近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。
PPO属于在线策略梯度方法的范畴。其基础形式可以用带有优势函数的策略梯度表达式来描述:

策略梯度的基础表达式(包含优势函数)。
这个表达式实际上构成了优势演员-评论家(Advantage Actor-Critic)方法的基础目标函数。PPO算法可以视为对该方法的一种改进和优化。
PPO算法的损失函数设计
PPO通过引入策略更新约束机制来提升训练稳定性。这种机制很好地平衡了更新幅度:过大的策略更新可能导致训练偏离优化方向,而过小的更新则可能降低训练效率。为此,PPO采用了一个特殊的替代目标函数,该函数由裁剪项和非裁剪项组成,并取两者的最小值。
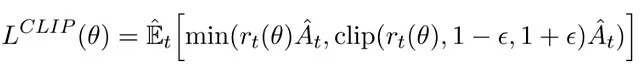
PPO的损失函数结构。
替代损失函数的非裁剪部分分析
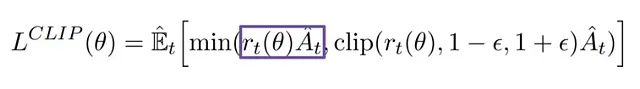
损失函数中的非裁剪部分示意图。
在PPO中,比率函数定义为在状态st下执行动作at时,当前策略与旧策略的概率比值。
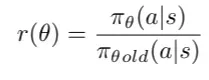
策略概率比率r(θ)的定义。
这个比率函数r(θ)为我们提供了一个度量新旧策略差异的有效工具,它可以替代传统策略梯度目标函数中的对数概率项。非裁剪部分的损失通过将此比率与优势函数相乘得到。

非裁剪部分损失计算示意图。
替代损失函数的裁剪机制
为了防止过大的策略更新,PPO引入了裁剪机制,将策略比率r(θ)限制在[1-ϵ, 1+ϵ]的区间内。其中ϵ是一个重要的超参数,在PPO的原始论文中设定为0.2。这样,我们可以得到完整的PPO目标函数:

PPO完整目标函数,包含非裁剪项和裁剪项。
PPO的最终优化目标是在这两部分中取较小值,从而实现稳定的策略优化。
算法实现流程
PyTorch实现详解
1、初始化
2、回合循环
2.1 重置环境
2.2 当回合未结束时:
演员预测动作概率并从分布中采样动作。
获取对数概率,这被视为比率的log pi_theta_old
在环境中执行动作,获取下一个状态、奖励和终止标志。
2.3 计算折扣回报
2.4 将每个回合的经验存储在batch_data中
2.5 每update_freq回合更新网络:
计算状态值
计算优势。
计算演员和评论家的PPO损失。