哈喽大家好啊,我是Hydra。
最近刷某音的时候,总是动不动就给我推一个类型的直播间,标题都差不多,类似于“1分钟教你本地部署DeepSeek满血版”什么的,头像清一色的蓝色小鲸鱼,就很耽误我看小姐姐跳舞。
前几次的时候,我还耐着性子看了几分钟,后来基本上看见了就拉黑划走,首先是因为他们讲的内容高度雷同,都是部署Ollama、ChatBox、CherryStudio这些东西,内容相似到我甚至怀疑他们是同一个割韭菜培训班培训出来的。其次就是讲的东西真没什么用, 稍微了解一些大模型的都明白,按他们这样部署完了,你顶多也就当个玩具玩玩。
为什么呢,听我给你分析分析,听完之后,答应我别看这些直播浪费时间了好吗?
首先,大家都知道,运行大模型是需要算力的,这个算力通常由GPU提供。注意我说的是"通常",因为还有NPU、TPU等设备也能提供算力,但是平常使用的电脑一般并没有配备,所以暂不讨论。在本地部署大模型之前,你首先需要评估一下你的电脑配置,明确两件事情:
我的电脑能不能跑起来大模型、能跑起来多大参数量的模型?
如果你的电脑没有GPU或者使用的是集显,这种情况下,建议你部署个1.5B的模型尝一下鲜就可以了,即使纯CPU跑个推理也没什么问题,速度也勉强说的过去。
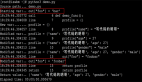
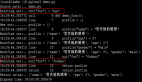
但是如果你想部署7B以上的模型,没有GPU的话还是算了,只用CPU推理的话token输出速度非常感人。我在16核64G内存的CPU的服务器上做了个测试,可以感受一下这个速度:
 图片
图片
那么模型的参数规模和性能有什么具体的关联呢?一般来说,参数规模越大,大模型推理时就拥有更高的准确性和泛化能力,处理问题的表现也更加出色。但是同时,运行所需要的显存资源更高,推理时间可能更长。
在计算大模型推理需要的显存时,需要考虑的不光是模型基础占用显存,还需要考虑KV cache、激活值占用显存,以及一些其他的开销等。
我看了看那些直播间里列出的显存估算表格,但是基本上都是只考虑了最低模型基础占用显存,这一块可以使用公式计算:
其中,P是模型的参数量(单位是亿),Q是加载模型使用的位数。那么以DeepSeek-R1-Distill-Qwen-7B为例,它的参数规模是7B,模型精度为BF16,那么加载它使用的基础显存就需要:
也就是,要运行起来模型,最少需要13.04GB的显存。
除了模型基础显存外,上下文长度也是个显存刺客,离开上下文长度谈显存使用就是耍流氓,这里使用工具对比一下不同上下文长度进行推理时占用的显存:
 图片
图片
所以说,如果在显存有限的情况下,还需要额外对上下文长度进行一定控制。群里大佬发了一张图,给出了DeepSeek-R1在稳定运行情况下,各个模型的显存需求。
 图片
图片
至于这个表上为什么R1的规模是685B,是因为额外加了14B的MTP模块的参数,使R1能够在推理阶段一次生成多个token。并且,这张表中R1还是进行了FP8量化或INT4量化的情况,如果直接运行BF16精度需要的显存更高,估计至少也需要双节点的8卡H100才能部署成功。
所以说,我的建议是如果你的电脑GPU配置不足,与其花费时间捣鼓部署,真不如去SiliconFlow上直接调用API,1.5B、7B、8B的R1蒸馏模型的API都是免费调用,难道不香吗?
其次,我觉得Ollama这个东西是有些鸡肋的,它的优点是安装确实很简单,运行模型也容易。但是说直接点,Ollama就是个玩具,根本不可能拿到生产环境使用,原因很简单,它有一个最致命的问题,并发处理能力有限。
相比之下,vLLM在这方面就做的好的多。简单来说,vLLM是一个高性能的大模型推理引擎,它通过 Paged Attention 技术高效管理KV cache,实现了比 transformers 高14-24倍的吞吐量,所以我们在选推理框架的时候,首先会看它支不支持vllm。
所以个人推荐的是,使用Xinference这一推理框架来代替Ollama,它支持的推理引擎非常多,包括了transformers 、vLLM、Llama.cpp、SGLang、MLX,并且支持多卡部署、多副本部署,在实用性上真的比Ollama要强上很多,而且部署也非常简单。
最后,其实本地部署的小规模的模型能力还是比较有限的,例如7B模型有时候会出现输出的token中英文混杂的情况,并且对 Function Call 的支持也不是很好。在配置有限的情况下,本地部署的小规模模型和官方满血版提供的能力差距还是挺大的,不过归根结底,咱们部署的小规模模型在本质上其实不是DeepSeek-R1,看一下官方仓库,可以看到这几个单词:DeepSeek-R1-Distill Models。
复习一下 distill 这个单词,六级词汇,蒸馏的意思。
所以说,这个列表里从1.5B到70B的模型都是蒸馏模型,是用最简易的方法使R1的结果能在小模型上复现,将R1的推理能力迁移至小规模模型。
 图片
图片
拿DeepSeek-R1-Distill-Qwen-7B 这个模型举例,它就是基于Qwen2.5-Math-7B这个模型蒸馏出来的,通过这一过程,验证了较大模型的推理能力的可迁移性。但是归根结底,测试过程中还是存在各种各样的问题,后续还需要做各种的适配工作。
在这个算法狂欢的时代,技术祛魅或许比盲目追新更重要,当我们刷着满屏的"本地部署"教程时,不妨先看清它们背后的真相,虽然看似充满了诱惑,但实际上却缺乏深度和实用性,这些内容往往只是在重复一些基础的操作,却忽略了运行大模型背后真正需要考虑的因素。
所以,下次看到类似的直播间时,不妨停下来思考一下,这些内容是否真的对你有价值,当你划走时,失去的不是通向人工智能的捷径,而是一张名为"技术智商税"的入场券。