












一则非常重要的消息:除了已有的视频生成功能,OpenAI 似乎还在为 Sora 推出图像生成功能做准备。
OpenAI 正在内部测试这些图像生成功能:包括一个新的隐藏切换按钮,能允许用户在提示栏中直接在视频和图像生成之间切换。如果切换到图像,提示栏的描述会提示你描述一幅图像。
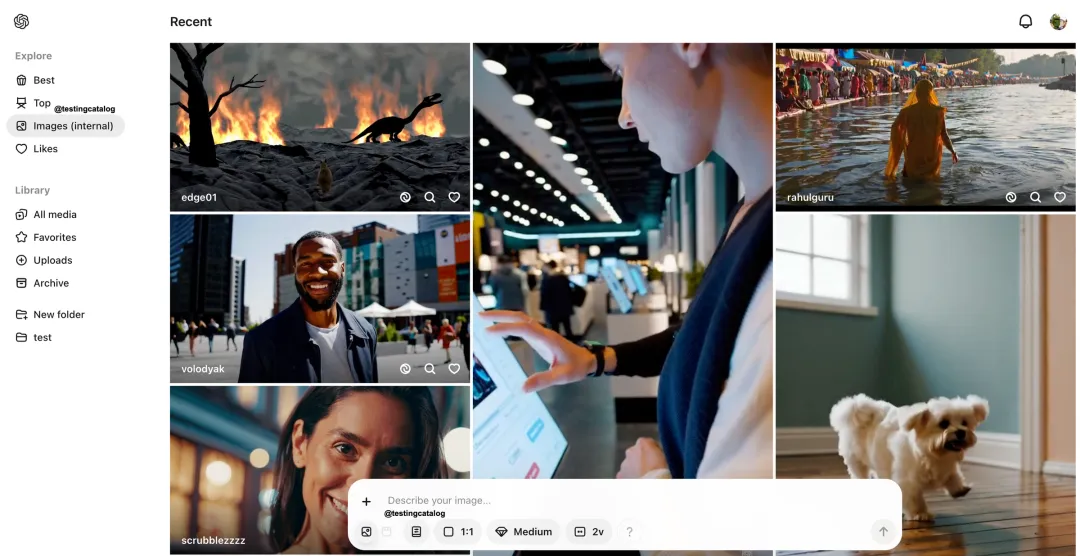
OpenAI 还对 Sora 的视频推送进行了改版,将其分为「Best」和「Top」两个类别。「Best」很可能与目前的特色频道类似。不过,「Top」类别可能允许按某个时间段进行筛选,并可能根据点赞数或其他标准对视频进行排名。
OpenAI 的这个动作让很多人重新兴奋起来,因为现有的 DALL-E 3 已经非常过时了 —— 至少和 Midjourney 比起来是这样。

该功能目前还未投入使用,但左侧导航栏上还有一个「Images Internal」类别。目前,它打开的是视频推送。不过,将来用户也有可能在这里找到图片推送。目前还不清楚 OpenAI 将添加何种图像生成功能,也不清楚将由哪款模型提供。
有人猜测我们可能会「在某个时候看到 DALL-E 4」,但 OpenAI 官方没有对此进行确认。
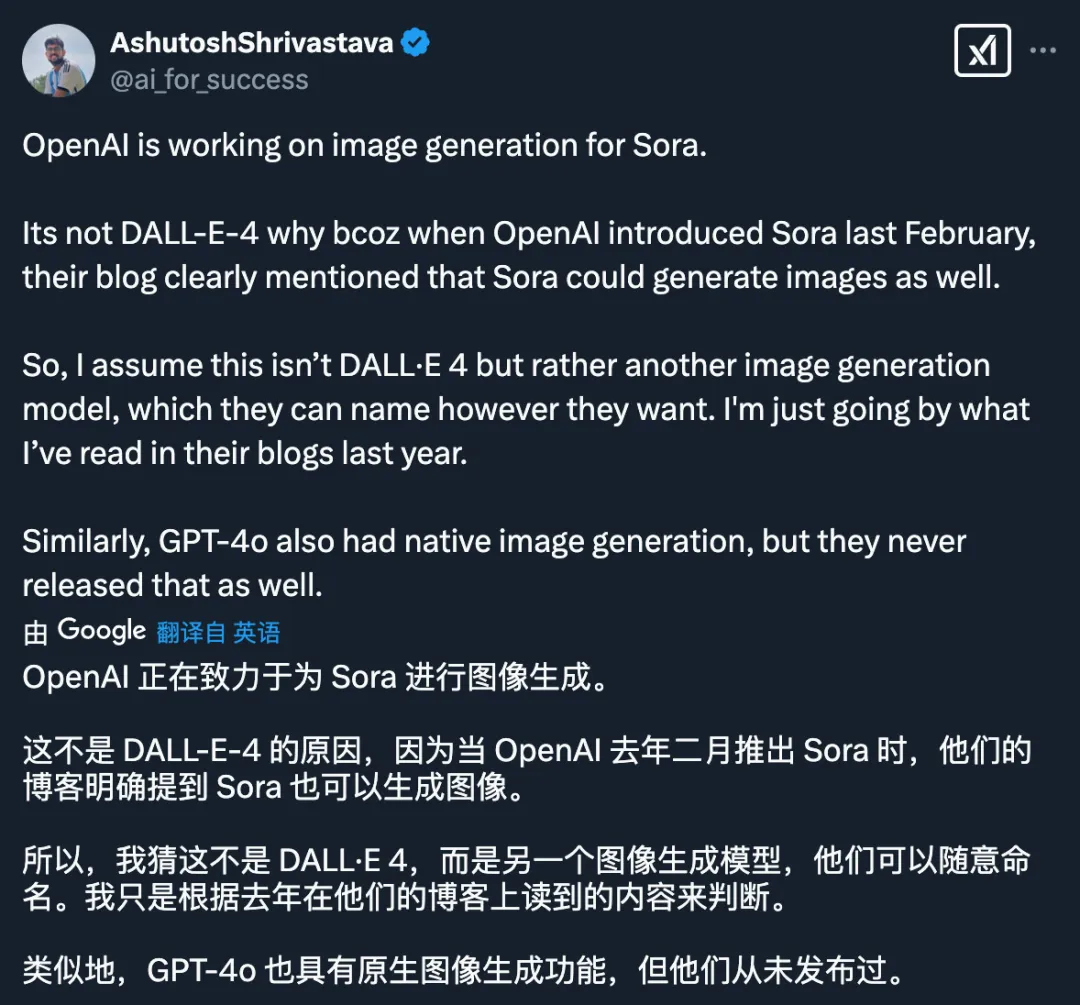
但 Sora 中的图像生成模型应该不是 DALL-E 4。OpenAI 在去年首次发布 Sora 时就提到了图像生成功能,所以一种可能是:它将由现有的「sora-turbo」模型驱动。

此外,有人突然想起:我们还没有在 ChatGPT 上看到来自 GPT-4o 的多模态图像生成功能。
还有消息说,Sora 中的文本到图像生成器代号为「papaya」:

回想起来,OpenAI 发布 DALL-E 3 距今也有一年半了,下一代模型会有怎样的创新?你有何期待?
参考链接:https://x.com/testingcatalog/status/1888256244063838527


























