













最近,ByteDance Research 的视频理解大模型眼镜猴(Tarsier) 迎来了巨大更新,发布了第二代模型 Tarsier2 及相关技术报告。研究团队此前发布的 Tarsier-7B/34B 在视频描述领域已经是最强开源模型,仅次于闭源模型 Gemini-1.5-Pro 和 GPT-4o。那么这次新版 Tarsier2 又会带给我们什么样的惊喜呢?
直接上强度!来看看 Tarsier2 对下面这两个影视名场面的理解如何:
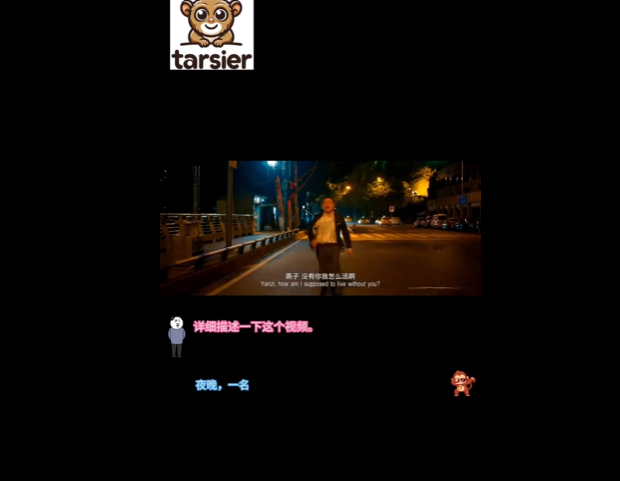
《燕子,没有你我怎么活》

《曹操盖饭》
可以看到,Tarsier2 不仅对于视频中人物动作捕捉得细致入微(如小岳岳追车、跪地,曹操盖饭、挥手),还可以充分结合视频中的字幕信息,从而进一步分析人物的动机 / 心理,理解人物关系和情节发展。
既然如此复杂的影视片段能够分析清楚,Tarsier 最擅长的视频描述任务自然也不在话下:

Tarsier2 视频描述效果合集
无论是真人还是动画、横屏还是竖屏、多场景还是多镜头,Tarsier2 总是能敏锐地捕捉视频中的核心视觉元素及动态事件,使用简练的语言表述出来,并且很少产生幻觉。这么看来,Tarsier2 已经可以和 GPT-4o 扳一扳手腕了。

“火眼金睛” 是怎么炼成的?
Tarsier2 是一个 7B 大小的轻量级模型,支持动态分辨率,能够看得懂长达几十分钟的视频,尤其擅长对几十秒的短视频片段进行分析。研究团队公开了详尽的技术报告,相关数据、代码和模型也在持续开源中:

- 论文地址:https://arxiv.org/abs/2501.07888
- 项目仓库:https://github.com/bytedance/tarsier
- HuggingFace:https://huggingface.co/omni-research
Tarsier2 强大的视频理解能力主要得益于预训练和后训练两个阶段的精益求精。
预训练
Tarsier2 在 4000 万个互联网视频 - 文本数据上进行预训练。不同于文本模型只需要互联网上的单语语料就可训练,视频理解模型严重依赖高质量的视频 - 文本对齐数据。因此,如何大规模地获取对齐数据是模型训练的最大难点。团队主要通过以下两个途径来解决:
- 数据收集方面:Tarsier2 海量收集互联网上的视频 - 文本数据。这些数据分布广泛,涵盖电影、电视剧、短视频等各种来源,涉及人机交互、自动驾驶等多个领域。值得一提的是,Tarsier2 筛选了一大批影视剧解说的视频。这些视频不仅能够帮助模型学会简单的动作、事件,还能辅助模型理解更高层次的情节信息。
- 数据筛选方面:Tarsier2 设计了一套严谨的流程,来筛选高质量训练数据。每条数据都会经历 “分镜 → 过滤 → 合并” 3 个阶段。“分镜” 阶段,视频会被切分成多个单一镜头片段;“过滤” 阶段针对不同的数据使用不同的模型过滤低质数据,如过滤掉动态性太差的、文本和画面无关的等;“合并” 阶段再将剩下的相邻的视频片段合在一起,增加视频的复杂度。
后训练
后训练分为 SFT 和 DPO 两个阶段。
SFT:这一阶段,模型在人工标注的视频描述数据上进行训练。这个阶段的描述数据也是大有讲究。Tarsier2 提出在视频描述中引入针对每个子事件的具体定位信息(即明确每个事件源自哪些帧),以强化模型对时序信息与视觉特征的关注度,增强文本与视觉信号的对齐。

SFT数据样例
DPO:这一阶段,模型在自动化构造的正负样本上进行 DPO 训练。其中,正样来源于模型对原始视频的预测结果;负样本来源于模型对经过预先设计的随机扰动的视频的预测结果。这种直观高效的构造方式使得模型能够在描述视频时,“又准确又全面”,减少描述中存在的幻觉。
是骡子是马,牵出来溜溜!
俗话说,“光说不练假把式”,Tarsier2 在多达 19 个视频理解公开基准上进行了性能测试,和最新最强的 10+ 个开源模型(Qwen2-VL、InternVL2.5、LLaVA-Video 等)以及闭源模型(Gemini-1.5, GPT-4o)来了场 “硬碰硬”。
Tarsier2 在包括视频描述、短 / 长视频问答在内的通用视频理解任务上表现亮眼。在视频描述评测集 DREAM-1K 上,Tarsier2 相比 GPT-4o 提升 +2.8%,相比 Gemini-1.5-Pro 提升 +5.8%;在人工评估中,Tarsier2-7b 相比 GPT-4o 优势占比 +7.8%,相比 Gemini-1.5-Pro 优势占比 +12.3%。

视频描述质量人工评估结果
此外,Tarsier2 更是在 10+ 个视频理解公开榜单上,超越了 Qwen2-VL-7B、InternVL2.5-8B 等同规模的模型,取得了 SOTA 成绩:

Tarsier2在广泛的视频理解任务上树立了新的标杆
除了胜任各种通用视频理解任务,Tarsier2 作为基座模型在机器人、智能驾驶等下游任务场景中也展现出了极强的泛化能力。在机器人领域,Tarsier2 能为指定的任务生成详细的步骤指令。在智能驾驶方面,Tarsier2 也能够帮助车辆识别道路情况,并辅助进行决策。

机器人场景。

智能驾驶场景。
向更强的智能进发
Tarsier 在生成详细且准确的视频描述方面超越了现有的闭源和开源工作,更是在广泛的视频理解任务中树立了新的标杆。文本、语音、图片、视频多模态深度融合是当下人工智能发展的核心趋势与关键方向,Tarsier2 在这条道路上已经迈出了坚实的步伐。期待未来 Tarsier2 能在多模态融合的浪潮中持续领航,为人工智能的发展带来更多惊喜与突破 。


















