













1 月 24 日消息,Hugging Face 平台昨日(1 月 23 日)发布博文,宣布推出 SmolVLM-256M-Instruct 和 SmolVLM-500M-Instruct 两款轻量级 AI 模型,在 AI 算力有限的设备上,最大限度发挥其算力性能。
IT之家曾于 2024 年 11 月报道,Hugging Face 平台发布 SmolVLM AI 视觉语言模型(VLM),仅有 20 亿参数,用于设备端推理,凭借其极低的内存占用在同类模型中脱颖而出。
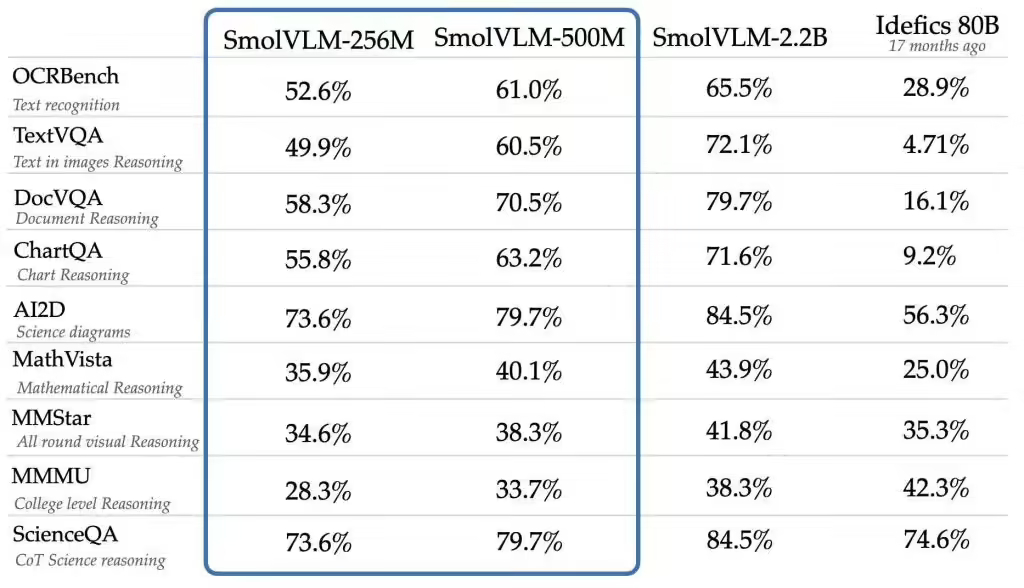
本次推出的 SmolVLM-256M-Instruct 仅有 2.56 亿参数,是有史以来发布的最小视觉语言模型,可以在内存低于 1GB 的 PC 上运行,提供卓越的性能输出。
SmolVLM-500M-Instruct 仅有 5 亿参数,主要针对硬件资源限制,帮助开发者迎接大规模数据分析挑战,实现 AI 处理效率和可访问性的突破。
SmolVLM 模型具备先进的多模态能力,可以执行图像描述、短视频分析以及回答关于 PDF 或科学图表的问题等任务。正如 Hugging Face 所解释的:“SmolVLM 构建可搜索数据库的速度更快、成本更低,其速度可媲美规模 10 倍于其自身的模型”。
模型的开发依赖于两个专有数据集:The Cauldron 和 Docmatix。The Cauldron 是一个包含 50 个高质量图像和文本数据集的精选集合,侧重于多模态学习,而 Docmatix 则专为文档理解而定制,将扫描文件与详细的标题配对以增强理解。
这两个模型采用更小的视觉编码器 SigLIP base patch-16/512,而不是 SmolVLM 2B 中使用的更大的 SigLIP 400M SO,通过优化图像标记的处理方式,减少了冗余并提高了模型处理复杂数据的能力。
SmolVLM 模型能够以每个标记 4096 像素的速率对图像进行编码,这比早期版本中每标记 1820 像素有了显著改进。


























