就在今天,谷歌DeepMind的首席执行官Demis Hassabis对DeepSeek进行了一番「捧杀」——
「它可能是中国最好的工作,但没有展示任何新的科学进展。」
Hassabis首先称DeepSeek的模型是「一项令人印象深刻的工作」,然后便一改口风说道:「从技术角度来看,这并不是一个重大变革」,同时还特别强调「炒作有点夸大了」。
「尽管炒作很多,但实际上并没有新的科学突破,它使用的都是已知的AI技术。」
Hassabis同时表示,谷歌本周向所有人开放的Gemini 2.0 Flash模型比DeepMind的模型更加高效。
所以,Hassabis对DeepSeek的种种质疑也就不难理解,DeepSeek事实上已经成为了DeepMind的强劲对手。
马斯克:xAI很快就会发布更好的模型
不只是Hassabis,马斯克也在前几天举行的WELT经济峰会访谈中表达了类似观点。
这次访谈中,当被问道DeepSeek R1是否是AI领域的一次彻底革命时,马斯克明确表示,「不是,xAI和其他一些公司很快就会发布比DeepSeek更好的模型」。

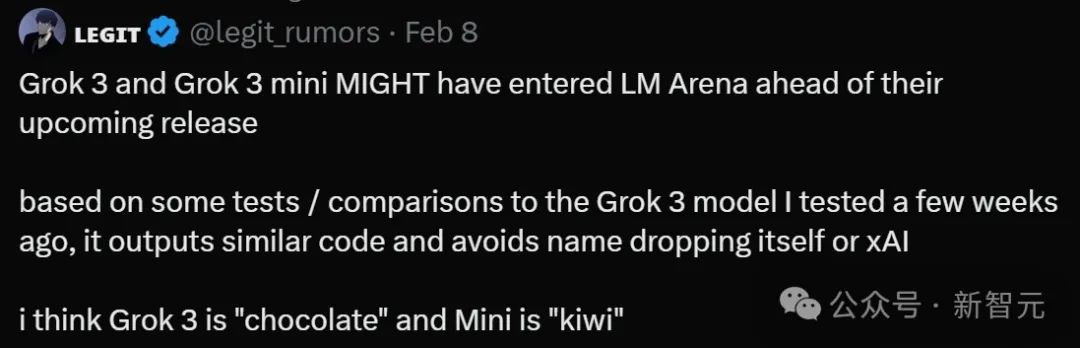
X上已经有网友开始爆料,马斯克所口中的「更好的模型」很可能就是即将发布的Grok 3。
据传新的Grok 3模型在代码和创造力方面比上一代模型要好得多。其中代号为「chocolate」的版本感觉像是完整版,而另一个代号是「kiwi」的版本像是迷你版或者是量化的版本。
马斯克在访谈中还表示,「中国有很多非常聪明、非常有驱动力的工程师。你应该预料到中国会创造出许多伟大的东西,而且他们已经创造出了许多伟大的东西。」
他强调,在人类历史的大部分时间里,中国一直是世界上最强大的国家。
在谈到AI的开源问题时,马斯克认为,开源模型通常落后于商业模型。但他同时强调,今天商业上强大的模型,可能再过一年或更短的时间内就会开源。「我预计这种趋势会持续下去。所以,基本上每个人都将拥有AI。」
马斯克已经为Grok 3造势好长一段时间了,所以此次对DeepSeek的点评,也不排除是继续为Grok 3造势。
Anthropic CEO长篇檄文:DeepSeek缺乏研究价值
不过,要说对DeepSeek恶意最大的,还要属在春节期间发出「万字檄文」的Anthropic CEO Dario Amodei。

在他看来,根据历史趋势,LLM的成本每年都会下降约4倍,这意味着现在应该有比GPT-4/Claude 3.5便宜3-4倍的模型出现。
相比之下,DeepSeek-V3的性能比目前的美国顶级模型低约2倍,训练成本比一年前的美国模型低约8倍,这符合行业正常发展预期。
因此,DeepSeek-V3并不构成根本性突破或创新。还不如Claude 3.5对GPT-4实现的10倍价格差。
DeepSeek-R1的研究价值甚至连V3都不如——增加的第二阶段训练(强化学习),仅仅是对OpenAI在o1的复制。
Amodei表示,由于我们仍处于模型「扩展曲线」的早期,所以只要以一个强大的预训练模型为基础,很多公司都有可能开发出这类模型。
AGI五年内可期
作为这段时间AI圈顶级大佬们的「例行项目」,Hassabis也对AGI何时到来做了预测。
他表示,AI行业「正在通向AGI的道路上前进」,他将其描述为「一个具备人类所有认知能力的系统」。
「我认为我们现在已经很接近了,也许我们只需要大约5年就能实现这样一个系统,这将是非常非凡的」,Hassabis说。
「我认为社会需要为此做好准备,思考这将带来什么影响。我们要确保能从中获益,让整个社会都能从中受益,但同时也要减轻相关风险。」
Hassabis的评论与业内其他人的观点相呼应,他们也暗示AGI可能离现实更近了。
OpenAI的CEOSam Altman今年就表示,他「相信我们知道如何构建我们传统理解中的AGI」。
不过,业内许多人也指出了与AGI相关的多重风险;最大的担忧之一是人类将失去对他们创造的系统的控制,著名AI科学家Max Tegmark和Yoshua Bengio最近在接受CNBC采访时也表达了他们对这种形式AI的担忧。
结语
DeepSeek的横空出世,无疑在全球AI领域掀起了一场风暴。不仅在国内一直霸榜,现在全球的大佬也都将目光关注于此。
在未来,随着各大科技巨头的持续投入与竞争,AI领域的格局将愈发复杂多变,而AGI的到来或许也将比我们想象的更近。