在MySQL数据库中,优化查询性能是每个开发人员和数据库管理员都需要面对的重要挑战之一。其中,EXPLAIN关键字是一个强大的工具,可以帮助我们深入了解MySQL是如何执行查询的,以及如何优化查询性能。
本文将深入探讨MySQL中的EXPLAIN关键字,探究其背后的工作原理和输出信息含义。通过本文的阐述,您将了解如何解读EXPLAIN的输出结果,优化查询执行计划,提升数据库性能,以及避免常见的查询性能陷阱。
无论您是初学者还是有经验的数据库专家,本文都将为您提供有价值的见解和实用的技巧,助您在MySQL数据库中更好地利用EXPLAIN关键字,优化查询性能,提升数据库应用的效率和稳定性。

详解explain对应关键字
通过explain关键字可以获取我们给定查询SQL经由成本和规则优化后的执行计划,通过这个计划我们可以得到查询语句实际的工作步骤,这里我们就针对这关键字得出的执行计划的每一列都进行介绍。
为了更直观的演示explain各个关键字段的信息,我们这里不妨通过两张表针对每一种访问方式进行讲解,对应数据表的DDL如下所示,可以看到笔者创建了一张s1表,其中:
- id作为主键。
- key1作为普通索引。
- key2是唯一索引。
- key_part1+key_part2+key_part3构成唯一索引。
s2与s1结构一致,这里就不多做介绍,对应DDL语句如下所示:
id字段
针对每一个select语句都会为其分配一个id字段,该id就代表的每一个select语句的执行计划信息。
我们先说个简单的例子,针对下面这句单表执行的语句,它就只有一行数据,所以就只有一个id为1的执行计划:

我们再来一个union合并查询:
从执行计划可以看到s1的id为1,s2的id为2,分别进行了一个select查询:

需要注意的是连接查询的驱动表和被驱动表的id都是一样的,出现在前面的是驱动表,而后面的就是被驱动表:
从执行计划就可以看出,s1就是驱动表,s2就是被驱动表:

我们再来一个特殊的SQL,这句原本是子查询,正常情况下应该是s1表的id为1,s2表的id为2:
但是SQL优化器经过分析发现这句可以被优化为连接查询,即下面这句SQL:
所以执行计划就显示id是一样的,且s1作为驱动表,s2作为被驱动表:

table字段
table字段含义比较简单,它表示当前查询计划所针对的数据表,例如下面这个简单查询语句:
它所查询的就是针对s1表:

而下面这句涉及连接查询,所以从执行计划中也能看出不同执行计划所针对的表:
可以看到驱动表s1进行全表扫描,而被驱动表s2是通过hash join进行连接查询:

select_type
select_type决定了你的SQL涉及的查询类型,常见的有:
(1) SIMPLE:简单查询,如下所示,可以看到简单的SQL语句就属于这种查询类型
对应的执行计划如下所示:

(2) PRIMARY:涉及关联或者子查询的语句对应左边的语句就是PRIMARY,如下SQL所示,可以看到对应的u表的查询就可以作为PRIMARY语句:
我们查看执行计划的截图,可以看到涉及这种嵌套查询的SQL左边的SQL就是PRIMARY:

(3) UNION:从执行计划的截图就可以看出union关键字后面的SQL就属于union
对应执行计划如下图所示:

(4) UNION RESULT:包含union的处理结果集,在union和union all语句中,基于其它查询结果进行合并(可能有去重的过程),需要通过一个临时表才能完成的操作就是UNION RESULT也就是我们上述那句SQL的第三步。
(5) DEPENDENT SUBQUERY:如下SQL所示,在SQL优化器明确指明子查询无法转为半连接查询的情况下,第一个select的子查询对应的select type就是DEPENDENT SUBQUERY:
对应的执行计划如下所示,可以看到s2的执行类型就是DEPENDENT SUBQUERY:

(6) DEPENDENT UNION:如下SQL所示,在涉及union的子查询中有无数个小查询,除去union的左边哪个小查询,其余的都是DEPENDENT UNION
这一点,从执行计划中就可以看出,子查询内部的s2查询的类型就是DEPENDENT UNION

(7) DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生);MySQL会递归执行这些子查询, 把结果放在临时表里:
对应的我们可以在执行计划中印证这一点:

type字段(重点)
type决定了进行SQL查询的时的访问方法,该字段对于SQL执行性能分析有着至关重要的参考价值:
(1) system:表中只有一行或者空表,即存储引擎中统计的数据是正确的。
(2) const:基于聚簇索引或者非空的唯一二级索进行定位数据,时间复杂度为O(1),这种高速的常量级查询我们就可以称为const:
对应执行计划如下:

(3) eq_ref:该查询意味着进行关联查询时,被驱动表内部走了聚簇索引或者非空的二级索引查询:
(4) ref:通过那些非唯一的二级索引进行精准定位,这种在二级索引区间构成一个扫描区间进行定位,然后再通过回表获取所有数据的执行就是ref:
对应的执行计划截图如下图所示:

(5) fulltext:全文匹配,大字符索引匹配。
(6) ref_or_null:基于普通二级索引查询且查询时还需要查询可能为空的情况:
(7) unique_subquery:即子查询被优化为exist,且子查询返回的是聚簇索引:
(8) index_subquery:和上述查询类似,只不过子查询内部返回的是普通二级索引:
(9) range:范围查询。
(10) index_merge:索引合并,即进行SQL查询时对应的条件都是索引类型,SQL优化器进行查询时让两个索引分别到自己的二级索引树拿到有序的id集合然后取交集得到聚簇索引值进行回表:
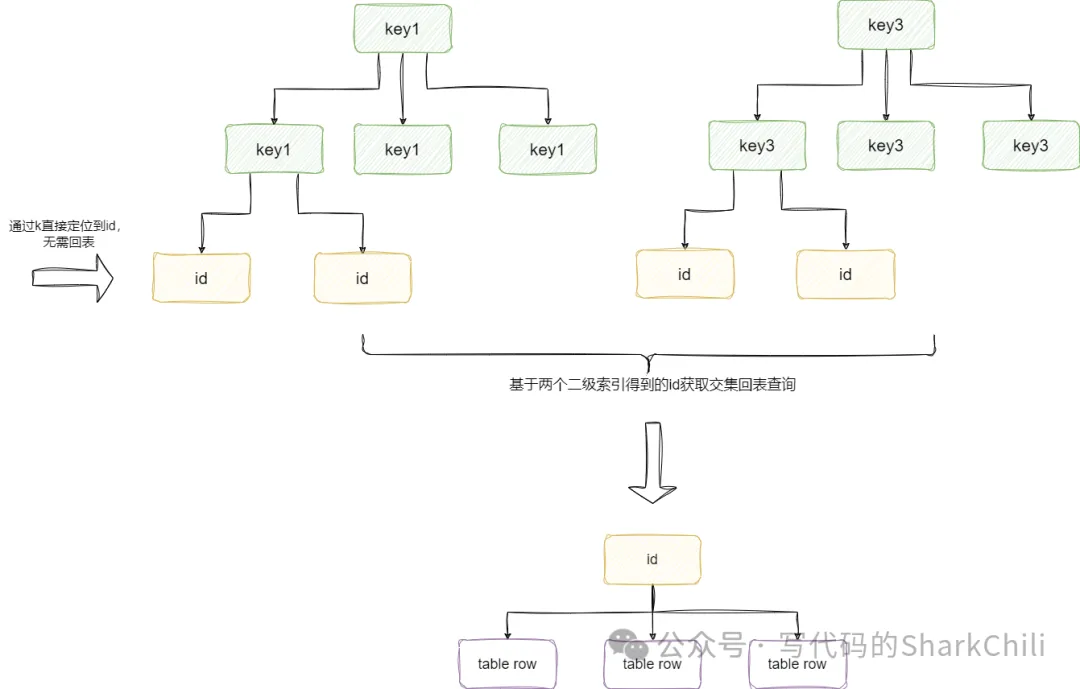
对饮的SQL如下,可以看到我们查询条件都走了索引,查询结果是基于多个索引的扫描区间共同构成的聚簇索引,然后取并集进行回表:
这一点我们可以通过查询执行计划印证: +
(11) index:如下SQL所示,查询时基于联合索引,但不符合最左匹配原则,所以需要进行全索引扫描匹配key_part2,但查询时无需回表,这种基于二级索引全扫描但无需回表的访问方法就是index:
对应执行计划如下图所示:

(12) ALL:全表扫描。
extra
这个字段也很重要,它表示当前SQL语句的一些额外的信息:
- Using filesort:即代表SQL查询时用到了文件扫描,使用了外部的索引进行排序,并没有用到我们自己定义的索引,性能较差。
- using index:这种方式性能就不错了,使用了索引并且不需要回表就得到了我们需要的数据,即用到了索引覆盖。
- Using temporary:MySQL查询排序时使用了临时表性能较于filesort更差。
- using where:即代表查询时仅仅用到了普通的where条件,并没有用到任何索引,查询需要在server层进行判断。
- Using join buffer:在进行连接查询时,被驱动表的数据定位并没有走索引,于是将驱动表的数据放入缓冲区进行关联匹配。
- impossible where:说明where条件基本得不到需要的结果,筛选数据时一直处于false的状态。
possible_keys
表示当前查询可能用到的索引。如下这个执行计划,它就以为着可能用到了主键

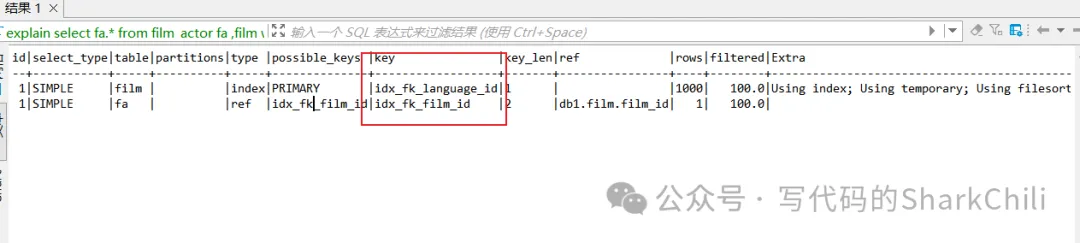
key(用到的索引名称)
表示用到的索引名称,如下所示下面这条sql可能就用到了这两个索引。
key_len
key_len表示使用索引时,对应使用到的索引的长度,在MySQL的EXPLAIN语句中,key_len列表示使用索引的键部分的字节数。它是一个估计值,根据查询中使用的索引类型和数据类型来计算。通常,key_len越小,性能就越好,因为它意味着需要读取更少的数据块。 例如,如果你有一个使用VARCHAR(100)数据类型的列作为索引,并且查询中只使用了前10个字符作为搜索条件,则key_len将是10。如果你使用的是INT(10)数据类型的列作为索引,则key_len将是4,因为INT类型占用4个字节。 在优化查询时,理解key_len可以帮助你确定哪些索引可以更有效地支持查询,以及如何进一步优化索引设计。
例如下面这一句,实际上索引长度就是303,原因很简单:
- key1为varchar(100)且用的是utf8,所以长度为300字节。
- 允许空再加一个字节。
- varchar需要2字节维护长度进行再加2字节。 最终得到303字节:
ref
表示进行索引匹配时,与之比对的数据类型,例如下面这句key1比对的是一个函数计算值,所以ref是func:
例如这句与索引匹配的是常数,所以得到的是const:
当然进行关联查询时被驱动表得到的就是驱动表的id,如下返回的就是s1.id:
rows
rows意味着我们查询时大体需要扫描多少行,对于单表查询没什么,但是对于多表查询,从这个数据我们可以得知关联查询哪个作为驱动表:
因为cb的rows为1,可知这张表变为被驱动表走索引定位:
filter(读取和过滤占比)
表示选取的行和读取的行占比,例如下面这句SQL:
从笔者执行计划来看,可能会扫描49902,只有大约10%的符合要求:

该查询在单表查询中没有太大意义,但是在连接查询中就比较有参考价值了,例如下面这句SQL:
从执行计划可以看出s1作为驱动表大约扫描99805列数据,有10%符合要求,而被驱动表s2过滤值为1和100%比例,这意味着针对被驱动表的查询次数可能是99805*0.1大约9980次。
小结
通过本文的探索,我们深入了解了MySQL中的EXPLAIN关键字的重要性和作用。EXPLAIN不仅可以帮助我们分析查询执行计划,还可以为我们提供优化查询性能的关键线索。
通过解读EXPLAIN的输出结果,我们学会了如何识别潜在的性能瓶颈,并优化查询以提高数据库的效率和响应速度。了解索引的使用、表连接顺序以及访问类型等信息,能够帮助我们更好地优化查询并避免常见的查询性能问题。
在实际应用中,不断深入学习和理解EXPLAIN的输出结果,结合实际场景进行优化实践,将为我们的数据库应用带来明显的性能改善和优势。通过不断优化查询性能,我们可以提升数据库系统的整体效率,提供更好的用户体验和服务质量。
在今后的数据库开发和维护工作中,让我们继续积极运用EXPLAIN关键字,不断优化查询执行计划,提升数据库性能,为应用程序的稳定性和可靠性打下坚实的基础。