还在为DeepSeek模型部署的各种难题抓狂?各种教程的下载分片、合并模型、编译环境……这些繁琐的操作是不是让你头大?DeepSeek R1 火了,私有部署需求暴增,教程满天飞,但实际操作起来却麻烦得要命!更别提多机分布式推理、高并发生产环境、国产芯片适配这些复杂场景,现有方案要么配置复杂,要么性能不达标,简直让人崩溃!
别慌,今天介绍的GPUStack 这个开源项目(https://github.com/gpustack/gpustack/)一出手,直接解决 DeepSeek R1 私有部署的所有痛点:
• 一键安装部署,Linux、macOS、Windows全平台支持
• 模型资源需求自动计算,按需自动分布式推理,告别手动配置
• 支持 NVIDIA、AMD、Mac、海光、摩尔线程、华为昇腾等多种硬件
接下来,我们通过几种典型的部署场景,展示 GPUStack 在面对不同环境的兼容性。
以桌面场景和生产场景为例,GPUStack 对各种部署场景都提供了强大的支持:
桌面场景
• 单机运行小参数量模型
在 Windows 和 macOS 桌面设备上,单机运行 DeepSeek R1 1.5B ~ 14B 等小参数模型。如果 VRAM 不足,GPUStack 也支持将部分模型权重加载到内存,实现 GPU & CPU 混合推理,确保在有限硬件资源下的运行。
• 分布式推理运行大参数量模型
当单机无法满足模型运行需求时,GPUStack 支持跨主机分布式推理。例如:
多机分布式推理
• 使用一台 Mac Studio 可以运行 Unsloth 最低动态量化(1.58-bit)的 DeekSeek R1 671B 模型,更高的量化和动态量化版本可以通过分布式推理功能,使用两台 Mac Studio 分布式运行。还可以灵活多卡切分比例和满足更多的场景需求,例如更多的分布式节点和更大的上下文设置。
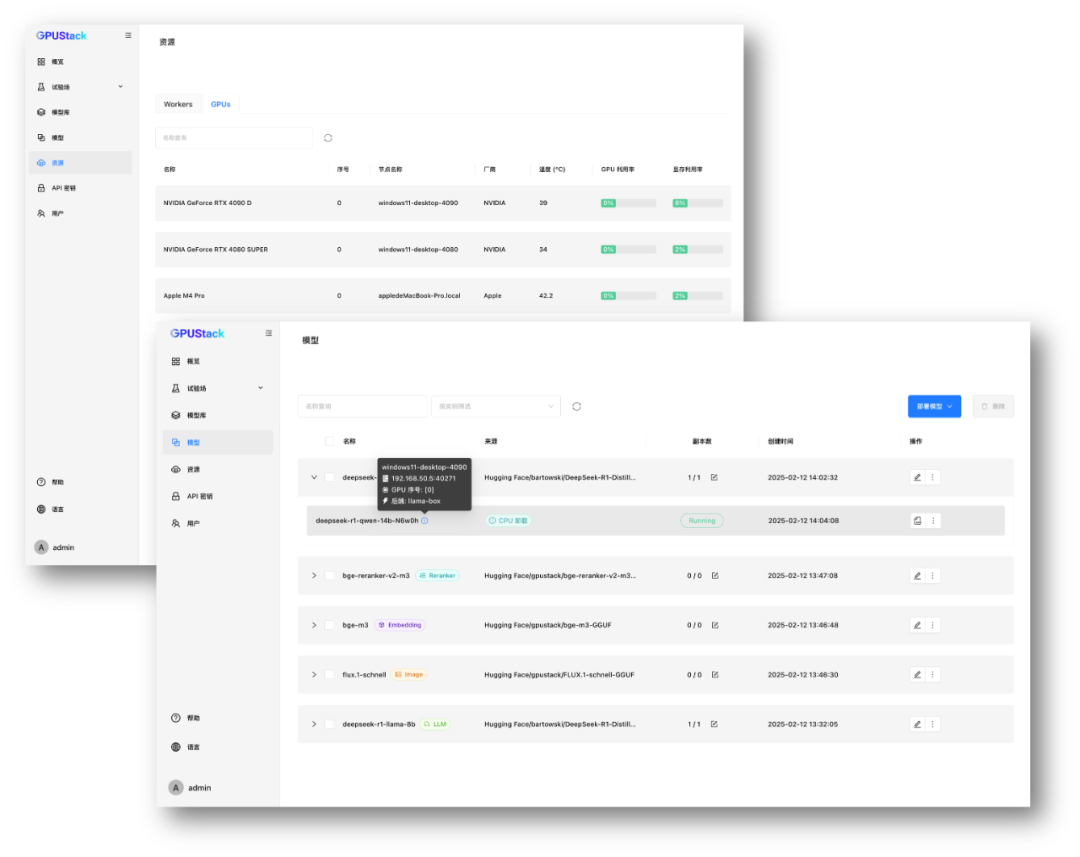
异构分布式推理
使用:
• 一台 Ubuntu 服务器,搭载 NVIDIA RTX 4090(24GB VRAM)
• 一台 Windows 主机,搭载 AMD Radeon RX 7800(16GB VRAM)
• 一台 MacBook Pro,搭载 M4 Pro,拥有 36GB 统一内存
聚合这些异构设备的 GPU 资源,运行单机无法运行的 DeepSeek-R1 32B 或 70B 量化蒸馏模型,充分利用多台设备的算力来提供推理。
生产场景
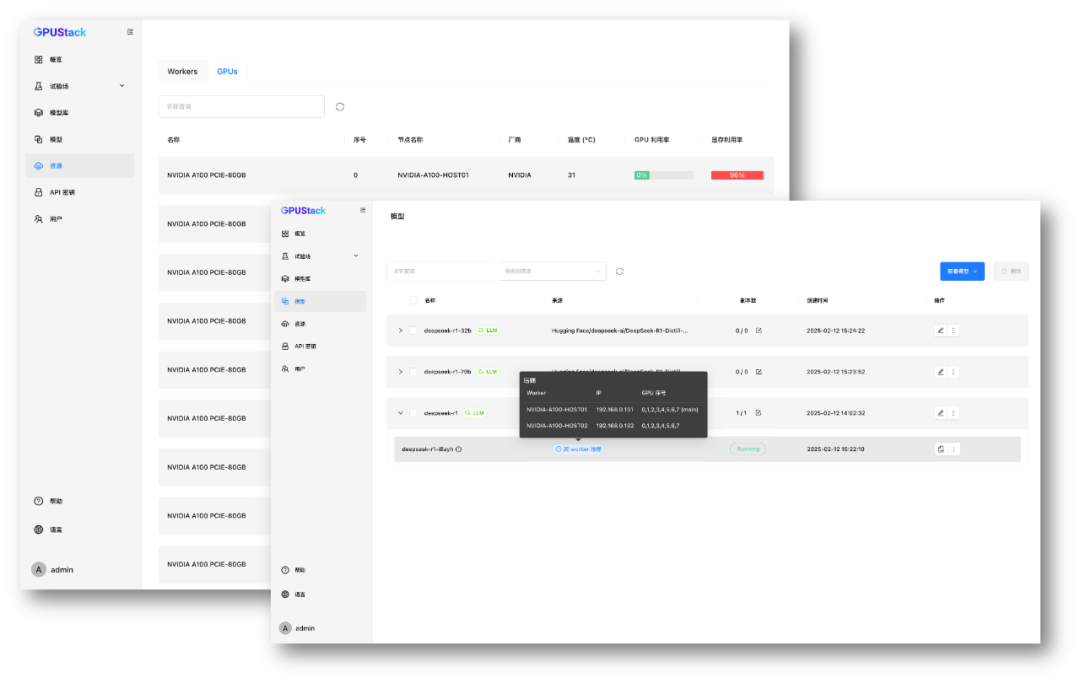
• 多机部署超大模型
在 2 台 8 卡 NVIDIA A100 服务器上,利用 GPUStack 多机分布式推理,运行 DeepSeek R1 671B 量化版本,突破单机显存限制,高效执行超大规模模型推理。
 a100-distributed-interence
a100-distributed-interence
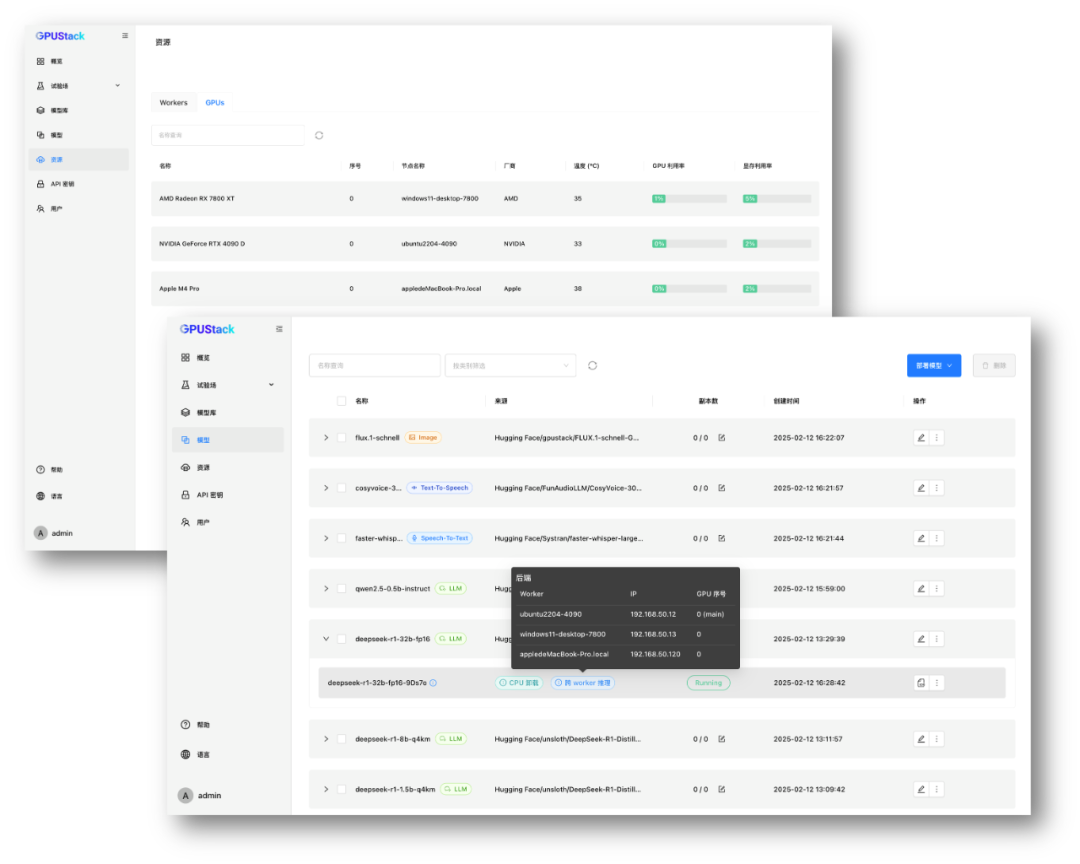
• 高并发高吞吐的生产部署
在需要高并发、高吞吐、低延迟的生产环境中,使用 vLLM 高效部署推理 DeepSeek R1 全量版或蒸馏版,充分利用推理加速技术支撑大规模并发请求,提升推理效率。
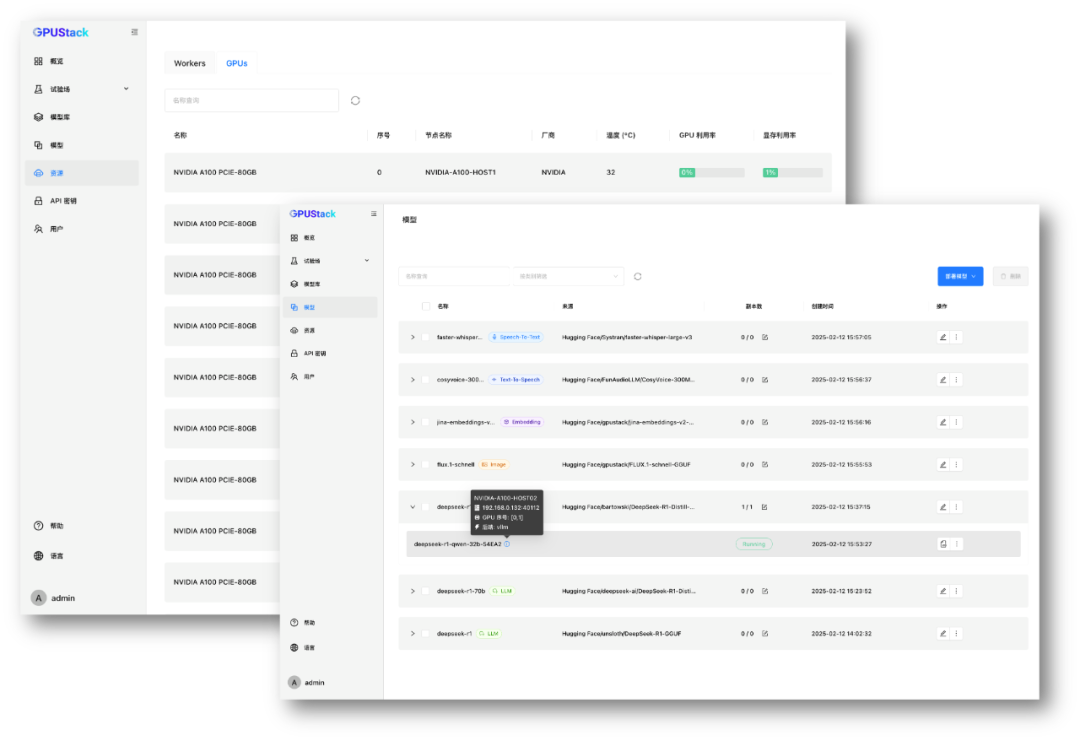 a100-vllm
a100-vllm
• 国产硬件适配
在昇腾、海光等国产 GPU 上,GPUStack 也提供适配支持。例如,在 8 卡海光 K100_AI 上运行 DeepSeek R1 671B 量化或蒸馏版本,充分发挥国产硬件的计算能力,实现自主可控的私有化部署方案。
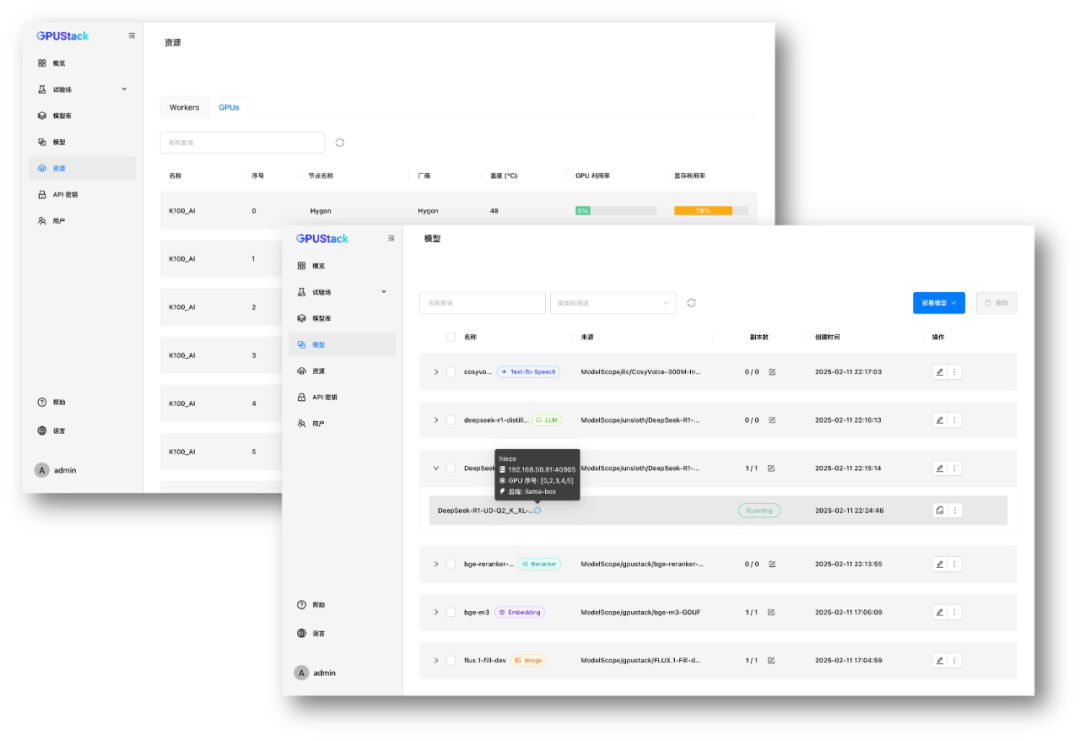
对于诸如上述的各种部署场景,GPUStack 都能根据环境自动选择最佳部署方案,提供自动化的一键部署,用户不需要繁琐的部署配置。同时用户也拥有自主控制部署的灵活性。
以下是 DeepSeek R1 各个蒸馏模型和满血 671B 模型在不同量化精度下的显存需求及相应推荐硬件,供在各种场景下部署提供参考:
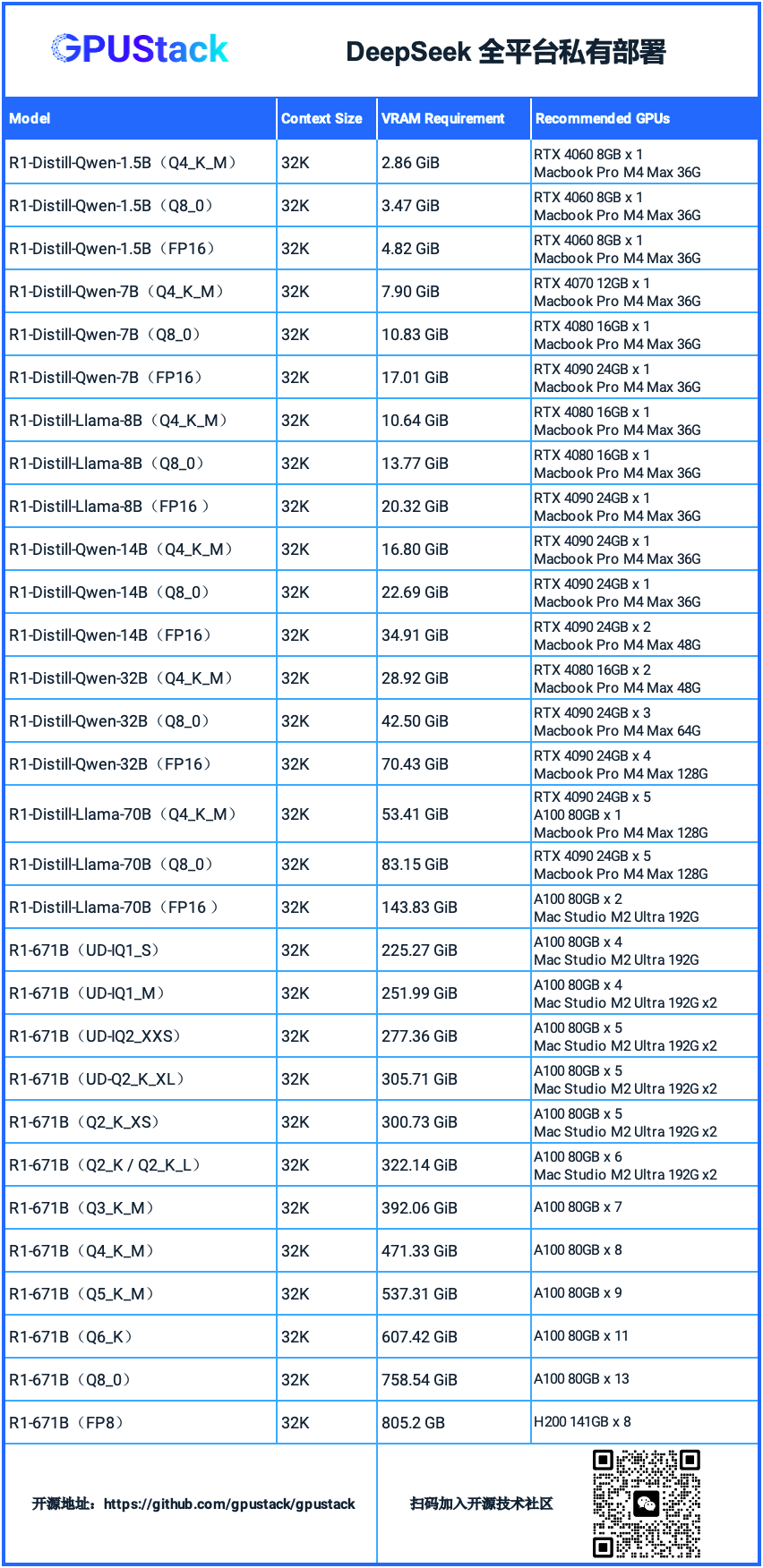
不同的模型、量化方式、上下文大小、推理参数设置或多卡并行配置对显存需求各不相同。对于 GGUF 模型,可以使用模型资源测算工具 GGUF Parser(https://github.com/gpustack/gguf-parser-go)来手动计算的显存需求。实际部署时,GPUStack 会自动计算并分配适合的显存资源,无需用户手动配置。
 gguf-parser
gguf-parser
GPUStack 不仅支持 大语言模型(LLM),还支持更多生成式 AI 模型类型,包括:
• 多模态模型(如 Qwen2-VL、InternVL 2.5)
• 图像生成模型(如 Stable Diffusion、Flux)
• 语音模型(STT/TTS)(如 Whisper、CosyVoice)
• Embedding 模型(如 BGE、BCE、Jina)
• Reranker 模型(如 BGE Reranker、Jina Reranker)
无论是在桌面端还是数据中心,GPUStack 都能满足各种环境和应用场景下的私有模型部署需求,提供高效、灵活的推理解决方案。
GPUStack 更是一个综合性的解决方案,提供国产化支持、就地升级、模型升级、推理引擎多版本并存、负载均衡高可用、用户管理、API 认证授权、GPU 和 LLM 观测指标、Dashboard 仪表板、离线部署等各种运维管理能力,帮助开发和运维人员轻松应对异构适配、模型迭代、权限控制、运维观测等管理需求,降低了大模型部署和管理的复杂度。
如果对 GPUStack 感兴趣,可以参考以下步骤进行安装部署。
安装 GPUStack
安装要求参考:https://docs.gpustack.ai/latest/installation/installation-requirements/
GPUStack 支持脚本一键安装、容器安装、pip 安装等各种安装方式,这里使用脚本方式安装。
在 Linux 或 macOS 上:
通过以下命令在线安装,安装完成需要输入 sudo 密码启动服务,这个步骤需要联网下载各种依赖包,网络不好可能需要花费十几到几十分钟的时间:
在 Windows 上:
以管理员身份运行 Powershell,通过以下命令在线安装,这个步骤需要联网下载各种依赖包,网络不好可能需要花费十几到几十分钟的时间:
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
接下来按照脚本输出的指引,拿到登录 GPUStack 的初始密码,执行以下命令:
在 Linux 或 macOS 上:
在 Windows 上:
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。
重新设置密码后,进入 GPUStack:
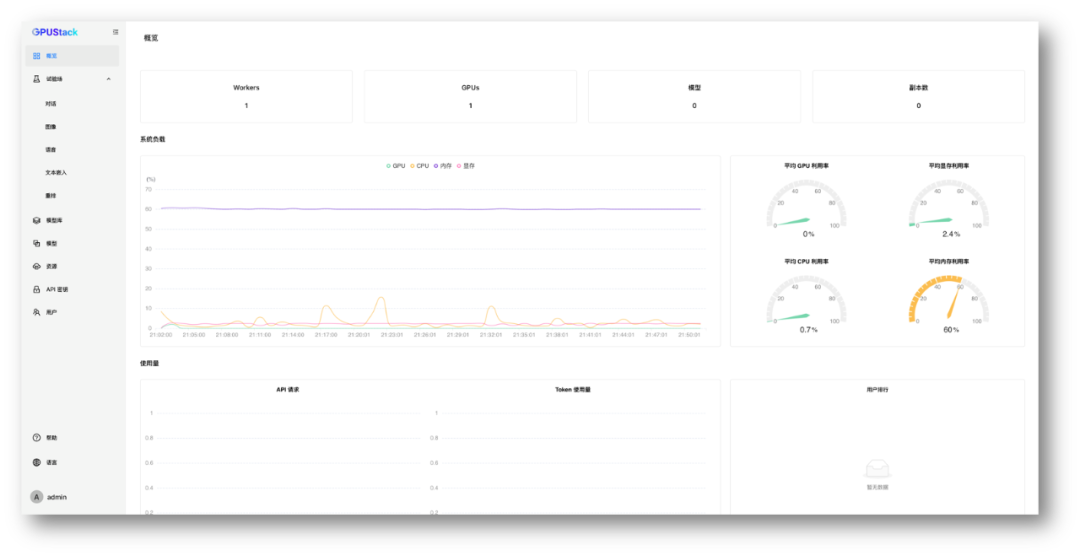 overview
overview
纳管 GPU 资源
GPUStack 支持纳管 Linux、Windows 和 macOS 设备的异构 GPU 资源,步骤如下。
其他节点需要通过认证 Token 加入 GPUStack 集群,在 GPUStack Server 节点执行以下命令获取 Token:
在 Linux 或 macOS 上:
在 Windows 上:
拿到 Token 后,在其他节点上运行以下命令添加 Worker 到 GPUStack,纳管这些节点的 GPU(将其中的 http://YOUR_IP_ADDRESS
在 Linux 或 macOS 上:
在 Windows 上:
通过以上步骤,我们已经安装好 GPUStack 并纳管了多个 GPU 节点,接下来就可以使用这些 GPU 资源来部署所需的各种 DeekSeek R1 满血、量化、蒸馏模型和其他模型了。
总结
以上是关于如何安装 GPUStack 并在不同场景下部署 DeekSeek R1 模型的使用教程。你可以访问项目的开源仓库:https://github.com/gpustack/gpustack 了解更多信息。
GPUStack 是一个低门槛、易上手、开箱即用的私有大模型服务平台。它可以轻松整合并利用各种异构 GPU 资源,方便快捷地为生成式 AI 应用和应用开发人员部署所需的各种 AI 模型。
无论是 Linux、Windows 还是 macOS,或是各种单机、多机异构部署场景,GPUStack 都能一键部署各种生成式 AI 模型,且不局限于大语言模型,还支持多模态模型、图像模型、语音模型、Embedding 模型以及 Reranker 模型,满足各种环境和应用场景的私有模型部署需求。
GPUStack 背后的研发团队具有全球顶级开源项目经验,项目的功能设计和文档都很完整,团队自项目初期便面向全球用户,当前已有大量国内外开源用户。团队致力于将国产开源项目推广到全球,值得关注。
在开始体验 GPUStack 之前,记得在其 GitHub 仓库给项目点个 Star 以资鼓励,在新版本发布时也能收到更新通知:https://github.com/gpustack/gpustack。