决以得出最终解决方案的方式,进行策略性思考和系统性地解决复杂问题。
在英伟达这篇文章中,工程师们进行了一项实验,他们使用最新、最热门的开源大模型 DeepSeek-R1 在推理过程中利用额外的计算能力来解决一个复杂问题 —— 自动生成数值正确,且针对不同注意力变体优化的 GPU 注意力内核,而无需任何显式编程。
人们发现在某些情况下,R1 输出的结果甚至优于由熟练工程师开发出来的优化内核。
对优化注意力内核的需求及相关挑战
注意力机制是彻底改变大型语言模型(LLM)发展的一个关键概念。它是一种强大的机制,使 AI 模型在执行任务时能够选择性地关注输入中最相关的部分。通过专注于重要信息,注意力操作帮助模型做出更好的预测并发现数据中的隐藏模式。
注意力操作的计算复杂度与输入序列长度的平方成正比增长。这促使我们需要开发优化的底层实现(即 GPU 内核),以防止简单实现导致的运行时错误(如内存不足错误),并提高计算效率。
另外,注意力有多种变体(因果注意力、相对位置嵌入、ALiBi 等),工程师通常需要为特定任务组合使用这些变体。
多模态模型(例如视觉 Transformer)引入了额外的挑战,因为它们需要专门的注意力机制(如空间邻域注意力)来维护计算机视觉、视频生成模型等中常见的时空信息。

图 1:2D 输入上的邻域注意力。
但在这个任务上,即使对于经验丰富的软件工程师来说,创建针对注意力的优化 GPU 内核也需要大量技能和时间。
最近的大模型(如 DeepSeek-R1)在代码生成任务中表现出了很大的潜力,但它们在第一次尝试创建优化代码时仍然效果不好。这使得在推理时使用其他策略来生成优化代码成为了必要。
以下 Prompt 是相对位置嵌入注意力内核的示例用户输入。
大模型有时会产生幻觉,或输出混合不同语言或框架的语法,导致生成的代码错误或效率低下。计算最佳 GPU 线程映射也是一项艰巨而具有挑战性的任务,通常需要迭代细化才能获得正确且高效的内核。
用于生成优化 GPU 内核的推理时扩展
为了利用优化的注意力内核获得最佳结果,英伟达工程师创建了一个新的工作流程,包括了一个特殊的验证器以及一个在预定时间内以闭环方式进行推理的 DeepSeek-R1 模型。
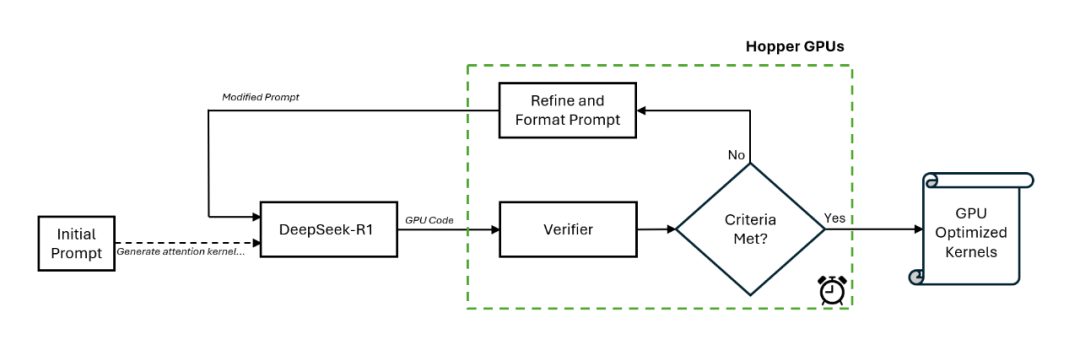
图 2:在 Nvidia Hopper 平台上利用 DeepSeek-R1 的推理时扩展。
具体地讲,该工作流程首先由手动提示进行初始化,然后 DeepSeek-R1 在第一次遍历中生成 GPU 代码(即内核)。验证器在一块英伟达 H100 GPU 上运行,它对生成的内核进行分析,并创造新的提示以作为输入提供给 DeepSeek-R1。
这种闭环方法每次都以不同的方式引导代码生成过程,从而实现更好的效果。英伟达发现,这个过程持续 15 分钟就可以得到一个改进的注意力内核。
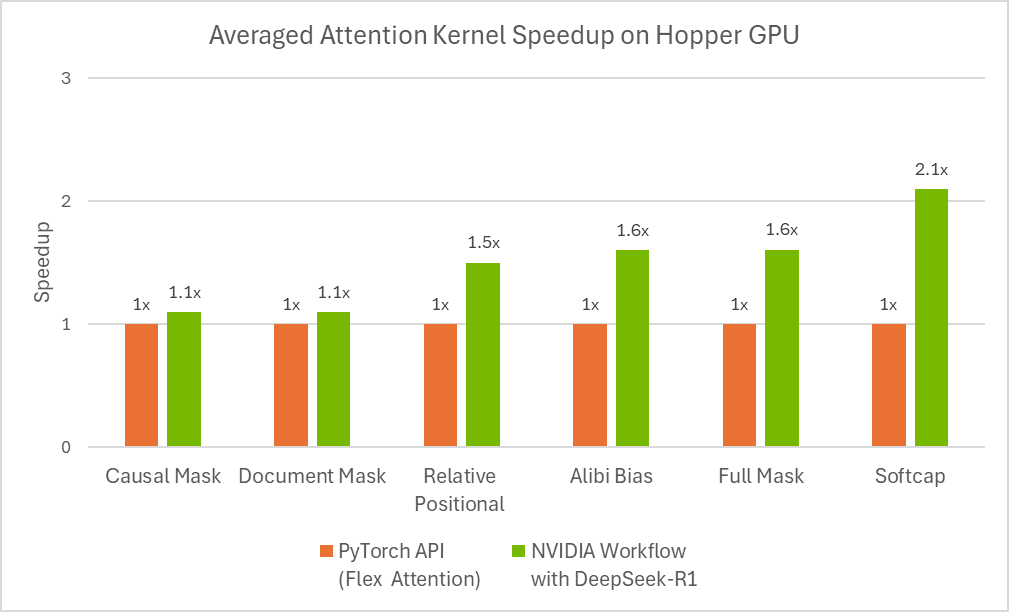
图 3:使用 flex attention 自动生成的优化注意力内核的性能。
根据斯坦福的 KernelBench 基准测试,该工作流程可以为 100% 的 Level-1 问题和 96% 的 Level-2 问题生成数值正确的内核。
其中,KernelBench 中的 Level-1 解决率是指:评估 LLM 为特定计算任务生成高效 GPU 内核的能力的数值正确指标。该测试是一系列「测试最新 LLM GPU 编程能力」挑战的一部分。
图 4 显示了推理时预算对 agent 解决率的影响,结果显示,在 Level-1 类别中为每个问题分配超过 10 分钟的时间,可以使工作流程为 100 个问题中的大多数生成数值正确的代码。

这些结果表明,在使用最新的 DeepSeek-R1 模型时,如果在推理阶段投入更多计算,则可以获得更好的 GPU 内核。英伟达表示,其对于 DeepSeek-R1 的最新进展及其应用潜力感到非常兴奋。





























