













01、概述
随着开源推理模型如 DeepSeek-R1 的崛起,开发者可以在本地运行强大的 AI,而不再依赖于云服务。这一技术的出现引发了不小的网络热议,或许你也在好奇如何利用这一模型在本地搭建自己的 AI 系统。
本指南将带你了解两种关键的使用场景:
普通用户:创建一个 ChatGPT 风格的界面
开发者:通过 API 集成模型到应用中
在开始之前,如果你有兴趣深入了解 DeepSeek-R1 的背景,以便更好地理解接下来的过程,可以参考我的文章《DeepSeek-R1 理论简介(适合初学者)》。
02、本地部署必备工具
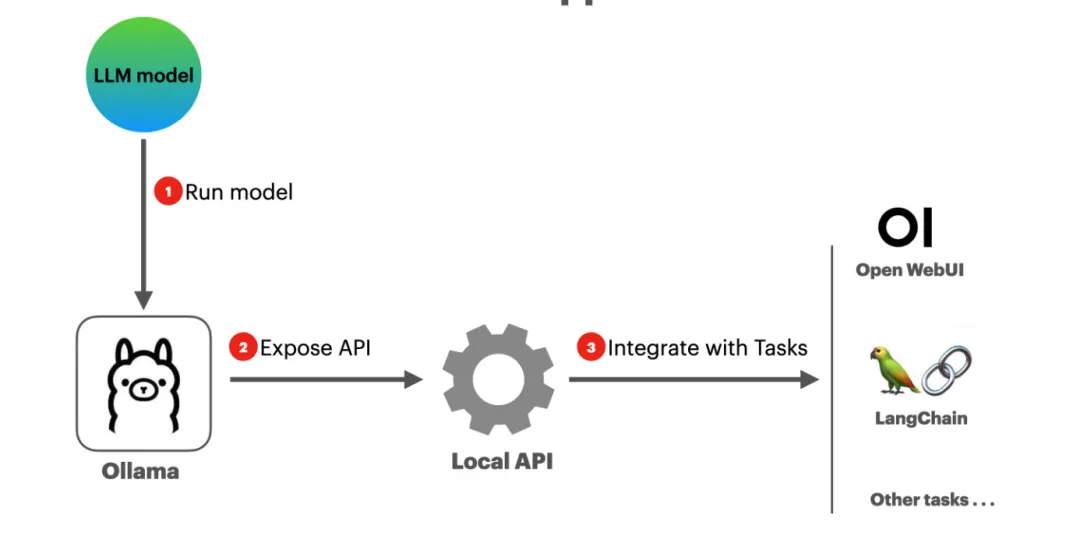
1. 安装 Ollama
首先,我们需要安装 Ollama,这是一个可以帮助你在本地下载并托管 DeepSeek-R1 模型的工具。无论你是 macOS M 系列、Windows 还是 Linux 用户,都可以通过以下方式安装 Ollama:
macOS 或 Windows 用户:可以访问 Ollama 官方网站 下载并安装适合你系统的版本。
Linux 用户:使用命令行安装:
这会安装模型运行工具,并自动启用 GPU 加速(Apple M 系列使用 Metal,NVIDIA 显卡使用 CUDA)。
简单来说,Ollama 是一个帮助你下载并本地运行 DeepSeek-R1 模型的工具,同时它也能让其他应用能够调用该模型。
2. 下载 DeepSeek-R1 模型
根据你的硬件配置选择适合的 DeepSeek-R1 版本。你可以在 DeepSeek-R1 模型库 中查看不同版本的模型。值得注意的是,模型有精简版和完整版之分,精简版的模型保留了原版模型的大部分功能,但体积更小,运行速度更快,对硬件的要求也较低。
大部分情况下,较大的模型通常更强大,但对于本地托管而言,我们建议选择一个适合你 GPU 性能的版本。幸运的是,DeepSeek-R1 提供了一个 compact 版本 DeepSeek-R1-Distill-Qwen-1.5B,它仅使用大约 1GB 的显存,甚至可以在 8GB 内存的 M1 MacBook Air 上运行。
安装命令如下:
03、场景 1:ChatGPT 风格的聊天界面
如果你想体验 DeepSeek-R1 模型,并通过一个 ChatGPT 风格的界面与其互动,可以利用 Open WebUI 来实现。这是一个用户友好的聊天界面,适用于本地托管的 Ollama 模型。
通过以下 Docker 命令,快速部署 Open WebUI:
部署完成后,打开浏览器访问 http://localhost:3000,创建一个账户,并从模型下拉菜单中选择 deepseek-r1:1.5b。
使用本地部署的 LLM 进行聊天具有以下几个优势:
易于访问:你可以随时试验不同的开源模型。
离线聊天:无需互联网连接,你依然可以使用类似 ChatGPT 的服务来提高工作效率。
更高的隐私保护:因为聊天数据完全保存在本地,避免了敏感信息泄露的风险。
04、场景 2:开发者的 API 集成
如果你已经将 DeepSeek-R1 在本地托管,并且是开发者,你可以通过 Ollama 提供的 OpenAI 兼容 API 轻松集成模型到应用中。API 地址为 http://localhost:11434/v1。
使用 OpenAI Python 客户端进行集成:
使用 LangChain 集成:
更多相关代码和设置可以参考 GitHub 上的项目:DeepSeek-R1 本地 API 集成指南。
05、总结
通过 Ollama 和 DeepSeek-R1,你现在可以在本地使用 GPU 加速运行强大的 AI,体验 ChatGPT 风格的聊天界面,并且通过标准的 API 将 AI 能力集成到你的应用中——这一切都在离线状态下进行,确保了隐私保护。
无论你是普通用户想要快速体验 AI 聊天功能,还是开发者希望将强大的语言模型融入自己的应用中,DeepSeek-R1 都是一个非常适合的选择。
通过本地部署,你不仅能够享受到更低的延迟和更高的性能,还能避免将敏感数据暴露在云端,极大提升了安全性和效率。
参考:




























