传统上,AI研究被划分为不同的领域:自然语言处理(NLP)、计算机视觉(CV)、机器人学、人机交互(HCI)等。然而,无数实际任务需要整合这些不同的研究领域,例如自动驾驶汽车(CV + 机器人学)、AI代理(NLP + CV + HCI)、个性化学习(NLP + HCI)等。
尽管这些领域旨在解决不同的问题并处理不同的数据类型,但它们都共享一个基本过程。即生成现实世界现象的有用数值表示。
历史上,这是手工完成的。这意味着研究人员和从业者会利用他们(或其他人)的专业知识,将数据显式转换为更有用的形式。然而,今天,这些可以通过另一种方式获得。在本文中,我将讨论多模态embeddings,并通过两个实际用例分享它们的功能。

Embeddings
embeddings是通过模型训练隐式学习的数据的有用数值表示。例如,通过学习如何预测文本,BERT学习了文本的表示,这些表示对许多NLP任务很有帮助[1]。另一个例子是Vision Transformer(ViT),它在Image Net上进行图像分类训练,可以重新用于其他应用[2]。
这里的一个关键点是,这些学习到的embeddings空间将具有一些底层结构,使得相似的概念彼此接近。如下面的玩具示例所示。

文本和图像embeddings的表示
前面提到的模型的一个关键限制是它们仅限于单一数据模态,例如文本或图像。这阻止了跨模态应用,如图像字幕生成、内容审核、图像搜索等。但如果我们可以合并这两种表示呢?
多模态 Embeddings
尽管文本和图像在我们看来可能非常不同,但在神经网络中,它们通过相同的数学对象(即向量)表示。因此,原则上,文本、图像或任何其他数据模态都可以由单个模型处理。
这一事实是多模态embeddings的基础,它将多个数据模态表示在同一向量空间中,使得相似的概念位于相近的位置(独立于它们的原始表示)。
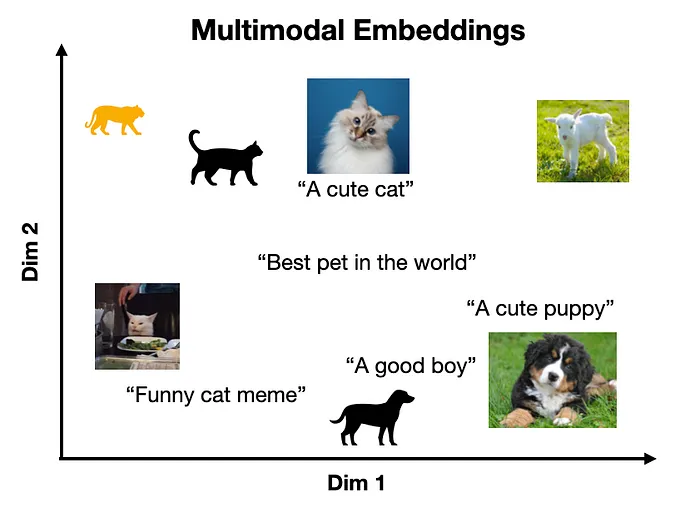
多模态embeddings空间的表示
例如,CLIP将文本和图像编码到共享的embeddings空间中[3]。CLIP的一个关键见解是,通过对齐文本和图像表示,模型能够在任意一组目标类上进行零样本图像分类,因为任何输入文本都可以被视为类标签(我们将在后面看到一个具体示例)。
然而,这个想法不仅限于文本和图像。几乎任何数据模态都可以以这种方式对齐,例如文本-音频、音频-图像、文本-脑电图、图像-表格和文本-视频。这解锁了视频字幕生成、高级OCR、音频转录、视频搜索和脑电图到文本等用例[4]。
对比学习
对齐不同embeddings空间的标准方法是对比学习(CL)。CL的一个关键直觉是相似地表示相同信息的不同视图[5]。
这包括学习表示,以最大化正对之间的相似性并最小化负对的相似性。在图像-文本模型的情况下,正对可能是带有适当标题的图像,而负对可能是带有不相关标题的图像(如下所示)。

对比训练中使用的正对和负对示例
CL的两个关键方面促成了其有效性:
- 由于正对和负对可以从数据的固有结构(例如,网络图像的元数据)中策划,CL训练数据不需要手动标记,这解锁了更大规模的训练和更强大的表示[3]。
- 它通过特殊的损失函数同时最大化正对和最小化负对的相似性,如CLIP所示[3]。
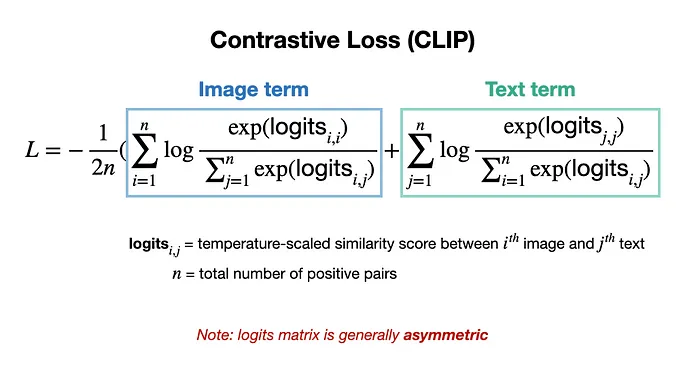
CLIP用于文本-图像表示对齐的对比损失[3]
示例代码:使用CLIP进行零样本分类和图像搜索
在了解了多模态embeddings的工作原理后,让我们看看它们可以做的两个具体示例。在这里,我将使用开源的CLIP模型执行两个任务:零样本图像分类和图像搜索。
这些示例的代码在GitHub仓库中免费提供:https://github.com/ShawhinT/YouTube-Blog/tree/main/multimodal-ai/2-mm-embeddings。
用例1:零样本图像分类
使用CLIP进行零样本图像分类的基本思想是将图像与一组可能的类标签一起传递给模型。然后,通过评估哪个文本输入与输入图像最相似来进行分类。
我们首先导入Hugging Face Transformers库,以便可以在本地下载CLIP模型。此外,PIL库用于在Python中加载图像。
from transformers import CLIPProcessor, CLIPModel
from PIL import Image接下来,我们可以导入一个版本的clip模型及其相关的数据处理器。注意:处理器处理输入文本的标记化和图像准备。
# import model
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
# import processor (handles text tokenization and image preprocessing)
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")我们加载下面的猫的图像,并创建两个可能的类标签列表:“一张猫的照片”或“一张狗的照片”。
# load image
image = Image.open("images/cat_cute.png")
# define text classes
text_classes = ["a photo of a cat", "a photo of a dog"]
输入的猫照片
接下来,我们将预处理图像/文本输入并将它们传递给模型。
# pass image and text classes to processor
inputs = processor(text=text_classes, images=image, return_tensors="pt",
padding=True)
# pass inputs to CLIP
outputs = model(**inputs) # note: "**" unpacks dictionary items要进行类预测,我们必须提取图像logits并评估哪个类对应于最大值。
# image-text similarity score
logits_per_image = outputs.logits_per_image
# convert scores to probs via softmax
probs = logits_per_image.softmax(dim=1)
# print prediction
predicted_class = text_classes[probs.argmax()]
print(predicted_class, "| Probability = ",
round(float(probs[0][probs.argmax()]),4))>> a photo of a cat | Probability = 0.9979模型以99.79%的概率准确识别出这是一张猫的照片。然而,这是一个非常简单的例子。让我们看看当我们将类标签更改为:“丑猫”和“可爱猫”时会发生什么。
>> cute cat | Probability = 0.9703模型轻松识别出图像确实是一只可爱的猫。让我们做一些更具挑战性的标签,例如:“猫表情包”或“非猫表情包”。
>> not cat meme | Probability = 0.5464虽然模型对这个预测的信心较低,只有54.64%的概率,但它正确地暗示了图像不是表情包。
用例2:图像搜索
CLIP的另一个应用基本上是用例1的逆过程。与其识别哪个文本标签与输入图像匹配,我们可以评估哪个图像(在一组中)与文本输入(即查询)最匹配——换句话说,在图像上执行搜索。我们首先将一组图像存储在列表中。在这里,我有三张猫、狗和山羊的图像。
# create list of images to search over
image_name_list = ["images/cat_cute.png", "images/dog.png", "images/goat.png"]
image_list = []
for image_name in image_name_list:
image_list.append(Image.open(image_name))接下来,我们可以定义一个查询,如“一只可爱的狗”,并将其与图像一起传递给CLIP。
# define a query
query = "a cute dog"
# pass images and query to CLIP
inputs = processor(text=query, images=image_list, return_tensors="pt",
padding=True)然后,我们可以通过提取文本logits并评估对应于最大值的图像来将最佳图像与输入文本匹配。
# compute logits and probabilities
outputs = model(**inputs)
logits_per_text = outputs.logits_per_text
probs = logits_per_text.softmax(dim=1)
# print best match
best_match = image_list[probs.argmax()]
prob_match = round(float(probs[0][probs.argmax()]),4)
print("Match probability: ",prob_match)
display(best_match)>> Match probability: 0.9817
查询“一只可爱的狗”的最佳匹配
我们看到(再次)模型在这个简单示例中表现出色。但让我们尝试一些更棘手的例子。
query = "something cute but metal 🤘">> Match probability: 0.7715
查询“可爱但金属的东西🤘”的最佳匹配
query = "a good boy">> Match probability: 0.8248
查询“一个好男孩”的最佳匹配
query = "the best pet in the world">> Match probability: 0.5664
查询“世界上最好的宠物”的最佳匹配
尽管最后一个预测颇具争议,但所有其他匹配都非常准确。这可能是因为像这样的图像在互联网上无处不在,因此在CLIP的预训练中被多次看到。
接下来可以做什么?
多模态embeddings解锁了涉及多个数据模态的无数AI用例。在这里,我们看到了两个这样的用例,即使用CLIP进行零样本图像分类和图像搜索。像CLIP这样的模型的另一个实际应用是多模态RAG,它包括自动检索多模态上下文到LLM。在本系列的下一篇文章中,我们将了解其内部工作原理并回顾一个具体示例。
【参考文献】
- [1] BERT:https://arxiv.org/abs/1810.04805
- [2] ViT:https://arxiv.org/abs/2010.11929
- [3] CLIP:https://arxiv.org/abs/2103.00020
- [4] Thought2Text: 使用大型语言模型(LLMs)从脑电图信号生成文本:https://arxiv.org/abs/2410.07507
- [5] 对比学习视觉表示的简单框架:https://arxiv.org/abs/2002.05709