新一代 Kaldi 团队是由 Kaldi 之父、IEEE fellow、小米集团首席语音科学家 Daniel Povey 领衔的团队,专注于开源语音基础引擎研发,从神经网络声学编码器、损失函数、优化器和解码器等各方面重构语音技术链路,旨在提高智能语音任务的准确率和效率。
目前,新一代 Kaldi 项目 (https://github.com/k2-fsa)主要由四个子项目构成:核心算法库 k2、通用语音数据处理工具包 Lhotse、解决方案集合 Icefall 以及服务端引擎 Sherpa,方便开发者轻松训练、部署自己的智能语音模型。
近日,小米集团新一代 Kaldi 团队关于语音识别算法的论文《CR-CTC: Consistency regularization on CTC for improved speech recognition》被 ICLR 2025 接收。

- 论文链接:https://arxiv.org/pdf/2410.05101
- 论文代码:https://github.com/k2-fsa/icefall/pull/1766(已 merge 进 icefall 框架)

摘要
主流的自动语音识别(ASR)模型包括 CTC [1]、transducer [2] 和混合系统 CTC/AED [3]。CTC 是其中最简单、最便于部署的方法,但由于它的性能通常明显落后于 Transducer 和 CTC/AED,这限制了它的实际应用。
为此,新一代 Kaldi 团队提出了 Consistency-Regularized CTC (CR-CTC),可以让纯 CTC 模型的识别性能比肩 Transducer 和 CTC/AED。CR-CTC 在多个主流的 ASR 数据集,包括 LibriSpeech、Aishell-1、GigaSpeech 等数据集上,取得新的 SOTA 结果(不依赖外部训练数据和外部语言模型)。
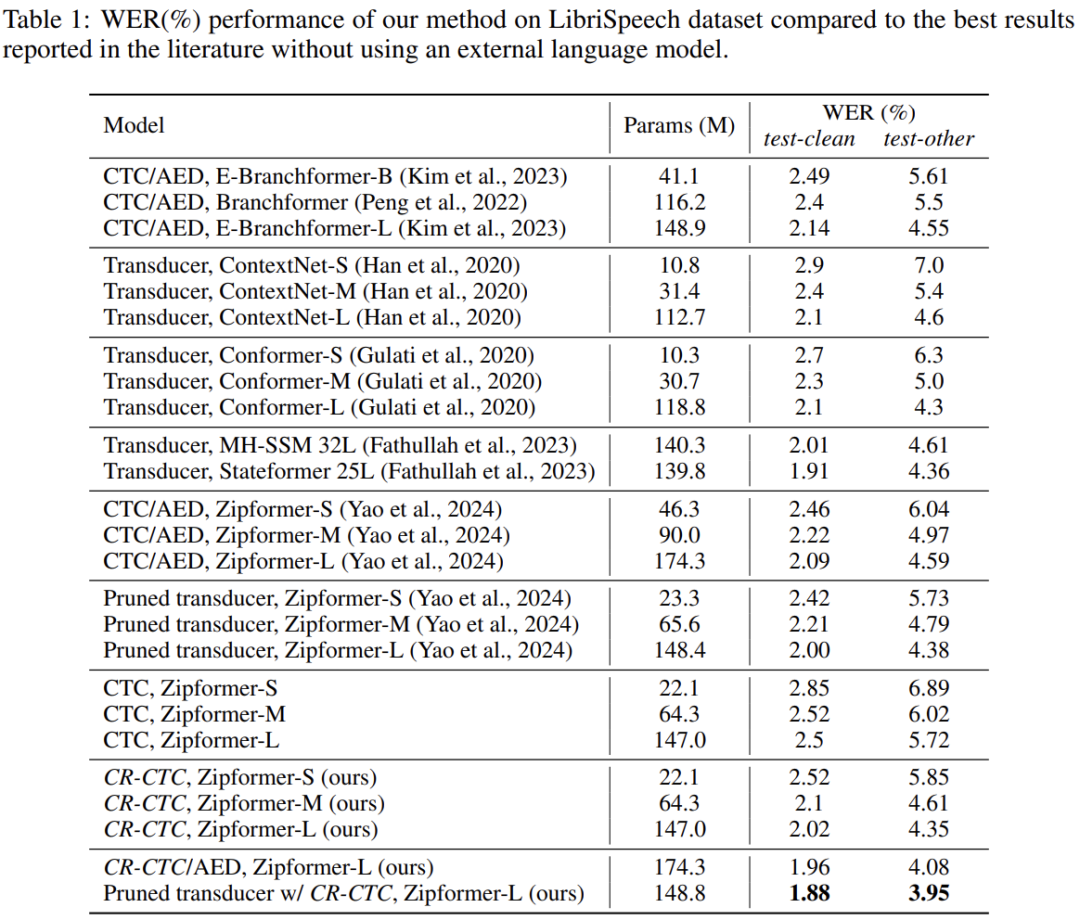
例如,在 LibriSpeech 数据集上训练 Zipformer-L,标准 CTC 的 WER 为 2.5/5.72,CTC/AED 的 WER 为 2.09/4.59, Pruned Transducer 的 WER 为 2.00/4.38;CR-CTC 的 WER 为 2.02/4.35;CTC/AED 和 Pruned Transducer 挂上 CR-CTC 联合训练后,WER 可分别进一步降低到 1.96/4.08 和 1.88/3.95。
方法实现
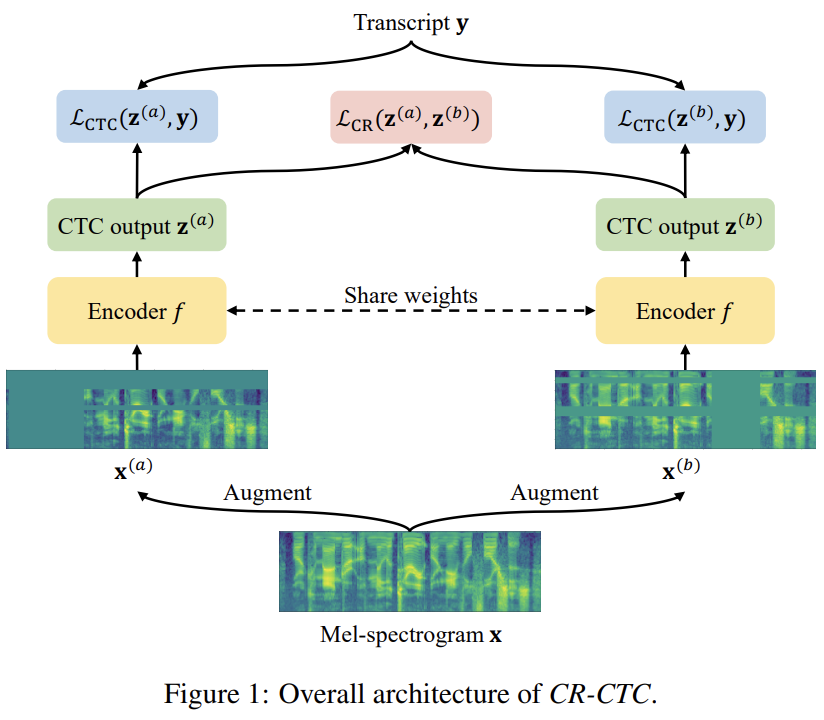
如 Figure 1 所示,CR-CTC 方法非常简单,先从同一个输入 Mel-spectrogram x 得到两个不同的 augmented views 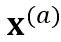 和
和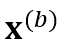 ,分别输入参数共享的 encoder 模型 f,得到对应的两个 CTC 概率分布
,分别输入参数共享的 encoder 模型 f,得到对应的两个 CTC 概率分布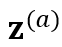 和
和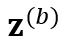 ,除了计算两个 CTC loss
,除了计算两个 CTC loss 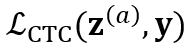 和
和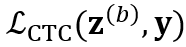 ,还引入 consistency regularization loss 来约束两个分布的一致性:
,还引入 consistency regularization loss 来约束两个分布的一致性: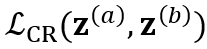 。系统总体 loss 为:
。系统总体 loss 为:
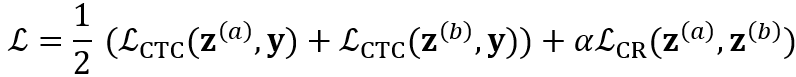
其中 α 为控制正则的超参数,默认设置为 0.2。
Different augmented views
我们对同一个输入 x 的两个 copy 独立地使用 SpecAugment [4] 来获得不同的 augmented views  和
和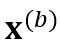 。SpecAugment 包含 time warping、frequency masking 和 time masking。由于 time warping 会显著改变输出的时间戳,因此我们在创建 copy 前先应用 time warping,防止两个分支的输出分布在时间戳上严重不匹配。接着,分别对两个 copy 独立应用 frequency masking 和 time masking,得到了
。SpecAugment 包含 time warping、frequency masking 和 time masking。由于 time warping 会显著改变输出的时间戳,因此我们在创建 copy 前先应用 time warping,防止两个分支的输出分布在时间戳上严重不匹配。接着,分别对两个 copy 独立应用 frequency masking 和 time masking,得到了 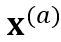 和
和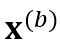 。相较于普通的 ASR 系统,我们特意使用了更大程度的 time masking。
。相较于普通的 ASR 系统,我们特意使用了更大程度的 time masking。
Consistency regularization loss
我们在CTC 分布的每一帧上应用 consistency regularization,通过最小化每一对分布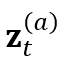 和
和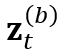 之间的双向 KL 散度:
之间的双向 KL 散度: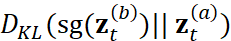 和
和  。此处,sg 表示 stop-gradient,防止这一项的梯度影响目标分布。Consistency
regularization loss 公式为:
。此处,sg 表示 stop-gradient,防止这一项的梯度影响目标分布。Consistency
regularization loss 公式为:

方法解释
论文从三个不同的角度来解释 CR-CTC 的本质行为:1)self-distillation;2)masked prediction;3)peak suppression。
Self-distillation
当我们在训练中使用 dropout [5] 和 stochastic depth [6] 等模型正则技术,可以看作我们正在隐式地训练随机采样的不同 sub-model,这些 sub-model 最终被集成为一个 ensemble 用于推理。与 R-Drop [7] 和 cosub [8] 类似,CR-CTC 在进行对不同 sub-model 之间的 self-distillation,监督信号为对方提供的帧级别的 token 分布。另外,CR-CTC 使用了不同的 augmented views(以及更大程度的 time-masking),让这些 sub-model 接触输入数据的不同角度的信息,加强他们预测的多样性,这样有利于更丰富、更完备的知识蒸馏。
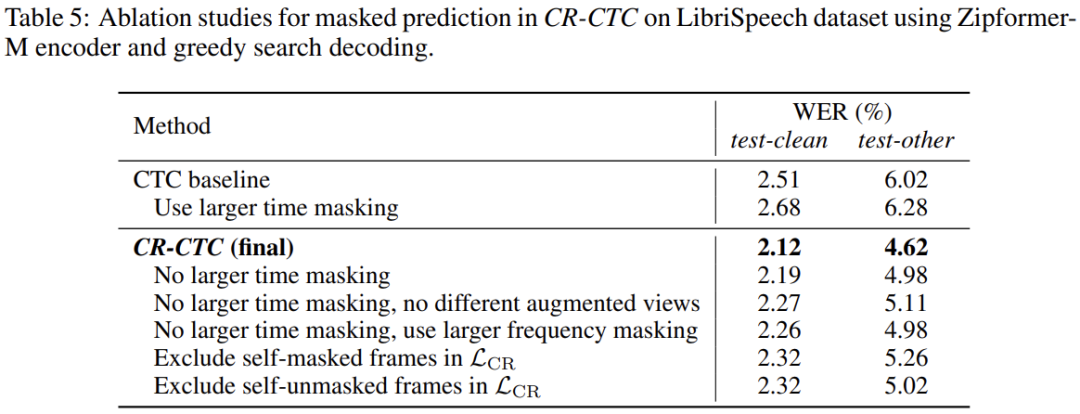
Masked prediction
在 CR-CTC 中,那些覆盖在 time masking 区域的帧,被要求着基于其他没有被 masked 的区域,去预测对方提供的 token 分布。这个过程类似于 masked-based 自监督模型 [9,10,11],鼓励模型去学习非 mask 部分的上下文表征信息,并发掘模型隐式的语言建模能力。我们在 CR-CTC 中使用不同的 augmented views,减少两边同时被覆盖在 time masking 区域的帧的出现,提高这些被 masked 位置所接收的 token 分布的质量。另外,使用更大程度的 time masking 可以加强 masked prediction 行为,进而增强模型对上下文表征信息的学习。
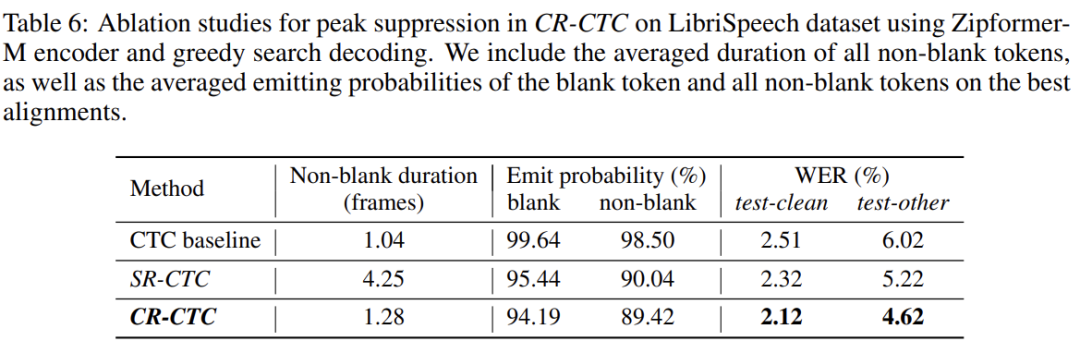
Peak suppression
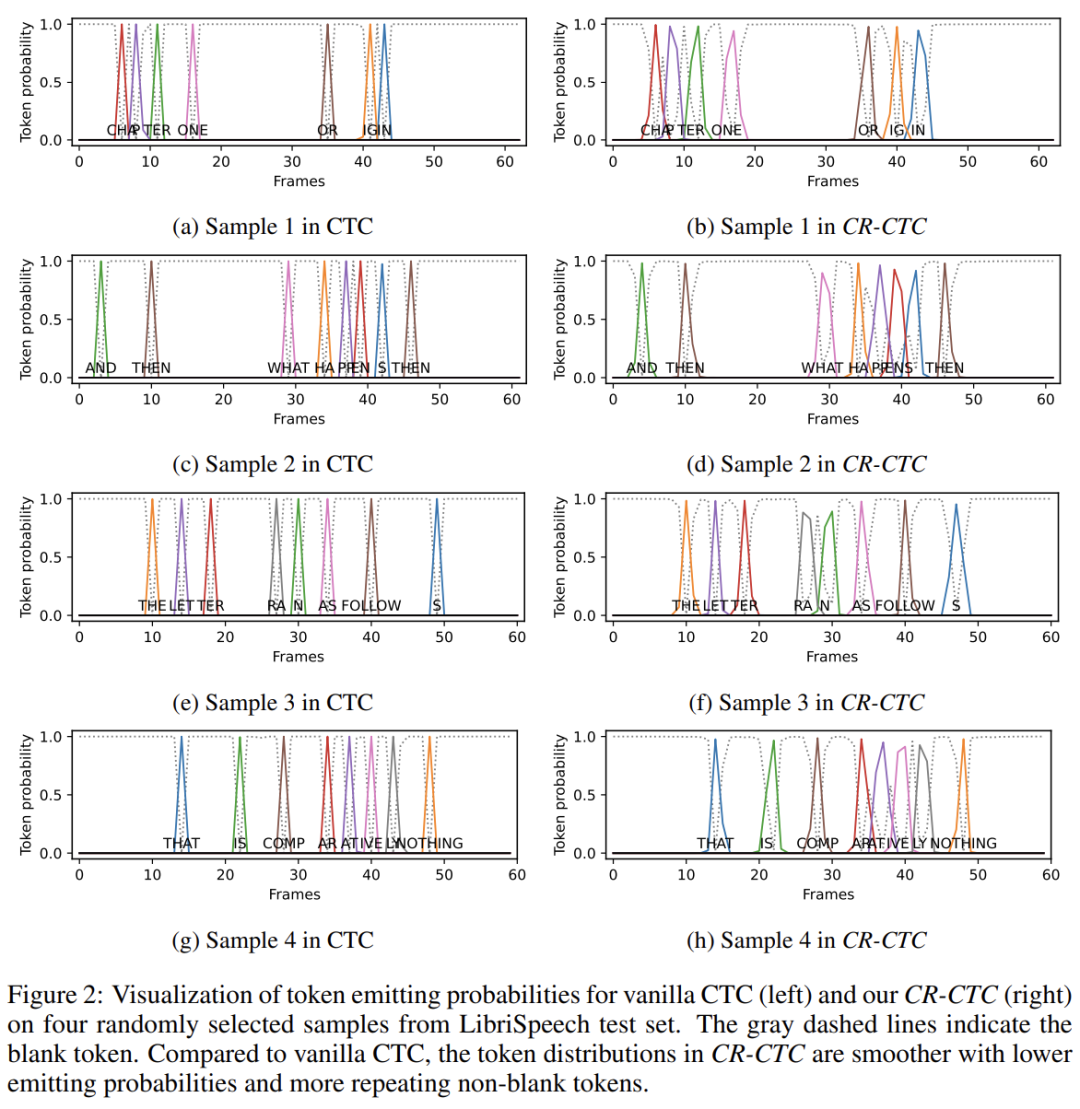
众所周知,CTC 通常会学习到非常尖的概率分布。如 Figure 2 (left) 所示,non-blank token 只占 1 帧,其他的都是 blank,它们的概率都非常高。这种现象表明模型有可能已经过拟合了,泛化能力不强。CR-CTC 的 consistency regularization 引导着模型学习两边分布的平均,这使得模型学习到的 CTC 分布会更加平滑。这个 peak suppression 行为减少了在训练数据上的过度置信,从而增强模型的泛化能力。如 Figure 2 (right) 所示,CR-CTC 学习到的分布更加平滑,概率更低,伴随着更多 non-blank 的 repeat 出现。
实验结果
论文主要使用 Zipformer [12] 作为 speech encoder 进行实验验证。由于 CR-CTC 训练时需要进行两次 forward,我们对 CR-CTC 模型的 batch size 和 epoch 数都设置为标准 CTC 模型的一半,来确保两者训练代价可比较。具体使用的 GPU 数量和 epoch 数在论文附录中。
与 SOTA 模型相比较
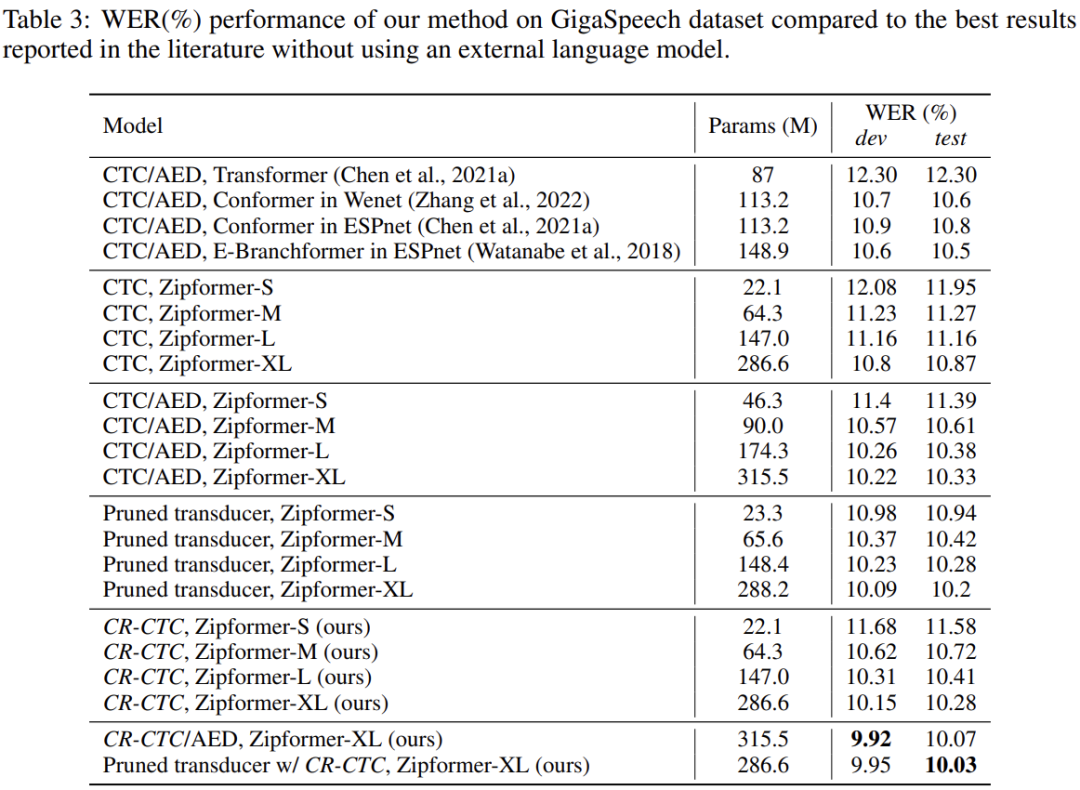
Table 1、2、3 分别展示了不同模型在 LibriSpeech、Aishell-1、GigaSpeech 三个数据集上的表现(不依赖外部训练数据和外部语言模型)。总的来说,CR-CTC 的性能显著超越标准 CTC,和 CTC/AED 与 Transducer 模型效果相当。另外,挂上 CR-CTC 联合训练,可以进一步提升 CTC/AED 和 Transducer 的性能。在这三个数据集上,我们取得了新的 SOTA 结果。

消融实验
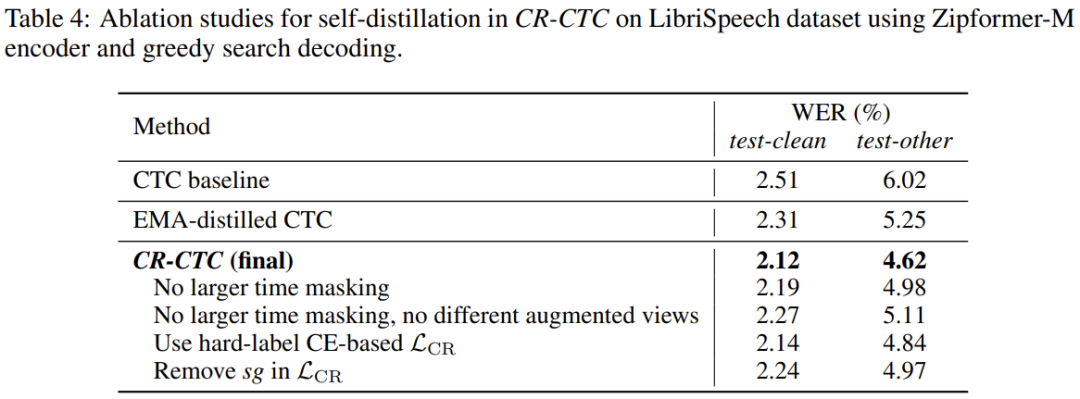
Table 4、5、6 分别展示了 CR-CTC 关于不同解释角度 self-distillation、masked prediction、peak suppression 的消融实验结果,具体说明可参考论文。
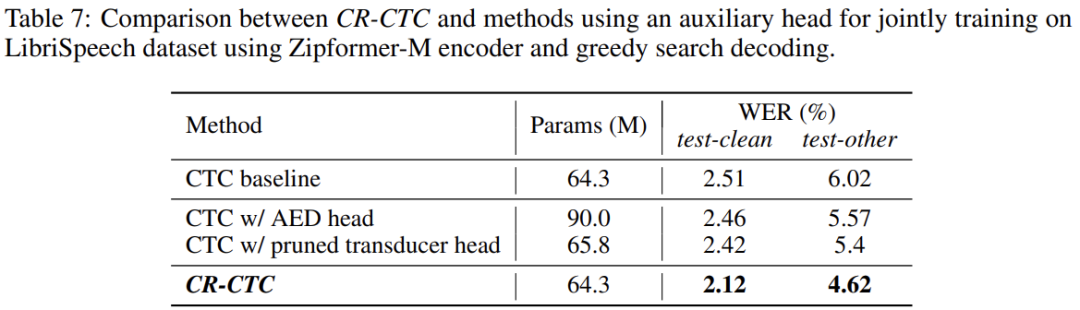
与挂一个 auxiliary head 联合训练相比较
想要提升 CTC 系统的性能,一个最直接的方法便是挂一个 AED head 或者一个 Transducer head 联合训练。如 Table 7 所示,CR-CTC 的性能明显超过这两个方法,参数还更少。
在 Conformer 模型上验证
如 Table 17 所示,使用 Conformer [13] 作为 speech encoder 时,CR-CTC 同样可以显著提升 CTC 的性能,并且略微超过 CTC/AED 和 Transducer。