前言:改个文件还得手动?试试 sed,一秒搞定!
大家好,我是小康。
还在手动修改配置文件?日志分析时翻半天找关键词?批量替换文本还得一个个点开改?
别折腾了!今天就带你认识 Linux 里的“文本处理神器”——sed,让你用一行命令,批量修改、删除、替换文本内容,轻松搞定以前要手动改半天的事!
用 sed 能干什么?
- 批量修改文本 👉 比如,把 hello 全部改成 hi
- 删除特定行 👉 比如,删掉文件里的第 10 行
- 提取特定内容 👉 比如,只显示文件里的第 5 到 10 行
- 日志分析 👉 过滤掉无关信息,只显示你关心的部分
sed 很强大,很多 Linux 高手天天都在用,但很多人还不知道它的威力。今天,我们就来聊聊 sed,只讲 最常用的命令,不搞复杂难懂的东西,让你 看完就能用,学完就能上手!

一、sed 是什么?为什么你一定要学会它?
sed 简单介绍
sed,全称 Stream Editor(流编辑器),它的核心思想是:
不打开文件,直接在命令行中修改、删除、替换文本,并且可以把修改后的结果输出到终端或保存到文件。
换句话说,它不像 vim、nano 那样需要手动编辑文件,而是 自动化处理文本,适合处理日志、批量修改文件、数据提取等场景。
基础用法:
这个 指令 就是告诉 sed 你想干嘛,比如 替换、删除、显示某些行。
二、sed 最常用的 6 个操作
光讲概念没意思,直接上实战,不看废话,看完就会!
1. 替换文本(相当于 Ctrl+H)
用法:
- s:表示 substitute(替换)
- /旧内容/新内容/:表示 将“旧内容”替换成“新内容”
🌟 示例:把 hello 替换成 hi
输出:
在文件里替换:
假设 file.txt 里有:
执行:
输出:
- 这里只是打印出修改后的结果,但不会真正修改 file.txt 的内容。
- 你只是看到终端里 hello 被替换成了 hi,但 file.txt本身没有发生任何变化。
你可以用 cat file.txt 再看一遍文件内容,会发现它还是原来的样子。
问题:怎么只替换了每一行第一个出现的 hello?怎么全部替换 ?如果我想改文件,又该怎么做? 👀 ,继续往下看。
2. 全局替换(所有匹配项都替换)
默认情况下,sed只替换每一行的第一个匹配项,如果想替换所有,要加 g(global):
输出:
记住 g,否则只会替换每行的第一个匹配项!
3. 直接修改文件
默认 sed 不会改动原文件,只是把修改结果输出到终端。如果想真正改文件,需要加 -i:
注意:
- -i直接修改文件,没有撤销功能,误操作可能会导致数据丢失!
- 建议先使用 cat file.txt 看看内容,确保不会误改重要文件。
更安全的方式:先备份文件,再修改!
为了避免误操作导致数据丢失,推荐使用 -i.bak先创建文件备份,然后再修改:
执行后,系统会:
- 修改 file.txt,将 hello 替换成 hi。
- 自动创建 file.txt.bak 备份文件(修改前的内容)。
示例:
假设 file.txt 内容如下:
执行:
执行后:
- file.txt 被修改:
- file.txt.bak 是原始文件的备份(未修改的内容):
如何恢复原文件?
如果修改后发现有问题,可以随时恢复:
这样,file.txt 就会恢复成修改前的版本!
4. 删除某一行
语法:
- N 代表 行号
- d 代表 删除
🌟 示例:删除第 2 行
假设 file.txt 内容:
执行:
输出:
🌟 删除最后一行
输出:
$ : 代表最后一行
🌟 删除所有包含 Bob 的行
✅ 输出
/内容/d 就是按内容删除,N d 就是按行号删除!
🌟 删除所有空行
^$ 代表空行,所以这条命令能删掉所有空白行!
🌟 删除前 N 行
语法:
- 1,5d:删除从第 1 行到第 5 行
- 最终效果:删除前 5 行,只保留第 6 行之后的内容
适用于清理文件头部信息,删除表头或无用数据。
🌟 删除第 N 行到最后一行
语法:
- 2,$ :表示从第 2 行到最后一行
- d:表示删除
最终效果:只保留第一行,删除后面所有内容
🌟 删除包含多个关键词的行
语法:
- /error\|fail/ : 匹配 error 或 fail
- d :删除匹配的行
最终效果:删除所有包含 "error" 或 "fail" 的行
示例
假设 file.txt 里有:
执行:
输出:
适用于日志分析、错误排查,快速过滤无用日志。
🌟 删除所有以字母开头的行
语法
- ^ :匹配行首
- [a-zA-Z] : 匹配任何字母
- d : 删除匹配的行
最终效果:删除所有以字母开头的行
🌟 示例
假设 file.txt 里有:
执行:
输出::
适用于日志清理、去除无用数据、提取数值信息。
5. 只显示某些行
语法:
- N 代表 行号
- p 代表 打印
🌟 示例:打印第 2 行
假设 file.txt 内容:
执行:
输出:
只显示匹配内容,不输出其他内容,可以加 -n。
🌟 显示 2-4 行
输出:
适用于日志分析、查看部分数据!
🌟 只显示匹配的行
如果你想找出所有包含 Bob 的行:
-n 选项的作用是 关闭默认输出,只显示 p(print)匹配的内容。
6. 在指定行前/后插入文本
假设 file.txt 内容:
🌟 在第 2 行前插入 "Henry is comming"
输出:
"Henry is coming" 被插入到 第 2 行前面,所以 Alice 变成了第 3 行。
🌟 在第 3 行后插入 "David is comming"
输出:
i 代表 insert,在某行前插入内容;a 代表 append,在某行后追加内容。
三、sed 其他常见操作
🌟 修改某一行
语法:
- 3c\ :表示修改第 3 行
- "This is a new line" : 替换的新内容
最终效果:第 3 行的内容会被 "This is a new line" 替换
示例:
假设 file.txt 里有:
执行:
输出:
c\ 命令用于修改某一行的内容,适用于日志清理、格式调整。
🌟 提取包含数字的行
语法:
- -n :只显示匹配的行
- [0-9] :匹配数字
- p :打印匹配的行
最终效果:只显示包含数字的行,忽略其他行
🌟 示例
假设 file.txt 里有:
执行:
输出:
适用于日志分析、数据提取、过滤出数值行。
🌟 删除空格(去除所有行首和行尾空格)
语法:
- ^[ \t]*// : 删除行首的空格和 Tab
- [ \t]*$// : 删除行尾的空格和 Tab
最终效果:去除行首和行尾的空格
🌟 示例
假设 file.txt 里有:
执行:
输出:
适用于格式化文本、清理无用空格,让文件更整洁!
🌟 删除 HTML 标签
语法:
- <[^>]*> : 匹配 HTML 标签
- s/...//g : 替换为空
最终效果:去掉 HTML 标签,只保留纯文本
🌟 示例
假设 file.html 里有:
执行:
输出:
适用于网页数据提取、去除 HTML 代码,保留文本内容。
🌟 删除注释(# 或 // 开头的行)
语法:
- ^# : 匹配 # 开头的行
- ^// : 匹配 // 开头的行
- d : 删除匹配的行
最终效果:删除配置文件或代码中的注释
🌟 示例
假设 config.txt 里有:
执行:
输出:
适用于去除无用注释,让配置文件更加简洁清晰!
🌟sed -e 命令的使用
-e 选项的作用是在同一条 sed 命令中执行多个操作,可以替换、删除、插入等多种操作同时进行。
sed -e 基础用法:
作用:按顺序执行多个 sed 操作。
1. 依次执行多个替换
示例:
作用:
- 替换 "Alice" 为 "Jane"
- 替换 "Bob" 为 "John"
🌟 示例
文件 file.txt
执行命令:
输出:
多个 -e 选项可以让 sed 依次执行多个替换操作!
2. 依次执行“删除 + 替换”
示例:
作用:
- 删除 # 开头的注释行
- 将 error 替换成 ERROR
🌟 示例
文件 file.txt:
执行命令:
输出:
适用于日志清理,先删除注释,再格式化错误信息!
3. 结合 -e 实现多行插入
示例:
作用:
- 在第 2 行前插入 --- Start ---
- 在第 4 行后插入 --- End ---
🌟 示例
文件 file.txt:
执行命令:
输出:
适用于文本标记、自动化修改文件!
4. -e 结合 -i 直接修改文件
示例:
作用:
- 将 foo 替换为 bar
- 将 old 替换为 new
- 直接修改 file.txt,而不是只输出到终端!
-i 让 sed 直接修改文件内容,而不是只显示修改后的文本!
5. -e 结合 -n 只显示匹配的结果
示例:
作用:
- 仅打印包含 "error" 或 "fail" 的行
- 忽略其他行的输出(-n)
适用于日志分析,快速提取重要信息!
四、sed 结合 find、grep、awk 等常见组合命令
在实际工作中,sed 通常不会单独使用,而是和 find、grep、awk、xargs、tee 等命令组合,形成更强大的文本处理工具链,适用于 批量修改文件、日志分析、数据处理 等场景。🚀
1. sed + find:批量修改多个文件
场景:批量替换某个目录下所有 .txt 文件中的 hello为 hi
作用:
- find /path -type f -name "*.txt" : 查找 /path 目录下所有 .txt 文件
- -exec sed -i 's/hello/hi/g' {} + : 在所有找到的文件里替换 hello 为 hi
- + : 批量执行,提高效率(比 \; 更快)
示例 : 假设 /path 目录下有:
执行后:
适用场景:
- 批量修改配置文件
- 处理大量日志文件
- 自动化代码修改
2. sed + grep:只修改包含特定内容的行
场景:只修改包含 "error" 的行,把 "failed" 替换为 "FAILED"
作用:
- grep "error" file.txt : 先筛选 出包含 "error" 的行
- sed 's/failed/FAILED/g' : 只修改这些行 中的 "failed"
示例 : 原 file.txt
执行:
输出:
适用场景:
- 过滤日志文件,并修改某些内容
- 只修改特定关键字所在的行
- 避免误修改不相关的行
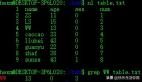
3. sed + awk:精准修改特定列
场景:批量修改 CSV 文件的第 2 列,把 low 改成 LOW
作用:
- -F, : 以逗号分隔
- gensub(/low/, "LOW", "g", $2) : 只替换第 2 列的 low
- OFS=, : 保持逗号分隔格式
- 最终:只修改第 2 列,保留其他列不变
示例 :原 file.csv
执行:
输出:
适用场景:
- 精确修改某一列的内容,不影响其他列
- 适用于 CSV、TSV、日志文件
- 比 sed 更精准,sed 只能针对整行替换,而 awk 能操作特定字段
4. sed + xargs:批量修改多个文件
场景:在多个 .log 文件里批量替换 "DEBUG" 为 "INFO"
作用:
- find /var/log -type f -name "*.log" : 查找所有 .log 文件
- xargs sed -i 's/DEBUG/INFO/g' : 批量替换,不会逐个执行(比 -exec 更快)
适用场景:
- 高效处理海量文件(比 find -exec 更快)
- 避免 Too many arguments 错误(当文件太多时,xargs 会批量处理)
5. sed + tee:边修改边输出
场景:把 config.conf 里的 "8080" 端口改成 "9090",同时保存到 new_config.conf
作用:
- sed 's/8080/9090/g' config.conf : 修改端口
- tee new_config.conf : 同时输出到终端和 new_config.conf
适用场景:
- 保留原始文件,不直接修改
- 先检查输出,确保无误再用 -i 修改
6. sed + diff:对比修改前后的差异
场景:我们有一个 file.txt,其中包含 "error",想用 sed 把它改成 "ERROR",但在真正修改前,先用 diff 对比 修改前后的差异,确保不会误改。
示例
file.txt 内容:
(1) 用 sed 预览修改
预期输出:
(2) 用 diff 对比修改前后
输出:
解释:
- 2c2 : 第 2 行变化:
- 4c4 : 第 4 行也有类似的变化。
(3) 确认无误后,正式修改文件
-i 直接修改 file.txt,不用手动保存
适用场景:
- 检查 sed 修改的影响,避免误改
- 对比文件修改前后的版本,避免数据丢失
- 适用于日志分析、代码改动、批量文本处理
sed + diff 让你在修改前先检查变化,确保修改准确无误,数据安全性更高!
五、总结:掌握 sed,让文本处理更高效!
sed 是 Linux 中强大的文本处理工具,它不仅能 查找、替换、删除、插入文本,还能结合 find、grep、awk、xargs 等命令,实现批量修改和自动化处理。无论是 日志分析、批量修改配置文件、处理文本数据,sed 都能帮你 减少重复劳动,大幅提升工作效率。
学完这篇文章,你应该掌握了这些核心操作:
基础操作:
- 通过 s/old/new/g 实现 文本替换(相当于 Ctrl+H)。
- 用 -i 选项 直接修改文件,无需手动打开编辑。
- 删除某行(按行号删除、按匹配模式删除)。
- 显示或提取特定内容(比如第 10 行、包含某个关键字的行)。
- 在指定行前/后插入文本,适用于配置文件修改。
进阶技巧:
- 结合 find,批量修改多个文件,不再逐个手动编辑。
- 结合 grep,只修改包含特定内容的行,提高精准度。
- 结合 awk,针对特定列进行修改,处理 CSV、日志等结构化数据。
- 结合 xargs,高效处理多个文件,节省时间。
- 结合 tee,边修改边输出,适用于调试和日志处理。
适用场景:
- 批量修改代码或配置文件,比如 替换端口号、修改日志级别、更新 URL 等。
- 清理和格式化日志,如 删除多余信息、提取 IP 地址、去除 HTML 标签或注释。
- 数据分析和处理,用于 提取特定字段、格式化文本数据,与 awk 结合使用更加强大。
学会 sed,你就能轻松修改文件,不再手动改一堆文本!
进一步学习:学完 sed,下一步该学什么?
恭喜你!现在你已经掌握了 sed 的核心用法,并且知道如何 高效查找、替换、删除、插入文本,大幅提高了处理文本的效率。但在 Linux 文本处理的世界里,sed 只是 第一块拼图,还有一个更加强大的工具——awk!
sed 主要用于修改和处理文本,而 awk 更适合分析和提取数据,比如:
- 提取 CSV 文件中的某一列数据。
- 计算日志中某个关键词出现的次数。
- 统计服务器访问日志中,每个 IP 的请求次数。
- 对文本数据进行筛选、计算、分组统计等操作。
如果 sed 是“文本编辑器”,那 awk 就是“文本计算器”!