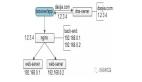
衡量一个架构设计的好坏,其中一个标准就是看这个架构是否具有可扩展性,架构设计中有很多常用的实现扩展性的技术,这次我们就来探讨一下比较常见的 SPI 技术。
我们首先了解一下什么是 SPI,然后讲一讲 JDK 是如何基于 SPI 机制来获取到具体的数据库驱动实现的。接下来,我们分析 JDK SPI 机制的不足之处。最后,概要讲解一下 Apache Dubbo 对 SPI 进行了哪些改进,以及 Apache Dubbo 是如何基于增强 SPI 实现 Dubbo 框架的可扩展性的。
服务提供者接口(Service provider interface,SPI),是指被第三方实现或者扩展的接口,它可以用来实现框架的扩展性和实现组件的可替换性。这里服务提供者接口中的服务是指一组接口和抽象类,服务提供者基于服务提供者接口来实现具体的服务。
JDK 中的 SPI 机制
了解了 SPI 的基本定义,我们接下来看一下 SPI 是如何在 JDK 中使用的。在 Java 开发中,我们经常使用下面这段代码来获取一个数据库连接。
DriverManager.getConnection("a database url of the form jdbc:subprotocol:subnam");比如获取 MySQL 数据库连接,我们可以用如下代码来操作:
DriverManager.getConnection("jdbc:mysql://localhost:3306/testDb?useUnicode=true&characterEncoding=UTF-8");或者要获取 Oracle 数据库连接,对应代码如下所示:
DriverManager.getConnection("jdbc:oracle:thin:@localhost:3306:testDb");获取完数据库连接后,我们该怎么用呢?
基于 MySQL 数据库的示例,下面这段代码就展示了如何基于连接做数据库表的操作:
public static void main(String[] argc) throws SQLException {
Connection con = null;
try {
//1. 获取 MySQL 数据库连接
con = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/testDb?useUnicode=true&characterEncoding=UTF-8");
//2. 执行 SQL 语句
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM table");
//3. 处理结果集数据
while (rs.next()) {
String name = rs.getString("name");
String desc = rs.getString("desc");
System.out.println(name + ", " + desc);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//4. 关闭连接
if (con != null) {
con.close();
}
}我们先获取到 MySQL 数据库的一个连接,然后基于连接执行查询操作,接着处理查询操作返回的数据集,处理完毕后关闭连接。
从上面示例可知,DriverManager.getConnection 方法根据传递的 database url 不同,可以获取不同数据库的连接,也就是说 DriverManager.getConnection 方法是与具体的数据库驱动实现无关的。这是一个很好的设计,那么它是如何实现的呢?
首先,我们来剖析下 DriverManager.getConnection 的实现机制,我们列出来 DriverManager.getConnection 相关的类图模型:
java.sql.Driver 文件的内容如下图:
 图片
图片
Oracle 驱动包中 META-INF/services/java.sql.Driver 文件的内容如下所示:
 图片
图片
从 META-INF/services/java.sql.Driver 文件找到具体驱动的实现类的名称后,会调用 ServiceLoader 内的 nextService 方法,使用 Class.forName(“驱动实现类名称”…)来创建这个驱动的 Class 对象,然后通过 Class 对象的 newInstance() 方法创建一个驱动实现类的实例对象。
private S nextService() {
...
// 创建驱动实现类的 Class 对象
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
...
// 基于驱动实现类的 Class 对象创建一个实例对象
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
...
}
}另外,我们会发现具体的驱动实现类,比如 MySQL 驱动的 Driver 类内,存在一个 static 的代码块。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
// 注册 MySQL 驱动到 DriverManager
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}这个 static 代码块会在创建 Driver 的实例对象时被触发执行,而上面 ServiceLoader 类的 nextService 方法内就创建了 Driver 的实例,所以触发了 Driver 类的 static 代码块执行,也就是把 Driver 类注册到了 DriverManager 中的 registeredDrivers 列表里面。
到这里,我们讲解了 DriverManager.getConnection 内的一部分逻辑,也就是 loadInitialDrivers 方法的逻辑。它的内部使用 ServiceLoader 扫描 classpath 下所有的 jar 包,并找到实现 Driver 接口的驱动包,然后注册驱动实现类到 DriverManager。
上面我们讲解了如何注册驱动到 DriverManager,下面我们继续看当 DriverManager.getConnection 获取数据库连接时,如何使用驱动来具体获取数据库连接的:
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException{}
...
// 遍历 registeredDrivers
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
// 从驱动获取连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
}
...
}
...
}
}由上面代码可知,getConnection 方法内会遍历 registeredDrivers 中的驱动实现类,然后调用驱动实现类的 connect 方法,每个驱动实现类的 connect 方法根据 URL 来判断当前请求的 URL 是否需要自己处理,如果不需要就返回 null,否则返回具体的连接对象。
总的来说,JDK 对数据库驱动进行了抽象,提供了 SPI 接口 Driver 和 Connection。然后,驱动开发者就可以实现这个 SPI 接口,来提供具体数据库的驱动实现包。驱动开发者提供的驱动包里面需要包含 META-INF/services/java.sql.Driver 文件,并且文件内要写入驱动实现类的类名。
JDK 提供的 ServiceLoader 机制会扫描 classpath 下的所有 jar 包,并且找到含有 META-INF/services/java.sql.Driver 文件的 jar,判定它为数据库驱动包,然后 ServiceLoader 会根据实现类的名称实例化这个驱动实现类,并注册驱动实现类到 DriverManager 内。当我们调用 DriverManager 的 getConnection 方法时,就可以获取到具体的驱动实现类并获取数据库连接了。
请注意,在 JDK 的 SPI 机制实现中,ServiceLoader 会把所有驱动实现包中的驱动实现类都实例化(创建一个对应的实例对象)。如果某些驱动实现类初始化很耗时,实例化会很浪费资源,并且会降低应用启动速度。
Dubbo 中的 SPI 机制
Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案。
Dubbo 的 SPI 实现借鉴了 JDK 的 SPI 思想,但是进行了一些优化改进,解决了 JDK SPI 的以下问题:
- JDK SPI 会一次性实例化所有实现类,有的扩展实现类初始化很耗时,但实际又没用,还会拖慢启动速度;
- JDK SPI 在实例化扩展实现类失败时,不会友好地通知用户具体异常。
Dubbo SPI 增加了对扩展实现类的 IoC 和 AOP 的支持,一个扩展实现类可以直接注入其它扩展实现类,也可以使用 Wrapper 类对扩展实现类进行功能增强。
Dubbo 框架的实现采用了分层架构思想,架构中的每层都是一个独立模块,上层依赖下层提供的功能,下层对上层提供服务,下层的改变对上层不可见。
 图片
图片
在这个架构图中,从上往下看,除去 Service 和 Config 层是 API 层外,剩下的从 Proxy 层到 Serialize 层都是 SPI 层,这意味着从 Proxy 层到 Serialize 层每层都是可扩展的、可被替换的。
比如,Cluster 层默认提供了丰富的集群容错策略,但是如果开发者有定制化需求,可以通过 Dubbo 提供的 SPI 扩展接口 org.apache.dubbo.rpc.cluster.Cluster 提供个性化的集群容错策略,其中 SPI 接口 org.apache.dubbo.rpc.cluster.Cluster 的定义如下:
@SPI("failover")
public interface Cluster {
@Adaptive
<T> Invoker<T> join(Directory<T> var1) throws RpcException;
}我们通过 CustomCluster 类实现了 SPI 接口——Cluster,其中 CustomClusterInvoker 为具体的容错策略的实现。
public class CustomCluster implements Cluster {
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new CustomClusterInvoker<>(directory);
}
}创建好 CustomCluster 类后,我们需要在 resources 目录下创建一个名称为 META-INF.dubbo 的文件夹,然后在它的下面创建一个名为 org.apache.dubbo.rpc.cluster.Cluster 的文件,文件内容为:customCluster=org.apache.dubbo.demo.cluster.CustomCluster。
 图片
图片
最后,我们在消费端发起请求时,可以设置集群容错策略。
// 0.创建服务引用对象实例
ReferenceConfig<GreetingService> referenceConfig = new ReferenceConfig<GreetingService>();
// 1.设置应用程序信息
referenceConfig.setApplication(new ApplicationConfig("first-dubbo-consumer"));
// 2.设置服务注册中心
referenceConfig.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));
// 3.设置服务接口和超时时间
referenceConfig.setInterface(GreetingService.class);
// 4.设置集群容错策略
referenceConfig.setCluster("customCluster");
// 5.设置服务分组与版本
referenceConfig.setVersion("1.0.0");
referenceConfig.setGroup("dubbo");
// 6.引用服务
greetingService = referenceConfig.get();代码 4 就是我们设置的集群容错策略——customCluster。你可能会问,Dubbo 如何根据集群容错策略的名称——customCluster 找到具体的容错策略实现类呢?其实就是通过 Dubbo 的增强 SPI 机制来实现的,这个机制和 JDK SPI 机制差不多。
总结
 图片
图片
今天我们首先学习了 SPI 的定义,然后基于 JDK 中数据库驱动的例子,重点讲解了如何基于 SPI 来实现数据库驱动的扩展性。JDK 对数据库驱动进行了抽象,提供了抽象的 Driver 和 Connection 接口,这些接口就是 SPI 接口。
具体的驱动包实现者可以实现这些 SPI 接口来实现具体数据库驱动。JDK 通过使用 ServiceLoader 机制来扫描驱动包的实现类,并注册这些驱动到 DriverManager,所以我们可以通过 DriverManager.getConnection 方法获取数据库连接。
接下来,我们了解了 JDK SPI 的不足,概要介绍了 Dubbo 中增强的 SPI 的特点以及 Dubbo 如何基于 SPI 实现可扩展性。最后,我们基于 Dubbo 的集群容错策略扩展接口,讲解了 Dubbo 中如何来实现扩展。