你是一个程序员,你太想进步了,于是准备下载 256g 的学习资料,放到电脑硬盘上。
但你的电脑最多只能存放 128g 数据。怎么办呢?
好办,你衣柜里还有台大学时的旧电脑。平分一下,正好够放。下岗机器再就业,你感觉你是个天才。
可麻绳总挑细处断,旧电脑磁盘终究还是写坏了。
于是你选择从衣柜里再拿两台旧电脑做备份。这样就不怕磁盘坏了。
但这个切分数据和备份数据的过程每次都得手动操作。

手动切分和备份数据
不仅容易出错,还贼浪费时间!
有解法吗?
有,没有什么是加一层中间层不能解决的,如果有,那就再加一层。
这次我们要加的中间层是 HDFS。

hdfs
HDFS 是什么?
HDFS, 全名 Hadoop Distributed File System,是大数据领域常用的分布式文件系统。
你可以将它当做 应用服务和多个服务器文件系统的中间层,帮应用屏蔽掉背后的多个服务器,从多个服务器上读写文件数据。
并通过一系列策略保证数据可靠性,就算某些服务器磁盘坏了,也不影响数据完整。

hdfs是应用服务和多个服务器文件系统的中间层
我们来看下它是怎么做到的。
数据块是什么
如果你有个超大文件,该怎么将它们存到多台服务器磁盘上呢?
按理说直接挑一台磁盘充足的服务器写入就好了,但如果每台服务器的剩余磁盘空间都不足以存下这个大文件呢?
好办, 我们可以将大文件切成多个数据块,也就是 block, 每个数据块默认 128MB。

数据块
这个大小的数据块正好可以写入到多个服务器磁盘的犄角旮旯里,既完成了大文件的存储,又提升了磁盘空间利用率。
容错
但如果这时候某台服务器磁盘被写坏了,那背后牵连的很多大文件,就全废了。怎么办呢?
追爱路上遍体鳞伤的沸羊羊,会含泪给你答案,当然是多养几个备胎。
我们可以将数据块复制几份出来,分散放到不同服务器上,就算其中一台服务器跪了,还能从其他服务器上拿到数据块。分散了风险,大大提升了系统容错率!

在其他服务器上冗余数据
但问题又来了,大文件被拆成了多数据块,多副本写入后。如果程序想读大文件,怎么知道该从哪个服务器里读呢?
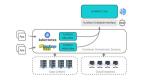
HDFS 架构
为了解决上面的问题,HDFS 会将我们的服务器集群划为两部分,一部分是Master 节点,也叫 NameNode,另一部分是Slave 节点,也叫DataNode。

hdfs架构
从名字能看出,它们的关系就是老板和打工人。
NameNode 负责管理 DataNode,决定应用程序该到哪个 DataNode 去读写数据块。DataNode 才是真正负责存储数据块的牛马。
它们共同构成了 HDFS 集群,对外提供了读写文件,以及修改读写权限等一系列能力。

hdfs集群
而且 HDFS 还提供了 CLI 和 API,程序员可以方便地进行文件操作,不需要手写代码来处理大文件的拆分和组装。

可以通过CLI和API访问hdfs
DataNode 是什么
牛马 DataNode 负责实际存储数据,很辛苦,但它的工作确实没什么技术含量,写坏了就用另外一块新的 DataNode 顶上。主打一个你不干,有的是 DataNode 愿意干。存储的数据量大了,就多加几个 DataNode。
正因为 DataNode 每天都需要疯狂读写,所以身体,啊不对,磁盘很容易垮,但是其他 DataNode 上面也备份了文件数据,可替代性很高,所以不用给它们配太好的服务器,能跑就行。

datanode使用普通服务器
反观 NameNode,就不一样了,它维护了所有服务器集群的信息,是大脑,是核心,金贵的很,所以得用高性能服务器好生供养着。
不行,越说越生气了。

namenode使用高性能服务器
我们看下 NameNode 是怎么管理文件的?
NameNode 是什么
我们平时在电脑上,是通过目录树的形式管理文件。
而在 HDFS 的 NameNode 中,也用类似的目录树形式管理文件,每个文件都有对应文件名、大小和对应地址以及访问权限。这些信息,我们叫它元数据。

元数据
这个管理目录树和元数据的能力,就叫 NameSpace。
同时 NameNode 还记录了某个文件,分成了多少个数据块这些信息。知道了大文件有哪些数据块后,我们还需要维护和管理数据块被存在了哪个 DataNode 上,这部分能力叫 Block Manager。

NameNode内部
高性能
为了支持高性能读写,NameNode 将 NameSpace 和 Block Manager 的数据全放内存中。

NameNode将数据放内存
持久化
但放内存里有个大问题,进程要是崩了,那数据就丢了。
怎么办呢?
我们可以将 NameSpace 和 Block Manager 定期持久化到磁盘文件里,这个文件就是 fsimage,它记录了某一时刻 NameNode 的全量数据,类似于游戏的"存档"。

NameNode数据存档
但"存档"是需要时间的,在这次存档完成之后,下一次存档完成之前,写入的数据是不是会丢失呢?
好办,NameNode 会将"存档"后写入了哪些信息,记录到一个叫 editlog 的文件里,定时刷盘。这样就算进程挂了,重启的时候,通过加载 fsimage+editlog, 就能尽可能复原数据。保证了数据可靠性。

引入editlog
高可用
想必大家也发现了,NameNode 是 HDFS 集群的核心,存在单点问题,要是崩了,那集群就没法对外提供服务了。
所以为了保证高可用,我们可以为 NameNode 配一个备用 NameNode, 也就是 Standby NameNode,平时主 NameNode 负责对外提供读写操作,备用 NameNode 只同步 NameNode 的数据。
一旦 NameNode 挂了,备用 NameNode 就能立马顶上。保证了集群高可用。

备用namenode
可扩展
但就算用了备用 NameNode,同一时刻,集群里其实只有一个 NameNode 对外工作。
随着 HDFS 集群规模变大,NameNode 使用的内存也会变高。换句话说就是, HDFS 性能其实受限于单服务器节点的内存和 cpu 上限。那有办法扩展吗?
有!我们知道 NameNode 里的 NameSpace 本质上是个目录树。

目录树
为了水平扩展,我们可以根据业务属性,对目录树进行拆分,也就是变成多个 NameSpace。

根据业务拆分目录树
再新增 NameNode,每个 NameNode 各自维护一个独立的 NameSpace,NameNode 之间完全不需要知道对方存了哪些数据,各自都只需要根据 DataNode 当前上报的磁盘信息就能完成读写操作。
通过这个方式,降低了 NameNode 单节点压力,同时提升了系统扩展性。这其实就是业界比较经典的 HDFS Federation 方案。

HDFS Federation方案
但单个 NameSpace 还是有可能变得很大,怎么办呢?
好办,单个 NameSpace 过大并不合理,再拆小就行了。
这就很灵性了,在你质疑我扩展性有问题之前,我先反过来质疑你业务耦合过大,是不是能拆一下。在我解决架构问题之前,先解决掉提出问题的人,也不失为一种优雅的架构师思维。
接下来我们将上面提到的内容串起来。
写大文件
- 客户端通过 HDFS API 向 NameNode 发送请求,准备写入文件。
- NameNode 在 NameSpace 中检查文件路径的合法性和客户端写权限,ok 的话,NameNode 会在 Edit Log 中记录新文件的元数据(比如文件路径、权限等),再更新 NameSpace。然后,NameNode 响应客户端。
- 之后客户端再请求 NameNode ,获取第一个数据块写入到哪些个 DataNode 上。

写入流程part1
- NameNode 的Block Manager 会根据当前存储情况,告诉客户端数据块应该存储在哪些 DataNode 上。
- 客户端将数据块先写入主DataNode,DataNode 再将数据块副本同步写到其他 DataNode 上。
- 完成第一个数据块后。客户端通知 NameNode 数据块已成功写入。NameNode 更新数据块的时间戳,最终大小等。再写入 editlog。

写入流程part2
- 客户端再向 NameNode 获取第二个数据块该写到哪些个 NameNode 上,重复上面的操作,直到全部写完。
- DataNode 将数据块存储在本地文件系统后,会定期向 NameNode 汇报数据块状态。

datanode定期上报状态
- NameNode 将文件的元数据变化记录到 NameSpace EditLog 中。并定期合并 EditLog 到 FsImage,以确保文件系统状态一致。
- 备用 NameNode 会同步 EditLog 和 FsImage,以便在故障时可以接管。

备用namenode
通过上面步骤,HDFS 完成写入大文件。我们再来看下怎么将大文件读出来。
读大文件
- 客户端向 NameNode 发送请求以获取目标文件的元数据信息。NameNode 返回文件的 block 列表及其对应的 DataNode 位置。
- 客户端根据 NameNode 返回的 DataNode 列表,选择一个合适的 DataNode ,建立 TCP 连接,并发送读取 block 的请求。
- DataNode 收到请求后,将 block 数据发给客户端。客户端接收数据后,用 checksum 校验数据完整性。
- 重复以上步骤读取到多个数据块后,将多个数据块组装成大文件,完成读取。

读大文件
现在大家通了吗?
最后
其实大部分后端开发平时不怎么使用 HDFS,但我却不得不聊下它,它是大数据体系的基石。基于 HDFS 的中间件有很多,比如 Hbase, Hive, Spark 等等,随便拉出一个来,都是王炸。就算不用,我们也可以学习下它们是怎么解决架构问题的。这在面试上拿出来吹牛,还不是嘎嘎乱杀?
总结
- 你可以将 HDFS 当做 应用服务和多个服务器文件系统的中间层,帮应用屏蔽掉背后的多个服务器,从多个服务器上读写文件数据,
- HDFS 会将文件分为多个数据块,并给数据块配备多个副本,有效利用磁盘空间的同时,还提升了数据可靠性。
- HDFS 将集群分为 NameNode 和 DataNode 两部分,NameNode 负责管理文件元数据,DataNode 负责正在存储数据块。
- NameNode 的内存中主要包含 NameSpace 和 block manager 两部分,NameSpace 负责管理目录树和元数据的组件。Block manager 维护和管理数据块被存在了哪个 DataNode 上。这些内存数据会刷入磁盘上的 fsimage 文件中形成快照,并通过 editlog 记录用户写操作,确保数据不丢
- NameNode 将 NameSpace 和 block manager 加载到内存中,保证高性能。同时将内存数据会刷入磁盘上的 fsimage 文件中形成快照,并通过 editlog 记录用户写操作,确保数据持久化。为 NameNode 加入备用节点,保证高可用。通过 Federation 方案,提升了系统扩展能力。