













随着大语⾔模型(LLMs)在各类任务中展现出令人瞩目的能力,如何确保它们⽣成的回复既符合预期又安全,始终是⼀项关键挑战。
传统的偏好对⻬⽅法,如基于⼈类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在⾯对不断变化的数据和需求时,缺乏⾜够的灵活性来适应这些变化。
为了突破这⼀瓶颈,上海人工智能实验室、香港中文大学等联合提出了推理时偏好优化(TPO)方法,通过在推理阶段与奖励模型交互,借助可解释的文本反馈,迭代优化模型输出,实现了即时的模型对⻬,⽽⽆需重新训练。
实验结果表明,TPO能够有效提升未对⻬模型的表现,甚⾄超越经过训练的对⻬模型,为模型偏好对⻬提供了⼀种全新的思路。

△训练时偏好优化VS推理时偏好优化
TPO特点
(1)推理时对⻬、⽆需训练:TPO通过与奖励模型的推理阶段交互,实现即时对⻬偏好,无需更新模型参数。
(2)基于⽂本反馈:TPO使⽤可解释的文本反馈(而非纯数值梯度)来指导优化,让模型“理解ˮ并“执行”文本评价。
(3)优于传统⽅法:在推理阶段,未对⻬的模型(例如Llama-3.1-70B-SFT)经过数次TPO迭代,能够持续逼近奖励模型的偏好。在多个基准测试中,其表现甚至超越了已在训练时对⻬的版本(例如Llama-3.1-70B-Instruct)。
(4)灵活适应性:TPO能够灵活应对不断变化的数据和需求,具有较强的适应性,并且能够在资源有限的环境下⾼效运⾏。
研究方法

为实现这⼀⽬标,已有多种方法用来实现评分函数,如RLHF和DPO通过训练时偏好优化来对⻬⼈类偏好。这些⽅法通过基于梯度的⽅法(如随机梯度下降,SGD)优化模型参数(如神经⽹络中的权重θ),使得⽣成符合⼈类偏好的输出概率更⼤。每次更新的步骤如下:

TPO通过解释和执行文本损失和文本梯度,为模型生成的回复提供可解释的优化信号。
如图所示,TPO包含四个关键组件,类似于标准的梯度优化⽅法:变量定义、损失计算、梯度计算和变量优化。
研究人员使用奖励模型R作为人类偏好的代理,提供生成回复质量的反馈。在推理时对⻬过程中,系统通过迭代调整输出,使其逐步更符合奖励模型的偏好。

△测试时间偏好优化(TPO)框架(AlpacaEval2的真实示例)

该过程最多进行D次迭代,类似于训练过程,称为推理时训练(test-time training)。最终,选择缓存中评分最高的回复作为最终输出。
实验与结果
策略模型
- 未对齐模型:Llama-3.1-70B-SFT
- 已对齐模型:
-Llama-3.1-70B-Instruct
-Llama-3.1-70B-DPO(UltraFeedback训练得来)
奖励模型
- FsfairX-LLaMA3-RM-v0.1
- Llama-3.1-Tulu-3-8B-RM
benchmark与评价指标
- 指令跟随:Alpaca Eval 2(原始胜率WR和长度控制胜率LC)和ArenaHard(胜率WR)
- 偏好对齐:HH-RLHF(采样500条,FsfairX-LLaMA3-RM-v0.1的平均奖励分数)
- 安全:BeaverTails-Evaluation(FsfairX-LLaMA3-RM-v0.1的平均奖励分数)XSTest(WildGuard的准确率)
- 数学能力:MATH-500(使用0-shot配置和CoT提示,pass@1准确率)
推理时训练效果
TPO在推理时对模型进行优化,通过少量的迭代步数逐渐拟合奖励模型偏好,显著提升未对齐模型的性能,使其达到与对齐模型相当的水平;在已对齐模型上,TPO进一步增强了对齐效果,而Revision版本(迭代优化选定回复而不参考被拒绝回复)的提升有限。

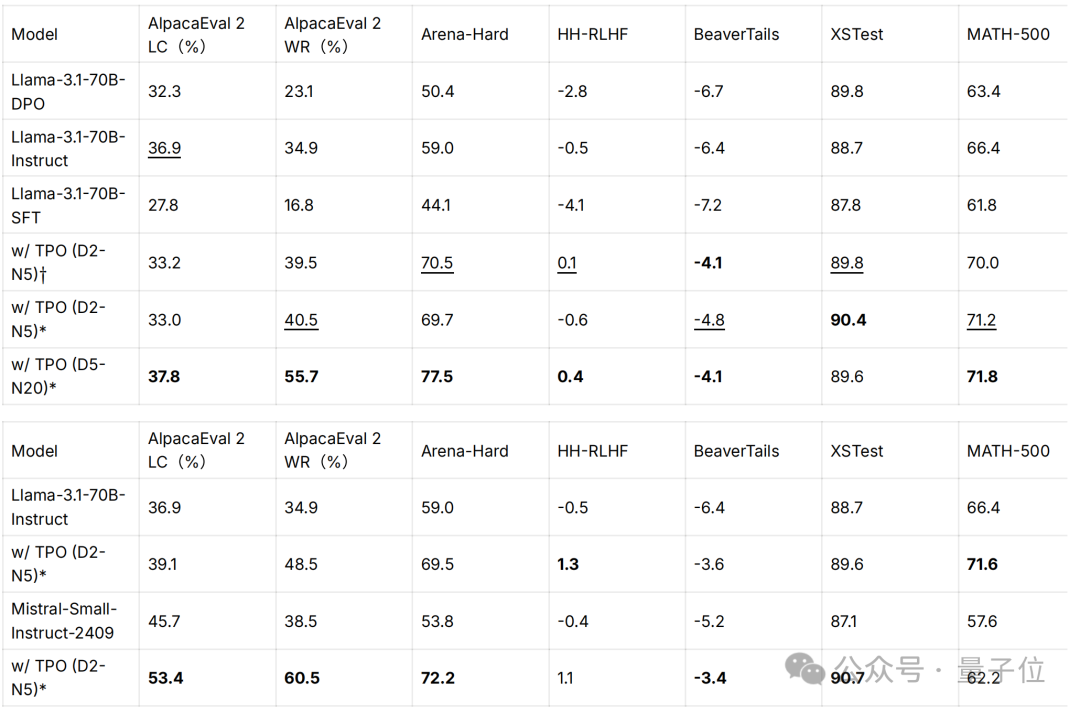
benchmark性能
TPO能够显著提升模型性能指标,未对齐模型通过TPO超越了训练时对齐的模型,而对齐模型在经过TPO迭代后也获得了进一步的优化。D和N分别表示最大迭代次数和样本数量。
* 表示使用奖励模型FsfairX-LLaMA3-RM-v0.1优化的模型,而†表示Llama-3.1-Tulu-3-8B-RM。
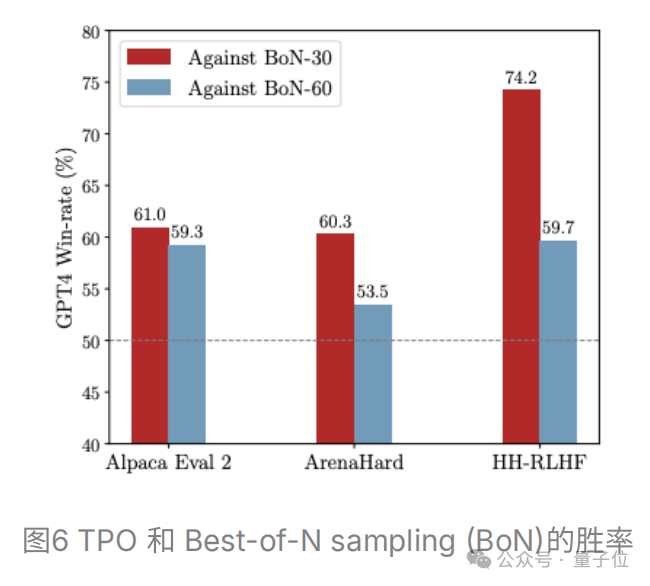
推理稳定性
TPO能够有效地根据奖励模型的反馈调整模型输出,显著改善推理稳定性,表现为采样样本的奖励分数标准差的降低。

TPO的特性分析
TPO的宽度:增加TPO的搜索宽度(即每次TPO迭代中采样的回复数量)能够显著提升性能,直到达到饱和。

TPO的深度:增加TPO的搜索深度比单纯增加样本数量更有效地发现更高质量的回复。
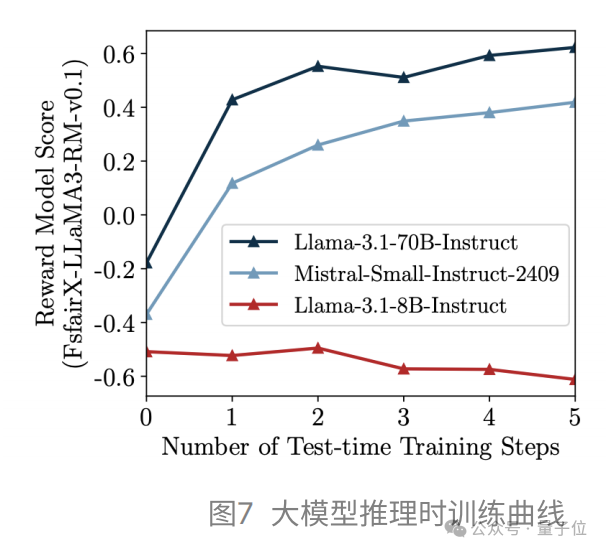
TPO的计算成本:TPO无需更改模型参数,与训练时偏好优化相比,在计算成本上具有显著优势。TPO的计算成本(FLOPs)仅为一轮DPO训练(64,000条数据)所需开销的0.01%。而Instruct模型通常在百万级语料上多轮迭代,训练成本远高于DPO,进一步凸显了TPO在相对计算成本方面的优势。
TPO的指令跟随前提:TPO的成功依赖于策略模型具备基础的指令跟随能力,因为模型必须准确解释和响应数值形式的奖励模型偏好。
总结
提出推理时偏好优化(TPO)方法,通过在推理过程中与奖励模型交互,将奖励模型信号转化为”文本损失”和”文本梯度”,以此迭代优化模型输出。
无需重新训练,即可让大语言模型与人类偏好对齐。TPO为训练时偏好优化提供了轻量、高效且可解释的替代方案,充分利用了大语言模型在推理时的固有能力。
推理时优化的灵活性:TPO通过即时文本反馈实现推理时对⻬,增强了模型在多样化场景中的适应能力,能快速响应变化的需求和任务的变化。此外,TPO充分利用大语言模型在推理、指令跟随等方面的内在优势,从⽽实现了更灵活的偏好对⻬。
未来研究⽅向:未来的研究可聚焦于优化文本交互⽅法,使其能够适应更多专门任务,探索更鲁棒的奖励模型以提升偏好捕捉能⼒,并研究如何提升较弱模型在TPO中的表现,从而进一步拓展其应用场景和优化效果。
论⽂链接:https://arxiv.org/abs/2501.12895
Github链接:https://github.com/yafuly/TPO
Huggingface链接:https://huggingface.co/papers/2501.12895





























