












大语言模型(LLM)评估系统在生成思维链(Chain-of-Thought, CoT)序列时,需要系统地捕捉评估过程中的推理步骤。但是由于缺乏人工标注的CoT训练数据,以及预定义评估提示在复杂任务中的局限性,构建高质量的LLM评估模型面临重大挑战。另外手动调整评估指令的方法在面对多样化和复杂任务时表现出明显的局限性。
为应对这些挑战,研究团队提出了EvalPlanner[1],这是一种创新的LLM评估算法。该算法采用计划-执行的双阶段范式,首先生成无约束的评估计划,随后执行该计划并做出最终判断。这种方法显著提升了评估过程的系统性和可靠性。
核心方法论
系统架构
EvalPlanner的架构包含三个核心组件,如下图所示:

具体来说,系统包含以下关键要素:
a) 评估计划(z)
- 基于输入指令x,系统制定具体的响应评估策略
- 计划设计注重灵活性和通用性
b) 计划执行模块
- 依序执行评估计划的各个步骤
- 分析目标响应a和b,生成详细的评估结果
c) 最终判决(y)
- 在评判LLM(参数θ)的框架下,将计划z和执行e作为潜变量
- 判决生成过程可表述为:

工作流程
系统的整体工作流程如下图所示:
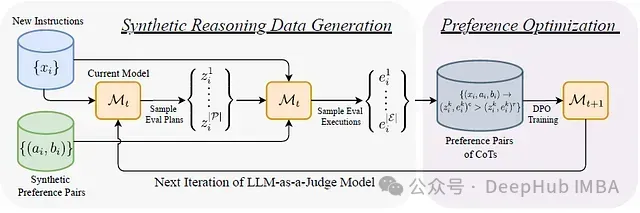
主要步骤包括:
- 从分布P中采样多个评估计划z
- 对每个计划,从分布E中采样多个执行路径e
- 通过自训练循环优化计划和执行过程
- 在测试阶段,模型生成结构化的CoT输出:ỹ = (z̃, ẽ, ỹ)
训练数据生成方法
提示词选择与响应对生成
系统采用两类核心任务领域:
- 通用指令执行任务
a.通过对原始指令引入噪声生成对比样本
b.原始指令响应作为正例,噪声指令响应作为负例
- 数学推理任务
- 采样多个候选响应
- 正确解答作为正例,错误解答作为负例
评估计划生成
系统采用通用且无约束的计划生成提示模板,该模板仅基于输入指令查询经过指令调优的LLM以获取初始计划。提示模板的核心内容如下:
计划执行生成
计划执行阶段采用种子模型,结合指令和响应对,基于生成的计划进行推理并产生判决。
这种分离式架构具有两个主要优势:
- 确保执行过程严格遵循预定计划
- 通过对同一计划采样多个执行路径,增加评估数据的多样性
构建计划-执行偏好对
对于每个输入指令:
- 采样|P|个计划
- 每个计划采样|E|个执行路径
- 考虑响应对的两种顺序(a,b)和(b,a),总共生成2×|P|×|E|个CoT序列
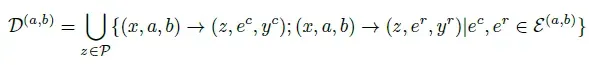
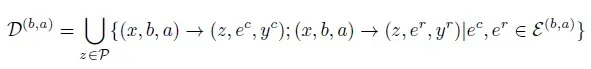
计划与执行的优化策略
系统采用自训练循环进行优化,主要包含以下步骤:
初始监督微调(SFT)
- 从种子模型M₀开始
- 在正确思维子集D₁ᶜ上进行微调
- 得到模型M₁ˢᶠᵀ
第一轮直接偏好优化(DPO)
- 以M₁ˢᶠᵀ为基础
- 在包含正确与错误思维的数据集D₁上执行DPO
- 得到模型M₁ᴰᴾᴼ
第二轮直接偏好优化(DPO)
- 以M₁ᴰᴾᴼ为基础
- 在新的指令和响应对子集D₂上执行DPO
- 得到最终模型M₂ᴰᴾᴼ
实验设置与评估
训练数据构建
- WildChat数据集:使用自学习评估器生成综合响应
- MATH数据集:通过Mixtral 22Bx8 Instruct模型生成多个候选解答
实验配置
训练数据规模:
- WildChat: 17,588个独特三元组
- MATH: 4,141个独特三元组
采样参数:
- 每次迭代5个计划
- 每个计划8个执行路径(每种顺序4个)
- 温度参数0.8,top_p值0.95
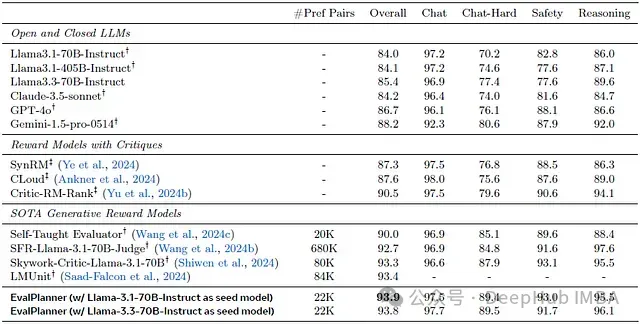
基准比较
模型性能与多个基准系统进行对比:
- 零样本评估的开源和闭源LLM
- 具有评论功能的奖励模型
- RewardBench排行榜上的领先模型
实验结果与分析
性能优势
EvalPlanner展现出显著的性能优势:
- 在较少训练数据的情况下超越所有基准系统
- 为生成式奖励模型创造新的性能记录
- 在多个种子模型上展示方法的普适性
数据效率
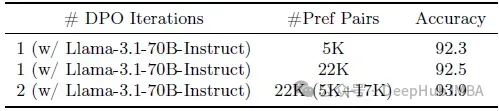
系统表现出优异的数据效率:
- 仅使用5K偏好对即达到92.3的性能分数
- 通过迭代DPO进一步提升至93.9
- 相比单次DPO迭代(92.5)取得明显进步
泛化能力
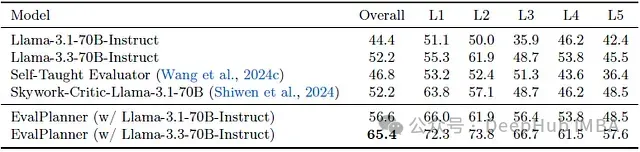
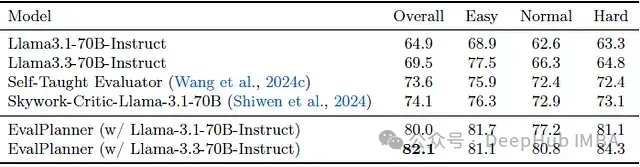
在多个评估基准上验证了系统的泛化能力:
- FollowBenchEval:在多层次约束评估中超越基准13%
- RM-Bench:展示出对内容变化的强大鲁棒性
- JudgeBench:在多类别挑战性问题上保持竞争力

总结
EvalPlanner通过创新的计划-执行范式,成功解决了LLM评估模型面临的核心挑战。系统在多个基准测试中的出色表现,证实了该方法在构建高效、稳健的评估模型方面的有效性。特别是在数据效率和泛化能力方面的优势,为未来LLM评估系统的发展提供了新的研究方向。





























