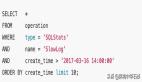
最近,我的一个朋友在面试中遇到了这样一个问题。在MySQL中,假设一个表中有数千万条记录,为什么带有“LIMIT 0, 10”的查询非常快,而带有“LIMIT 1000000, 10”的查询却非常慢?
让我们一起来分析一下。
首先,假设我们已经创建了一个名为Student的表,并向其中插入了500万条学生记录。以下是创建表和插入部分数据的示例SQL语句:
-- 创建一个名为'Student'的表来存储学生信息。
CREATETABLE Student (
idINT AUTO_INCREMENT PRIMARY KEY,
nameVARCHAR(100),
age INT,
gender ENUM('Male', 'Female'),
create_time TIMESTAMPDEFAULTCURRENT_TIMESTAMP
);
-- 插入500万条学生记录的存储过程:
DELIMITER //
CREATEPROCEDURE insert_students()
BEGIN
DECLARE i INTDEFAULT1;
WHILE i <= 5000000 DO
INSERTINTO Student (name, age, gender)
VALUES (CONCAT('Student', i), FLOOR(RAND() * 100), ELT(FLOOR(RAND() * 2 + 1), 'Male', 'Female'));
SET i = i + 1;
ENDWHILE;
END //
DELIMITER ;
-- 调用存储过程插入数据。
CALL insert_students();请注意,插入500万条记录可能需要相对较长的时间,具体时间取决于你的数据库性能。
接下来,我们将分别使用“LIMIT 0, 10”和“LIMIT 1000000, 10”来查询数据。
-- 查询前10个学生。
SELECT * FROM Student LIMIT 0, 10;执行结果如下:
mysql> SELECT * FROM Student LIMIT0, 10;
+---+-----------+-----+--------+---------------------+
| id | name | age | gender | create_time |
+---+-----------+-----+--------+---------------------+
| 1 | Student1 | 71 | Male | 2025-01-01 14:41:15 |
| 2 | Student2 | 9 | Male | 2025-01-01 14:41:15 |
| 3 | Student3 | 33 | Female | 2025-01-01 14:41:15 |
| 4 | Student4 | 56 | Female | 2025-01-01 14:41:15 |
| 5 | Student5 | 73 | Female | 2025-01-01 14:41:15 |
| 6 | Student6 | 84 | Male | 2025-01-01 14:41:15 |
| 7 | Student7 | 50 | Male | 2025-01-01 14:41:15 |
| 8 | Student8 | 4 | Male | 2025-01-01 14:41:15 |
| 9 | Student9 | 18 | Male | 2025-01-01 14:41:15 |
| 10 | Student10 | 8 | Male | 2025-01-01 14:41:15 |
+---+-----------+-----+--------+---------------------+
10 rows in set (0.01 sec)接下来,我们查询从第1000000条记录开始的10条记录:
mysql> SELECT * FROM Student LIMIT 1000000, 10;
Empty set (1.75 sec)可以看到,两者的耗时差异非常大,查询从毫秒级变成了秒级!!!
因此,可以看出,LIMIT中的X值越大,查询速度越慢。
这个问题实际上是MySQL中典型的分页深度问题。那么问题来了:为什么随着LIMIT偏移量的增加,查询会变慢?以及如何优化查询速度?
为什么随着LIMIT中X值的增大,查询速度会变慢?
实际上,这主要是因为数据库需要扫描并跳过X条记录,然后才能返回Y条结果。随着X的增加,需要扫描和跳过的记录数量也会增加,从而导致性能下降。
LIMIT 1000000, 10需要扫描1000010行数据,然后丢弃前1000000行,因此查询速度会非常慢。
优化方法
在MySQL中,分页深度问题有两种典型的优化方法:
- 起始ID定位法:使用上一次查询的最后一个ID作为本次查询的起始ID。
- 覆盖索引 + 子查询。
方法1. 起始ID定位法
起始ID定位法意味着在使用LIMIT查询时指定一个起始ID,而这个起始ID是上一次查询的最后一个ID。例如,如果上一次查询的最后一条记录的ID是990000,那么我们从990001开始扫描表,直接跳过前990000条记录,因此查询效率会提高。具体实现SQL如下:
select name, age, gender from student where id > 990000 order by id limit 10;可以看到,查询只用了0.01秒。
mysql> select name, age, gender from student whereid > 990000orderbyidlimit10;
+--------------+-----+--------+
| name | age | gender |
+--------------+-----+--------+
| Student990001 | 12 | Male |
| Student990002 | 84 | Female |
| Student990003 | 98 | Male |
| Student990004 | 14 | Male |
| Student990005 | 93 | Male |
| Student990006 | 36 | Male |
| Student990007 | 47 | Male |
| Student990008 | 82 | Female |
| Student990009 | 40 | Male |
| Student990010 | 31 | Male |
+--------------+-----+--------+
10 rows in set (0.01 sec)为什么带有起始ID的查询效率高?
带有起始ID的查询效率高的原因在于它充分利用了数据库中主键索引的B+树结构。上一次查询结束时确定的最后一个ID就像一个准确的定位标记,使得当前查询可以直接从这个标记位置开始。
B+树的叶子节点通过双向链表连接。当有一个确定的起始ID时,数据库不需要像普通的LIMIT查询那样盲目扫描和跳过大量记录,而是可以沿着这个双向链表有针对性地向后遍历,快速找到符合条件的后续记录。
这种方法避免了处理大量无关数据,大大减少了数据库的操作开销,从而显著提高了查询的速度和效率。
如下图所示:
 图片
图片
如果上一次查询的结果是9,那么后续再次查询时,只需要从9开始向后遍历N条数据即可得到结果,因此效率非常高。
这种方式避免了从头开始扫描大量数据,而是直接从已知的定位点(即上一次查询的最后一个ID)开始,沿着B+树的双向链表向后遍历,快速找到符合条件的记录。由于不需要扫描和跳过大量无关数据,查询的开销大大减少,从而显著提高了查询效率。
优缺点分析
这种查询方法更适合逐页查询数据,比如在移动应用中浏览新闻时的瀑布流模式。
然而,如果用户在页面之间跳转,例如在查询第1页后直接查询第100页,那么这种实现方法就不太合适了。
方法2. 覆盖索引 + 子查询
如果你仔细观察,可能会注意到我们之前的查询语句没有任何条件,这实际上并不太符合实际应用场景。
假设我们现在有一个需求,要求能够按创建时间的倒序查询学生信息并进行分页。优化前的SQL如下:
select name, age, gender, create_time from student order by create_time desc limit 1000000,10;执行一下,看看在有500万条数据的情况下,查询第100万条记录之后的10条数据需要多长时间。
mysql> select name, age, gender, create_time from student orderby create_time desclimit1000000,10;
+----------------+-----+--------+---------------------+
| name | age | gender | create_time |
+----------------+-----+--------+---------------------+
| Student#000012 | 15 | Female | 2025-01-01 20:10:19 |
| Student#000013 | 88 | Female | 2025-01-01 20:10:19 |
| Student#000014 | 31 | Male | 2025-01-01 20:10:19 |
| Student#000015 | 96 | Male | 2025-01-01 20:10:19 |
| Student#000016 | 61 | Male | 2025-01-01 20:10:19 |
| Student#000017 | 90 | Male | 2025-01-01 20:10:19 |
| Student#000018 | 45 | Female | 2025-01-01 20:10:19 |
| Student#000019 | 14 | Male | 2025-01-01 20:10:19 |
| Student#000020 | 70 | Female | 2025-01-01 20:10:19 |
| Student#000021 | 2 | Female | 2025-01-01 20:10:19 |
+----------------+-----+--------+---------------------+
10 rows in set (3.36 sec)可以看到,实际上用了3秒!!!显然,用户会明显感觉到卡顿,用户体验非常差。
让我们再看看如果改成limit 0, 10会花多少时间。
mysql> select name, age, gender, create_time from student orderby create_time desclimit0,10;
+----------------+-----+--------+---------------------+
| name | age | gender | create_time |
+----------------+-----+--------+---------------------+
| Student5000000 | 29 | Male | 2025-01-01 21:39:19 |
| Student4999999 | 1 | Female | 2025-01-01 21:39:19 |
| Student4999998 | 0 | Female | 2025-01-01 21:39:19 |
| Student4999997 | 44 | Male | 2025-01-01 21:39:19 |
| Student4999996 | 83 | Male | 2025-01-01 21:39:19 |
| Student4999995 | 93 | Female | 2025-01-01 21:39:19 |
| Student4999994 | 32 | Female | 2025-01-01 21:39:19 |
| Student4999993 | 90 | Male | 2025-01-01 21:39:19 |
| Student4999992 | 21 | Female | 2025-01-01 21:39:19 |
| Student4999991 | 68 | Female | 2025-01-01 21:39:19 |
+----------------+-----+--------+---------------------+
10 rows in set (0.00 sec)几乎感觉不到时间。
那么为什么深度分页会变慢呢?
我相信你肯定会说,因为它会扫描1000010行符合条件的数据,然后丢弃前1000000行再返回。
然而,这并不是唯一的原因。
在上面的SQL中,虽然已经为create_time字段创建了索引,但查询效率仍然很慢。这是因为它需要获取1000000条完整的数据,包括没有索引的字段,如name、age和gender。因此,它需要频繁地回表查找,导致执行效率非常低。
此时,我们可以进行如下优化:
select t1.name, t1.age, t1.gender, t1.create_time from student as t1
inner join
(select id from student order by create_time desc limit 1000000,10) as t2 on t1.id = t2.id;让我们再看看执行时间。
mysql> select t1.name, t1.age, t1.gender, t1.create_time from student as t1
innerjoin
(selectidfrom student orderby create_time desclimit1000000,10) as t2 on t1.id = t2.id;
+----------------+-----+--------+---------------------+
| name | age | gender | create_time |
+----------------+-----+--------+---------------------+
| Student#000012 | 15 | Female | 2025-01-01 20:10:19 |
| Student#000013 | 88 | Female | 2025-01-01 20:10:19 |
| Student#000014 | 31 | Male | 2025-01-01 20:10:19 |
| Student#000015 | 96 | Male | 2025-01-01 20:10:19 |
| Student#000016 | 61 | Male | 2025-01-01 20:10:19 |
| Student#000017 | 90 | Male | 2025-01-01 20:10:19 |
| Student#000018 | 45 | Female | 2025-01-01 20:10:19 |
| Student#000019 | 14 | Male | 2025-01-01 20:10:19 |
| Student#000020 | 70 | Female | 2025-01-01 20:10:19 |
| Student#000021 | 2 | Female | 2025-01-01 20:10:19 |
+----------------+-----+--------+---------------------+
10 rows in set (0.23 sec)只用了0.23秒。
与原始SQL相比,优化后的SQL有效避免了频繁的回表操作。关键在于子查询只获取了主键ID。通过利用索引覆盖技术,它首先准确定位了少量符合条件的主键ID,然后基于这些主键ID进行后续查询,从而显著提高了查询效率,降低了查询成本。
索引覆盖是一种数据库查询优化技术。它意味着在执行查询时,数据库引擎可以直接从索引中获取所有需要的数据,而不必回表(访问主键索引或表中的实际数据行)来获取额外的信息。这样可以减少磁盘I/O操作,从而提高查询性能。