在现代电商和在线服务行业,订单系统需要承受极高的并发压力。面对日均百万级订单的增长,传统的单库单表模式已经难以支撑业务需求。随着数据规模的持续扩大,查询延迟增加,数据库写入瓶颈显现,直接影响用户体验和系统稳定性。
为了保障系统的高性能和可扩展性,分库分表已成为解决数据库瓶颈的核心策略。通过科学的分库分表设计,可以有效降低单库负载,提升查询和写入效率,使系统能够轻松应对未来数年的业务增长。本文将深入探讨如何借助分库分表方案,在Spring Boot 3.4环境下构建高可用、高并发的订单处理系统。
为什么需要分库分表?
随着订单数据的不断积累,单一数据库承载的数据量逐渐增大,系统的查询、插入、更新等操作的性能大幅下降,最终可能导致数据库无法支撑业务需求。主要问题包括:
- 查询性能下降索引变大,查询扫描的数据量增加,影响用户体验。
- 写入吞吐受限数据库单表写入能力有限,导致订单存储延迟。
- 备份与恢复困难数据量过大会增加数据库维护的难度。
通过合理的分库分表策略,可以将订单数据分散存储,有效缓解数据库的压力,提高查询效率和系统扩展能力。
分库策略
- 按业务模块划分如订单数据与用户数据分别存储在不同的数据库中。
- 按时间分库依据年月建立独立数据库,例如 orders_2023、orders_2024,便于管理与归档。
分表策略
- 按ID范围分表依据主键ID取模,均匀分配数据至不同表。
- 按时间分表例如 orders_2025_01 专用于存储2025年1月订单。
- 复合分表策略结合时间维度与ID范围进行分表。
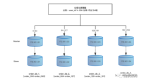
数据库实例设计
为了提高系统吞吐量,通常会部署多个数据库实例。例如,3台数据库服务器,每台运行一个订单数据库(如 db_order_01、db_order_02),各数据库中存在相同结构的订单表(如 tb_order)。
数据路由策略
- 数据库中间件利用 ShardingSphere-JDBC 或 Mycat 自动分发数据。
- 动态路由策略根据订单ID计算哈希值,均匀分布到不同数据库与表。
示例代码(基于Spring Boot 3.4,使用 com.icoderoad 包)
读写分离
为进一步优化性能,采用 主从架构 可降低主库负载:
- 主库(Master)处理写入请求。
- 从库(Slave)处理读取请求。
- 数据同步主库的数据自动同步至从库,确保一致性。
性能优化方案
- 监控与调优定期分析数据库性能指标,动态调整分库分表策略。
- 动态扩展设计方案需支持数据库及表的扩展,以应对未来业务增长。
结论
面对百万级订单并发的挑战,传统的单库架构已无法满足高效、低延迟的业务需求。通过分库分表技术,可以大幅提升数据库的吞吐能力,有效降低单表数据量,提高查询速度,同时增强系统的可扩展性。
在实际应用中,结合数据库中间件(如 ShardingSphere-JDBC)进行数据路由,利用主从库读写分离技术进一步优化性能,可以确保系统在订单量增长10倍甚至100倍的情况下依旧稳定运行。对于未来的电商业务增长,合理的分库分表方案不仅提升了系统的可维护性,也为高并发场景下的数据库架构提供了坚实的支撑。