












DeepSeek(深度求索)再次推出新版开源AI模型,它的性能与美国最先进的AI模型虽然还有一些差距,但差距极小,成本低很多很多。西方许多人认为,美国限制中国AI发展的企图遇挫,中国正在加速前进,以更高效率打造高端AI模型。
去年12月,杭州幻方量化推出DeepSeek V3开源大语言模型,它的性能与OpenAI 40和Anthropic Claude 3.5 Sonnet差不多,当时OpenAI和Anthropic正在开发下一代模型。按照描述,V3的成本只有560万美元!要知道OpenAI、谷歌、Anthropic为了搭建、训练模型花费数亿美元,未来可能达几十亿。

Andrej Karpathy曾经说过,V3的投资“低得有些荒谬”,在资源受限的条件下,无论是研究还是工程,都取得了令人惊叹的成就。
DeepSeek创始人、CEO、幻方量化创始人梁文锋去年曾说:“对我们而言钱不是问题,先进芯片受限却是一个问题。”
V3是用Nvidia H800芯片训练的,它比美国版本性能弱一些,之后美国连Nvidia H800也禁了,不能向中国出售。
有人将同一时间发布的DeepSeek-R1-Zero和DeepSeek-R1进行了对比:
——DeepSeek-R1-Zero的优势:它具备创造性推理能力,擅长独立发现独特、创造性的推理策略。拥有自我验证与反思能力,可以验证自己的推理,在处理时进行反思,能有效进行长链思维。
——DeepSeek-R1的优势:可读性高,精准,模型输出的结果是可读的,更精致,出错率低。性能方面有强大竞争力,与最顶级的OpenAI模型可以一较高下,无论是数学、编程还是逻辑推理,都不逊色。
——DeepSeek-R1-Zero的弱点:输出有时会重复,显得杂乱,对用户不够友好,有时很难解释输出的结果。
相比较而言,DeepSeek-R1给出的结果更精致、更可靠,更加具有一致性。DeepSeek-R1-Zero在AI研究领域具有突破性意义,它向我们证明,单靠增强学习就能学会推理,不需要人类引导,这对AI发展来说具有里程碑意义。
R1是以Zero作为基础开发的,它将SFT和SR结合在一起,在性能、与人类偏好保持一致两个方面达到了平衡,更适合现实应用。

接下来让我们看看外媒都是如何评价的:
Venturebeat:中国企业戏剧性后来居上
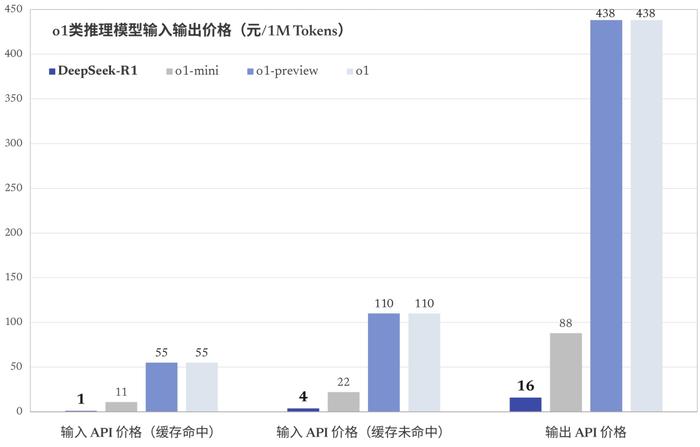
最新的DeepSeek-R1性能与OpenAI开发的o1差不多,无论是数学、编程还是推理,都很出色。最让人吃惊的依然是成本,DeepSeek-R1的成本比o1低90-95%。
DeepSeek-R1的出现标志着开源模型取得了重大进步。它告诉我们,开源模型与闭源模型的差距正在缩小,二者将同时向AGI迈进。
报告显示,DeepSeek-R1在AIME2024数学测试中取得79.8%的成绩,与OpenAI o1的79.2%水平相当。在Codeforces测试中达到了2029的评分,超过96.3%的人类程序员(o1约为96.6%)。
英伟达高级科学家Jim Fan第一时间发表评论称,OpenAI的目标本来是开发真正开源、具有前沿性的AI模型,但现在这一目标却被一家非美国企业达成,最戏剧性的结果可能已经出现。在X平台上,他的评论目前已经被阅读106万次。
OpenAI o1的每百万tokens输入成本约为15美元,每百万tokens输出成本为60美元,DeepSeek Reasoner(基于R1模型)分别只有0.55美元和2.19美元。
Arstechnica:在硬件上进行本地处理将会实现
R1模型与其它大语言模型有着不同的运行机制,用到了所谓的“Inference-time reasoning approach”,也就是在模型推理阶段进行逻辑推理,这种推理方式和人类极为相似,又叫“模拟推理”(SR)。虽然SR推理给出回应时会慢一点,多耗费一点时间,但面对数学、物理、科学任务时结果更好。
不只是DeepSeek,中国的阿里巴巴、Kimi也都发布可以媲美o1的模型。
乔治梅森大学(George Mason University)AI研究人员Dean Ball说:“DeepSeek的小模型(distilled model,也就是R1的小号版本)性能让人惊叹,未来将会出现一大批推理能力不错的模型,它们可以在本地硬件上完成处理。”
forexlive网站:相当于30美元的iPhone问世
回想2017年时苹果推出iPhone X,售价999美元,手机狂卖,让苹果生态系统迅猛扩张。我们假设一下,如果有一家公司,它推出一款手机和一个手机平台,各方面更强,但价格只有30美元,会怎样?
没错,今天的AI世界正在发生这种戏剧性的变化。中国DeepSeek开源模型的性能居然追上了o1,但成本却低很多。不只如此,你还可以下载,免费使用。
无论是规模还是效率,R1取得了巨大进步,它改变了我们预期。我们曾经认为AI革命需要大量算力和电力,现在看来并非如此。就在新模型发布前几小时,特朗普刚刚宣布要投资1000亿美元在美国建设数据中心,同时还宣布与三家科技巨头开展5000亿美元AI项目.
DeepSeek告诉我们,在训练基本模型时有完全不同的可行方法,它们的效果同样好,但成本低无数倍。R1的到来可以让更多应用程序落地,之前这些程序因为成本过高不能推向市场,未来AI会在实体经济中有更大规模的应用。(小刀)




















