在编程的广袤领域中,集合是一个至关重要的概念,它犹如数据的魔法盒子,承载着各种元素的有序或无序组合。而集合工具类,则像是一把神奇的钥匙,为我们开启了高效处理和操作这些集合的大门。

一、详解Java集合常用的方法
1. 集合判空
日常业务功能开发,为保证程序的健壮性,判空操作是必不可少的,笔者在日常审查代码时候会看到很多开发会使用size方法进行判空,这种方案在常规集合容器下没有任何问题,但是在某些特殊场景下,这个判空就可能存在性能问题:
最典型的就是ConcurrentLinkedQueue,打开其内部源码即可看到,该容器获取元素数时是从头节点开始遍历获取的:
所以一般情况下,我们更建议使用isEmpty,该方法无论从语义还是实现上,都避免了扫描容器的开销,是笔者比较推荐的一种判空方式:
2. 列表集合转Map
集合转Map时可以直接使用java8版本的流编程,对应代码示例如下:
对应的我们也给出输出结果:
需要注意一点,我们使用的时候尽可能保证value非空,要知道toMap底层用到了HashMap的方法,该方法中如果判断value为空会抛出空指针异常:
3. 集合遍历时移除元素(重点)
不建议使用for循环等方式进行remove,会抛出ConcurrentModificationException ,这就是单线程状态下产生的 fail-fast 机制。
fail-fast 机制,即快速失败机制,是java集合(Collection)中的一种错误检测机制。当在迭代集合的过程中该集合在结构上发生改变的时候,就有可能会发生fail-fast,即抛出ConcurrentModificationException异常。fail-fast机制并不保证在不同步的修改下一定会抛出异常,它只是尽最大努力去抛出,所以这种机制一般仅用于检测bug。
所以我们建议jdk8情况下使用这种方式进行动态移除,即使用removeIf方法,该方法已经为我们做好了封装无论从使用还是语义上,这种写法更加友好:
这一点,我们从底层的源码就可以知道,它为我们做好了:
- 获取迭代器
- 遍历元素
- 基于迭代器安全删除元素
对应我们给出这段源码实现,该代码位于Collection下:
4. 集合去重
集合去重可以利用 Set 元素唯一的特性且通过O(1)级别的元素定位,可以快速对一个集合进行去重操作,避免使用 List 的 contains() 进行扫描元素的性能开销:

如下代码所示,list去重需要调用contains,要遍历数组,而set底层用hash计算,如果散列良好情况下判重只需要O(1)
对应我们也给出输出结果来比对一下两个集合之间的性能差异:
5. 集合转数组
使用集合转数组的方法,一般使用的是集合的 toArray(T[] array)这个方法,我们只需传入数组首元素引用地址即可:
这一点我们查看Arrays的toArray实现详情就知道,该方法会获取当前需要转为数组的列表大小,然后从列表首元素地址开始将元素我们传入的数组引用空间中:
6. 数组转集合
使用工具类 Arrays.asList() 把数组转换成集合时,转成的集合是Arrays工具类内部的ArrayList:
需要注意的是AbstractList不能使用其修改集合相关的方法,它是一个只读的容器, 它并没有重写 add/remove/clear 方法,所以会抛出 UnsupportedOperationException 异常,这一点我们查看AbstractList源码即可知晓这一点:
二、详解Java集合工具类
1. 常见集合排序操作API
Java内置了很多使用的集合操作的api,这里我们不妨列一下方法清单,读者可以基于注释熟悉一下这些API的使用:
2. 集合排序
升序排序我们只需将列表传入sort方法,其底层排序的工作机制稍微会做介绍,这里我们先熟悉一下使用方法:
对应的输出结果如下:
sort方法同样是支持倒叙的排序的,对应的我们给出倒叙的比较器作为参数即可:
对应的我们也给出输出结果:
3. 列表翻转
reverse方法就是将我们元素内部按照倒叙反转一下,对应我们给出代码示例:
可以看到,翻转后的数值按照列表倒叙进行排列了:
4. 列表随机排列
shuffle顾名思义即洗牌的意思,它会将列表内部元素顺序打乱
输出结果:
5. 列表整体移动
rotate算是比较少用的api,读者可以简单了解一下,这个方法会将列表中所有元素斗向前移动,对于列表末尾的元素会移动到列表首部,具体算法笔者会在后面的源码讲解进行分析,这里我们了解一下其使用效果:
输出结果:
6. 两数交换
swap可以指定两数索引位置元素交换,如下代码,我们将索引0和索引1位置的元素进行交换:
对应输出结果如下:
三、详解Java集合工具类算法底层实现
1. Collections.sort底层实现
查看sort方法底层实现可以看出,除非开发显式配置归并排序才会调用legacyMergeSort进行归并排序,否则一律使用TimSort进行列表排序:
而TimSort的sort方法就是排序核心的实现,TimSort是自适应的、混合的、稳定的排序算法。是基于归并和二分插入排序优点结合的排序算法。复杂度最坏的情况下只有O(nlogn),最坏的情况下,空间复杂度为O(n/2)。
这个方法在基数阈值的选取和排序的实现细节都做了机制都做了相对极致的优化,当列表元素小于32的情况下,TimSort会直接通过二分插入排序直接完成排序操作。
二分插入排序法是插入排序法的升级版本,如下所示,我们都知道插入排序后左边的元素都是有序的,如果使用常规二分排序,那么最坏情况下插入时间是O(n),所以我们基于左边有序这个特点改用二分插入的方式完成排序优化了这个问题。
当右边元素进行插入时,不断在左边进行二分运算定位到mid元素:
- 如果mid索引对应的元素小于插入元素,说明left索引元素值太小,需要向右移动找到下一个折中值。
- 如果mid索引元素值大于待插入的元素值,说明right坐标对应的元素值太大,需要让right坐标向左移动找到小一点的中间值。
通过这样的二分运算最终会找到一个小于或者等于待入元素坐标left作为插入索引并将元素插入,然后其余元素全部向后移动一位:

对此我们也给出TimSort排序的前半部分实现,可以看到这段代码在进行二分排序前会先定位开头有序的最小区间initRunLen ,如下图所示,这个数组索引3之前的元素都是正向元素的,所以排序是从索引4开始:

对应的我们也给出这段代码的整体实现:
countRunAndMakeAscending代码的实现,该方法本质上就是从头开始比对元素:
- 如果一开始runHi 元素大于其后一个元素,则正序方式先前遍历,runHi 不断前行,找到正向有序的最小区间。
- 如果一开始runHi 元素小于后一个元素,则按照倒叙方式进行编译,runHi 不断前行,找到逆序的最小区间。
然后我们再介绍binarySort,如上文所说不断通过二分运算比对mid和插入元素的值,然后进行插入,这里笔者特殊说明一下binarySort对于二分插入排序的优化细节,从代码中可以看到,当二分插入排序定位到合适的位置之后,会判断这个位置和插入元素之间的距离,如果两者距离小于2,则直接通过简单的元素交换:

反之,如果待插入的位置和插入元素索引位置大于2,则找到left及其前方元素批量先前移动一格,然后腾出一块空间将元素插入:

对应的我们给出binarySort的代码实现细节:
当元素大于32的时候,TimSort排序算法就会进行更近一步的设计,即针对当前数组生成无数个子单元进行二分插入排序,然后基于每个有序的子单元进行归并从而得到不断归并得到一个有序集合:

对应的我们给出TimSort后续代码,整体逻辑与笔者说明一致,建议读者结合笔者说明和注释理解:
由于这篇文章主要描述Java集合工具类的使用,所以就不展开细讲了。
2. rotate列表旋转算法的实现
rotate旋转算法底层也有很多的巧妙设计,步入其源码可以看到:
- 如果是RandomAccess即具备随机访问特性的数组或者数组大小小于100时使用rotate1方法进行旋转
- 反之说明该列表是不具备随机范文的链表则调用rotate2进行元素旋转
对应的我们给出代码的顶层实现:
我们先来说说rotate1方法的实现,逻辑比较简单,计算出移动的步数之后通过list的set方法将元素设置到移动的位置上,通过set方法得到该位置上原有的元素,再将该元素移动到旋转后的的索引上:

对应的我们给出这段实现的源码,读者可结合说明了解核心流程:
走到rotate2这个函数则说明这个数组为不具备随机访问性的链表,为了保证性能,该方法会通过计算的方式得到计算出一个批量移动的区间,然后基于这两个整体进行批量的移动。
例如我们现在有一个链表,内部包含0-100一共101个元素,元素值为0~100,刚刚好可以执行rotate2方法,假设我们希望全体向前移动一步,rotate2算法会通过-distance % size得到100,即[0,100]区间是只需先前移动的区间,而[101]是需要移动到列表前面的区间,rotate2的执行步骤为:
- 将区间1翻转,得到99~0。
- 将区间2翻转,得到100,此时列表排列为99~0、100。
- 最后将整个列表进行一次翻转,将100移动到列表最前面的同时,也将只需先前移动一格的区间放到100的后面:
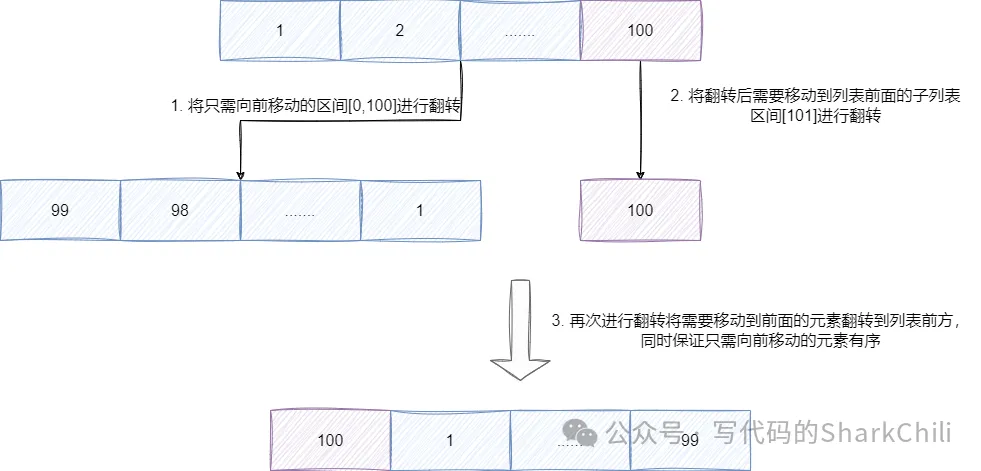
对应的我们也给出rotate2的代码实现,整体思路和笔者说明的一致,就是通过-distance % size计算得到只需先前移动和要翻转到列表前面的两个区间,然后执行:
- 只需向前移动的区间1翻转。
- 移动到列表首部的区间2翻转。
- 整个列表翻转将区间2提前。
四、详解jdk常见搜索比对函数
1. 核心api概览
jdk也为我提供了很多使用的搜索和比较统计函数,对应的函数列表如下:
2. 使用示例
3. 详解洗牌算法
这里我们着重说明一下随机洗牌算法的实现,逻辑比较简单:
- 如果列表具备随机访问或者size小于100,可以直接从size开始倒叙调用swap进行随机元素交换。
- 反之说明当前列表是大于100的链表,首先将这些元素存到一个具备随机访问的数组中,然后基于这个数组进行随机swap交换,再存入链表中,所以性能表现会差一些。
对应的源码如下:
五、同步控制
1. 同步控制常见函数
注意,非必要不要使用这种API,效率极低
2. 使用示例
可以看到笔者在下面贴出使用Collections.synchronizedList包装后的list的add方法,锁的粒度很大,在多线程操作情况下,性能非常差。
我们就以synchronizedList为例查看其add方法,可以看到其实现线程安全的方式很简单,直接在工作代码上synchronized ,在高并发情况下,很可能造成大量线程阻塞
示例代码如下,我们分别开两个线程,往数组中添加1000个数组,可以看到笔者注释代码中用了普通list,以及通过Collections.synchronizedList后的list,感兴趣的读者可以基于下面代码测试是否线程安全
输出结果为2000,说明该方法确实实现了线程安全