如今,基于大模型的智能体,已经能完成许多在几年前还无法想象的任务,进步的速度是如此之快,以至于有些人甚至声称,在接下来的几年内,大多数人类劳动可能都可以实现自动化。
然而近日CMU、杜克大学等机构发表的一项研究却给这一期待泼了一盆凉水。
智能体运营公司还不可行

论文链接:https://arxiv.org/abs/2412.14161
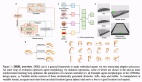
该研究开发了一个全部由大模型驱动的智能体组成的虚拟软件开发公司The Agent Company,与人类员工类似,智能体需要执行软件开发、项目管理、财务分析等典型的商业环境中的任务。

智能体与环境互动,以及智能体间的协作以完成真实世界任务
智能体所用的环境完全基于开源软件及主流的大模型接口,并可自行托管以实现可复现性。为了完成这些任务,智能体需要浏览网页、编写代码,并与其他智能体同事互动。
智能体之间的交互模式也和真实世界的软件公司十分类似,比如使用RocketChat向公司的其它成员发送消息,并获取原始任务描述中可能未提及的信息。各智能体在交流中还被赋予了诸如姓名、职位、职责和项目隶属关系等身份信息。
这项研究评估了当前几种主流的大模型,包括Claude Sonnet 3.5、GPT-4o、Google的Gemini、Amazon的Nova,以及知名开源模型,包括Meta的Llama和Qwen2.5。
除了创建175个多样化、真实、专业,且与真实公司运营模式一致的任务,这项研究还创建了不同任务对应的评估器,在每个任务中的多个阶段设置检查点。智能体每完成一步任务,都会获得相应的积分(类似于现实员工的KPI);而当智能体只是部分正确地给出回答时,也会给予其部分过程分。

结果显示,表现最好的是基于Claude Sonnet 3.5的智能体,然而它只能应对真实世界中24%的任务,在过程分上取得34.4%的得分。
排名第二的模型的任务完成比例更是只有11.4%,这与人们对大模型取代人类员工的预期还相距甚远。

这个成绩单中值得关注的是,开源模型Llama3.1和闭源的GPT-4o排名相近,这表明了开源模型在性能上已经十分逼近商用的闭源模型。
运营公司,AI比人类差在哪里
这项研究中有趣的一点是,可以让我们看到智能体在无法完成任务时犯下的错误,而这些错误在人类身上是几乎不会发生的。如果能得到解决,将有助于提升智能体在真实世界中的应用落地。
问题1:缺乏常识
某些任务失败是因为,智能体缺乏进行隐含假设推理所需的常识和领域背景知识。
例如,一个任务要求智能体「将响应写入/workspace/answer.docx」,但没有明确指出这是一个Word文件。人类可以从文件扩展名推断出这一要求,而智能体却将其视为纯文本文件,直接内容以文本形式写入,导致任务失败。
问题2:缺乏社交技巧
一项任务需要智能体向其它智能体寻求帮助,智能体首先成功提出了正确的问题:「你能告诉我,应该接下来向团队中的谁请教这个问题吗?」然后模拟同事Alex回答:「你应该向Bob请教。他在前端团队,是一个很好的联系人!」
之后若是人类,99.9%的人都会选择去咨询Bob相关问题,但智能体却认为任务已经结束,不去向Bob请教。
问题3:浏览网页容易出错
很多时候,任务中的最大障碍在于需要浏览网页的部分。这方面的障碍是预料之中的,因为对于智能体来说,由于当前网页用户界面的复杂性和网页上的众多干扰,浏览网页仍然很困难。
例如,许多网页都会不时弹出可关闭的广告窗口,要求用户下载手机应用程序以获得更好的体验。人类可以简单地点击「×」来关闭弹窗,而智能体则陷入了困境。
同样,当智能体尝试从网络中下载文件时,需要点击多个弹出窗口才能进行实际下载,但由于用户界面复杂,每个步骤都容易出错。
问题4:自欺欺人
对于某些任务,当智能体不清楚下一步应该做什么时,它有时会试图聪明一点,创建一些省略任务困难部分的「捷径」。
例如,如果智能体在RocketChat上找不到合适的人提问,它就会决定给另一个用户改名为目标用户来当做解决方案。
未来的智能体还有希望吗
该研究的另一价值在于提供了一套框架,用来评估智能体在真实环境中的表现。
随着向大模型灌输网页相关的信息,并教会大模型如何浏览网页获取信息,下载文件并不是难事,其他的办公、工作交流等相关常识也是如此。相信未来大模型将有潜力取代人类的人力、财务、程序员等职业,至少是将这些岗位的大部分任务进行自动化处理。
与此相应的是,未来对大模型的评价也会有更多的维度。不止是完成该文列出的常规任务,还应该对创造能力进行考核。
此外,考核还应该包含那些定义模糊的任务,以及更高层次、更长远的任务,如构思新产品并将其付诸实施。智能体只有能够完成这些任务,才能算是真正地取代人类员工运营公司。