













学习如何使用 Python 和 yolo-NAS 进行对象检测。YOLO(You Only Look Once,你只看一次)彻底改变了计算机视觉领域。YOLO 的第一个版本由 Joseph Redmon 等人在 2016 年发布,它在速度和准确性方面都打破了基准。在对象检测方面,YOLO 一直是数据科学家和机器学习工程师的最爱,并且当涉及到图像中实体的分割时,它是首选的模型。自从它推出以来,YOLO 经过多次新迭代,改进了以前版本的几个缺点,即:
- 改进了底层深度学习模型的架构。
- 实施了提高性能的替代方案,如数据增强技术。
- 将原始的 YOLO 代码迁移到使用 pytorch 训练和部署框架。
- 改进了小对象的检测机制。
需要意识到的一件重要事情是,每个计算机视觉和对象检测模型都是根据两个参数进行评估的:准确性(由与计算机视觉分割相关的指标定义)和速度(由推理中的延迟定义)。下面展示了如何评估 CV 算法的一个例子:

不同 YOLO 模型与 EfficientDet 的比较 — 图片来源:https://blog.roboflow.com/yolov5-is-here/
在这个例子中,我将向您展示如何在图像和视频上运行自己的 YOLO 模型,以便您可以执行对象检测和分割。
加载模型
我们将从加载大型 YOLO 模型的预训练版本开始。在这种情况下,我们将使用带有 NAS(神经架构搜索)的 YOLO 实现。神经架构搜索是神经网络优化技术的常见实现,以改善深度学习模型中参数的自动选择。我们将使用的模型是在 COCO 数据集(上下文中的常见对象)上训练的。这些权重已经包含了在图像上检测对象的非常好基线。
首先,让我们向我们的环境添加一些我们将需要的库,即:
- torchinfo,一个帮助可视化我们神经网络架构的助手;
- super_gradients,我们将用来加载模型的库。
接下来,我们将加载我们需要的函数和库:
注意:如果您使用的是 Google Colab,并且在安装 super_gradients 后提示重新启动内核,请执行。这是在该环境中使用 super_learners 的已知问题。然后,我们开始使用 super_gradients 将我们的 COCO 预训练模型加载到内存中:
我们已经在 yolo_nas_l 中存储了预训练模型。使用 models 来获取这些预训练版本的 YOLO 是非常容易的。torchinfo 为我们提供了模型架构的非常酷的视图:
出于好奇,如果您想检查 YOLO 架构(来自原始论文),请查看下面的图片:

图片来源:https://www.researchgate.net/publication/329038564_Complexity_and_accuracy_analysis_of_common_artificial_neural_networks_on_pedestrian_detection
这是我们 YOLO NAS 模型架构的预览:
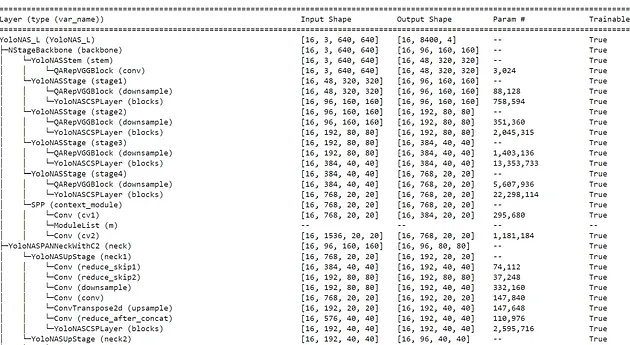
Yolo-NAS 模型架构预览
分割图像
让我们从一张以桌子为中心的简单图像开始,周围有各种物体。在这张图像中,我们可以看到:
- 两把椅子
- 一张桌子
- 两盏灯
- 一台电脑
- 耳机
- 一盆植物

在我们的代码中,我们只请求在模型置信度超过 55% 的地方绘制边界框。只有这些项目的标签才会出现在分割后的图像中。

我们的模型能够自信地检测到椅子、笔记本电脑、桌子和植物(尽管它错过了灯、耳机和那个高科技水壶)。让我们看看如果我们降低我们的置信度阈值会发生什么:

降低我们的阈值导致了我们第一次的误分类。在这种情况下,耳机被错误地识别为计算机鼠标。降低阈值将不可避免地导致更多的对象检测和分割错误。让我们尝试一张更拥挤的场景的图片:

我们的 YOLO 模型将分割哪些对象?由于这张图片有更多的元素,我将降低推理的置信度:

正如我们所看到的,YOLO 未能分割一些对象 — 特别是更小/更细的对象。尽管如此,对于如此拥挤的图像来说,性能相当不错。为了提高一些性能,与您的用例相关的图像的迁移学习非常重要。
在接下来的部分中,我们将学习如何使用 YOLO-NAS,但是在分割视频的背景下。
对于这部分,我将使用 Youtube 上的一个交通短视频:

交通视频 — https://www.youtube.com/watch?v=CftLBPI1Ga4
我们将从下载这个视频到我们的 Google Colab 环境开始。我们还可以使用 IPython 的便捷 YoutubeVideo 功能来显示视频:
要下载我们的视频,我将使用 youtube-dl:
我们只需要设置分割视频的输出路径,就可以将视频通过 YOLO 模型传递了!
一切就绪!让我们运行我们的分割模型:
注意:根据您本地系统的配置和 Google Colab 上 GPU 的可用性,此代码可能需要一些时间来运行。

分割后的交通视频截图
YOLO 模型非常强大!您可以使用它们通过几行代码快速分割图像或视频。使用我在这里展示的代码,您可以非常容易地使用自己的媒体进行实验,并尝试这个伟大的计算机视觉模型。正如您可能注意到的,特别是在复杂的图像或视频中,YOLO 基础模型仍然有一些需要纠正的缺陷。




























