在之前的 Java 中的 Lambda文章中,我简要提到了 Stream 的使用。在这篇文章中将深入探讨它。首先,我们以一个熟悉的Student类为例。假设有一组学生:
public class Student {
private String name;
private Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
// toString 方法
@Override
public String toString() {
return"Student{" + "name='" + name + '\'' + ", age=" + age + '}';
}
}List<Student> students = new ArrayList<>();
students.add(new Student("Bob", 18));
students.add(new Student("Ted", 17));
students.add(new Student("Zeka", 19));现在有这样一个需求:从给定的学生列表中返回年龄大于等于 18 岁的学生,按年龄降序排列,最多返回 2 个。
在Java7 及更早的代码中,我们会这样实现:
public static List<Student> getTwoOldestStudents(List<Student> students) {
List<Student> result = new ArrayList<>();
// 1. 遍历学生列表,筛选出符合年龄条件的学生
for (Student student : students) {
if (student.getAge() >= 18) {
result.add(student);
}
}
// 2. 对符合条件的学生按年龄排序
result.sort((s1, s2) -> s2.getAge() - s1.getAge());
// 3. 如果结果大于 2 个,截取前两个数据并返回
if (result.size() > 2) {
result = result.subList(0, 2);
}
return result;
}在Java8 及以后的版本中,借助 Stream,我们可以更优雅地写出以下代码:
public static List<Student> getTwoOldestStudentsByStream(List<Student> students) {
return students.stream()
.filter(s -> s.getAge() >= 18)
.sorted((s1, s2) -> s2.getAge() - s1.getAge())
.limit(2)
.collect(Collectors.toList());
}两种方法的区别:
- 从功能角度来看,过程式代码实现将集合元素、循环迭代和各种逻辑判断耦合在一起,暴露了太多细节。随着需求的变化和复杂化,过程式代码将变得难以理解和维护。
- 函数式解决方案将代码细节和业务逻辑解耦。类似于 SQL 语句,它表达的是“做什么”而不是“怎么做”,让程序员更专注于业务逻辑,写出更简洁、易理解和维护的代码。
基于我日常项目的实践经验,我对 Stream 的核心点、易混淆的用法、典型使用场景等做了详细总结。希望能帮助大家更全面地理解 Stream,并在项目开发中更高效地应用它。
一、初识 Stream
Java 8 新增了 Stream 特性,它使用户能够以函数式且更简单的方式操作 List、Collection 等数据结构,并在用户无感知的情况下实现并行计算。
简而言之,Stream 操作被组合成一个 Stream 管道。Stream 管道由以下三部分组成:
- 创建 Stream(从源数据创建,源数据可以是数组、集合、生成器函数、I/O 通道等);
- 中间操作(可能有零个或多个,它们将一个 Stream 转换为另一个 Stream,例如filter(Predicate));
- 终止操作(产生结果从而终止 Stream,例如count()或forEach(Consumer))。
下图展示了这些过程:

每个阶段里的 Stream 操作都包含多个方法。我们先来简单了解下每个方法的功能。
1. 创建 Stream
主要负责直接创建一个新的 Stream,或基于现有的数组、List、Set、Map 等集合类型对象创建新的 Stream。
API | 解释 |
stream() | 创建一个新的串行流对象 |
parallelStream() | 创建一个可以并行执行的流对象 |
Stream.of() | 从给定的元素序列创建一个新的串行流对象 |
除了Stream,还有IntStream、LongStream和DoubleStream等基本类型的流,它们都称为“流”。
2. 中间操作
这一步负责处理 Stream 并返回一个新的 Stream 对象。中间操作可以叠加。
API | 解释 |
filter() | 过滤符合条件的元素并返回一个新的流 |
sorted() | 按指定规则对所有元素排序并返回一个新的流 |
skip() | 跳过集合前面的指定数量的元素并返回一个新的流 |
distinct() | 去重并返回一个新的流 |
limit() | 只保留集合前面的指定数量的元素并返回一个新的流 |
concat() | 将两个流的数据合并为一个新的流并返回 |
peek() | 遍历并处理流中的每个元素并返回处理后的流 |
map() | 将现有元素转换为另一种对象类型(一对一)并返回一个新的流 |
flatMap() | 将现有元素转换为另一种对象类型(一对多),即一个原始元素对象可能转换为一个或多个新类型的元素,然后返回一个新的流 |
3. 终止操作
顾名思义,终止操作后 Stream 将结束,最后可能会执行一些逻辑处理,或根据需求返回一些执行结果。
API | 解释 |
findFirst() | 找到第一个符合条件的元素时终止流处理 |
findAny() | 找到任意一个符合条件的元素时终止流处理 |
anyMatch() | 返回布尔值,类似于isContains(),用于判断是否有符合条件的元素 |
allMatch() | 返回布尔值,用于判断是否所有元素都符合条件 |
noneMatch() | 返回布尔值,用于判断是否所有元素都不符合条件 |
min() | 返回流处理后的最小值 |
max() | 返回流处理后的最大值 |
count() | 返回流处理后的元素数量 |
collect() | 将流转换为指定类型,通过Collectors指定 |
toArray() | 将流转换为数组 |
iterator() | 将流转换为迭代器对象 |
forEach() | 无返回值,遍历元素并执行给定的处理逻辑 |
二、代码实战
1. 创建 Stream
// Stream.of, IntStream.of...
Stream<String> nameStream = Stream.of("Bob", "Ted", "Zeka");
IntStream ageStream = IntStream.of(18, 17, 19);
// stream, parallelStream
Stream<Student> studentStream = students.stream();
Stream<Student> studentParallelStream = students.parallelStream();在大多数情况下,我们基于现有的集合创建 Stream。
2. 中间操作
(1) map
map和flatMap都用于将现有元素转换为其他类型。区别在于:
- map必须是一对一的,即每个元素只能转换为一个新元素;
- flatMap可以是一对多的,即每个元素可以转换为一个或多个新元素。
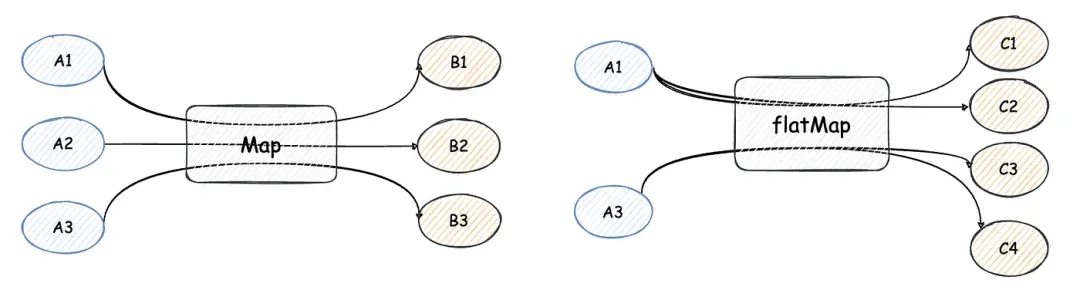
我们先来看map方法。当前需求如下:将之前的学生对象列表转换为学生姓名列表并输出:
public static List<String> objectToString(List<Student> students) {
return students.stream()
.map(Student::getName)
.collect(Collectors.toList());
}输出:
[Bob, Ted, Zeka]可以看到,输入中有三个学生,输出也是三个学生姓名。
(2) flatMap
学校要求每个学生加入一个团队。假设 Bob、Ted 和 Zeka 加入了篮球队,Alan、Anne 和 Davis 加入了足球队。
public class Team {
private String type;
private List<Student> students;
public Team(String type, List<Student> students) {
this.type = type;
this.students = students;
}
public String getType() {
return type;
}
public List<Student> getStudents() {
return students;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("Team{");
sb.append("type='").append(type).append('\'');
sb.append(", students=[");
for (int i = 0; i < students.size(); i++) {
Student student = students.get(i);
sb.append("{name='").append(student.getName()).append("', age=").append(student.getAge()).append('}');
if (i < students.size() - 1) {
sb.append(", ");
}
}
sb.append("]}");
return sb.toString();
}
}List<Student> basketballStudents = new ArrayList<>();
basketballStudents.add(new Student("Bob", 18));
basketballStudents.add(new Student("Ted", 17));
basketballStudents.add(new Student("Zeka", 19));
List<Student> footballStudents = new ArrayList<>();
footballStudents.add(new Student("Alan", 19));
footballStudents.add(new Student("Anne", 21));
footballStudents.add(new Student("Davis", 21));
Team basketballTeam = new Team("basketball", basketballStudents);
Team footballTeam = new Team("football", footballStudents);
List<Team> teams = new ArrayList<>();
teams.add(basketballTeam);
teams.add(footballTeam);现在我们需要统计所有团队中的学生,并将他们合并到一个列表中。你会如何实现这个需求?
在 Java7 及更早的版本中可以通过以下方式解决:
List<Student> allStudents = new ArrayList<>();
for (Team team : teams) {
for (Student student : team.getStudents()) {
allStudents.add(student);
}
}但这段代码有两个嵌套的 for 循环,不够优雅。面对这个需求,flatMap可以派上用场。
List<Student> allStudents = teams.stream()
.flatMap(t -> t.getStudents().stream())
.collect(Collectors.toList());一行代码就搞定了。flatMap方法接受一个 lambda 表达式函数,函数的返回值必须是一个 Stream 类型。flatMap方法最终会将所有返回的 Stream 合并生成一个新的 Stream,而map方法无法做到。
下图清晰地展示了flatMap的处理逻辑:
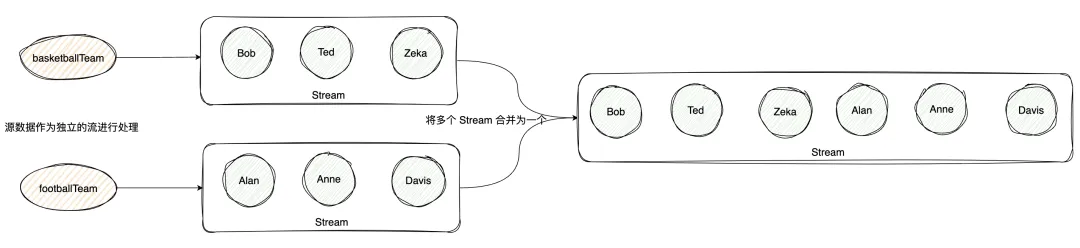
(3) filter, distinct, sorted, limit
关于刚才所有团队中的学生列表,我们现在需要知道这些学生中第二和第三大的年龄。他们必须至少 18 岁。此外,如果有重复的年龄,只能算一个。
List<Integer> topTwoAges = allStudents.stream()
.map(Student::getAge) // [18, 17, 19, 19, 21, 21]
.filter(a -> a >= 18) // [18, 19, 19, 21, 21]
.distinct() // [18, 19, 21]
.sorted((a1, a2) -> a2 - a1) // [21, 19, 18]
.skip(1) // [19, 18]
.limit(2) // [19, 18]
.collect(Collectors.toList());
System.out.println(topTwoAges);输出:
[19, 18]注意:由于在skip方法操作后只剩下两个元素,limit步骤实际上可以省略。
(4) peek, foreach
peek方法和foreach方法都可以用于遍历元素并逐个处理,因此我们将它们放在一起进行比较和讲解。但值得注意的是,peek是一个中间操作方法,而foreach是一个终止操作方法。
中间操作只能作为 Stream 管道中间的处理步骤,不能直接执行以获取结果,必须与终止操作配合执行。而foreach作为一个没有返回值的终止方法,可以直接执行相应的操作。
比如,我们分别使用peek和foreach对篮球队的每个学生说“Hello, xxx…”。
// peek
System.out.println("---start peek---");
basketballTeam.getStudents().stream().peek(s -> System.out.println("Hello, " + s.getName()));
System.out.println("---end peek---");
// foreach
System.out.println("---start foreach---");
basketballTeam.getStudents().stream().forEach(s -> System.out.println("Hello, " + s.getName()));
System.out.println("---end foreach---");从输出中可以看出,peek在单独调用时不会执行,而foreach可以直接执行:
---start peek---
---end peek---
---start foreach---
Hello, Bob
Hello, Ted
Hello, Zeka
---end foreach---如果在peek后面加上终止操作,它就可以执行。
System.out.println("---start peek---");
basketballTeam.getStudents().stream().peek(s -> System.out.println("Hello, " + s.getName())).count();
System.out.println("---end peek---");
// 输出
---start peek---
Hello, Bob
Hello, Ted
Hello, Zeka
---end peek---peek应谨慎用于业务处理逻辑。因为peek方法是否执行在各个版本并不一致。
例如,在 Java8 版本中,刚才的peek方法会正常执行,但在 Java17 中,它会被自动优化,peek中的逻辑不会执行。至于原因,你可以查看 JDK17 的官方 API 文档。

三、终止操作
根据终止操作返回的结果类型大概分为两类。
一类返回的是简单类型,主要包括max、min、count、findAny、findFirst、anyMatch、allMatch等方法。
另一类是返回的是集合类型。大多数场景是获取集合类的结果对象,如 List、Set 或 HashMap 等,主要通过collect方法实现。
1. 简单结果类型
(1) max, min
max()和min()主要用于返回流处理后元素的最大值/最小值。返回结果由Optional包装。关于Optional的使用,请参考之前的Java 中如何优雅地处理 null 值文章 。
我们直接看例子:
找到足球队中年龄最大和最小的是谁?
// max
footballTeam.getStudents().stream()
.map(Student::getAge)
.max(Comparator.comparing(a -> a))
.ifPresent(a -> System.out.println("足球队中最大的年龄是:" + a));
// min
footballTeam.getStudents().stream()
.map(Student::getAge)
.min(Comparator.comparing(a -> a))
.ifPresent(a -> System.out.println("足球队中最小的年龄是:" + a));输出:
足球队中最大的年龄是:21
足球队中最小的年龄是:19(2) findAny, findFirst
findAny()和findFirst()主要用于在找到符合条件的元素。对于串行 Stream,findAny()和findFirst()功能相同;对于并行 Stream,findAny()更高效。
假设篮球队新增了一个学生 Tom,年龄为 19 岁。
List<Student> basketballStudents = new ArrayList<>();
basketballStudents.add(new Student("Bob", 18));
basketballStudents.add(new Student("Ted", 17));
basketballStudents.add(new Student("Zeka", 19));
basketballStudents.add(new Student("Tom", 19));现在需要查找到:
- 篮球队中第一个年龄为 19 岁的学生姓名;
- 篮球队中任意一个年龄为 19 岁的学生姓名。
// findFirst
basketballStudents.stream()
.filter(s -> s.getAge() == 19)
.findFirst()
.map(Student::getName)
.ifPresent(name -> System.out.println("findFirst: " + name));
// findAny
basketballStudents.stream()
.filter(s -> s.getAge() == 19)
.findAny()
.map(Student::getName)
.ifPresent(name -> System.out.println("findAny: " + name));输出:
findFirst: Zeka
findAny: Zeka可以看到,在串行 Stream 下,这两个功能没有区别。并行处理的区别将在后面介绍。
(3) count
篮球队新增了一个学生,现在篮球队有多少学生?
System.out.println("篮球队的学生人数:" + basketballStudents.stream().count());输出:
篮球队的学生人数:4(4) anyMatch, allMatch, noneMatch
顾名思义,这三个方法用于判断元素是否符合条件,并返回布尔值。看以下三个例子:
- 足球队中是否有名为 Alan 的学生?
- 足球队中的所有学生是否都小于 22 岁?
- 足球队中是否没有年龄超过 20 岁的学生?
// anyMatch
System.out.println("anyMatch: " + footballStudents.stream().anyMatch(s -> s.getName().equals("Alan")));
// allMatch
System.out.println("allMatch: " + footballStudents.stream().allMatch(s -> s.getAge() < 22));
// noneMatch
System.out.println("noneMatch: " + footballStudents.stream().noneMatch(s -> s.getAge() > 20));输出:
anyMatch: true
allMatch: true
noneMatch: false2. 结果集合类型
(1) 生成集合
生成集合应该是collect最常用的场景。除了之前提到的 List,还可以生成 Set、Map 等,如下:
// 获取篮球队中学生年龄的分布,不允许重复
Set<Integer> ageSet = basketballStudents.stream()
.map(Student::getAge)
.collect(Collectors.toSet());
System.out.println("set: " + ageSet);
// 获取篮球队中所有学生的姓名和年龄的 Map
Map<String, Integer> nameAndAgeMap = basketballStudents.stream()
.collect(Collectors.toMap(Student::getName, Student::getAge));
System.out.println("map: " + nameAndAgeMap);输出:
set: [17, 18, 19]
map: {Ted=17, Tom=19, Bob=18, Zeka=19}(2) 生成字符串
除了生成集合,collect还可以用于拼接字符串。
例如,我们获取篮球队中所有学生的姓名后,希望用“,”将所有姓名拼接成一个字符串并返回。
System.out.println(basketballStudents.stream()
.map(Student::getName)
.collect(Collectors.joining(",")));输出:
Bob,Ted,Zeka,Tom也许你会说,用String.join()不也能实现这个功能吗?确实,如果只是单纯的字符串拼接,确实没有必要使用Stream来实现。毕竟,杀鸡焉用牛刀!
此外,Collectors.joining()还支持定义前缀和后缀,功能更强大。
System.out.println(basketballStudents.stream()
.map(Student::getName)
.collect(Collectors.joining(",", "(", ")")));输出:
(Bob,Ted,Zeka)(3) 生成统计结果
还有一个在实际中可能很少用到的场景,就是使用collect生成数字数据的统计结果。我们简单看一下。
// 计算平均年龄
System.out.println("平均年龄:" + basketballStudents.stream()
.map(Student::getAge)
.collect(Collectors.averagingInt(a -> a)));
// 统计汇总
IntSummaryStatistics summary = basketballStudents.stream()
.map(Student::getAge)
.collect(Collectors.summarizingInt(a -> a));
System.out.println("summary: " + summary);在上面的例子中,使用collect对年龄进行了一些数学运算,结果如下:
平均年龄:18.0
summary: IntSummaryStatistics{count=3, sum=54, min=17, average=18.000000, max=19}四、并行 Stream
使用并行流可以有效利用计算机性能,提高执行速度。并行 Stream 将整个流分成多个片段,然后并行处理每个片段的流,最后将每个片段的执行结果汇总成一个完整的 Stream。
如下图所示,筛选出大于等于 18 的数字:

将原始任务拆分为多个任务。
[7, 18, 18]每个任务并行执行操作。
stream.filter(a -> a >= 18)单个任务处理并汇总为单个结果。
[18, 18]高效使用 findAny()
如上所述,findAny()在并行 Stream 中更高效,从 API 文档中可以看出,每次执行该方法的结果可能不同。
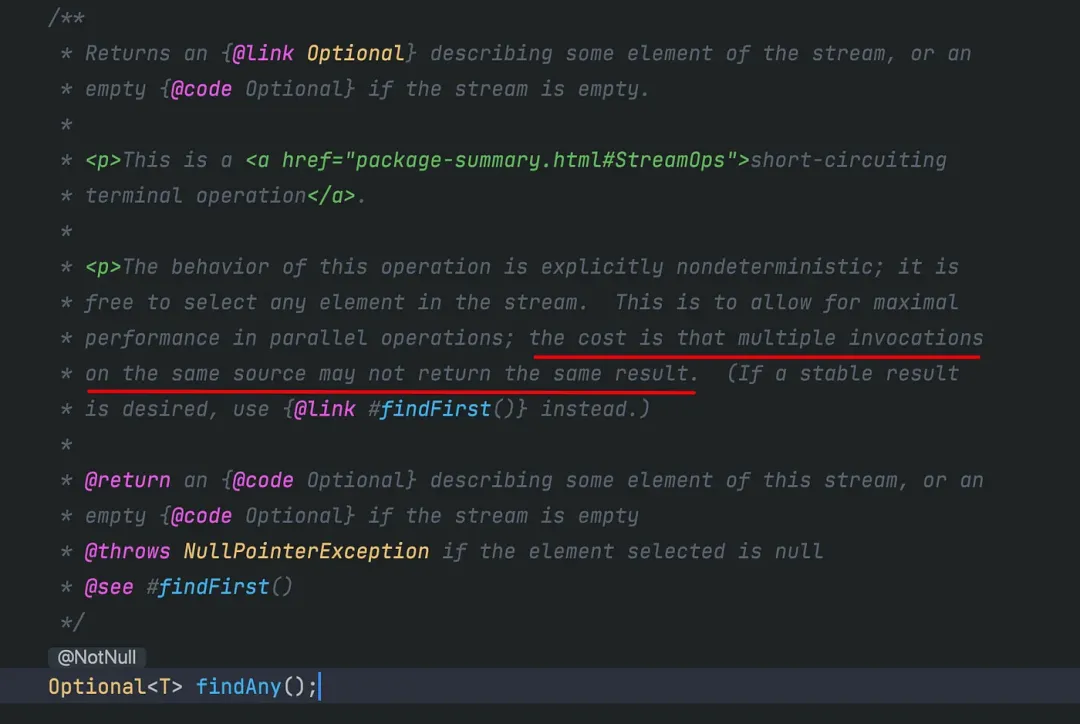
使用parallelStream执行findAny()10 次,以找出任何满足条件(名字是 Bob、Tom 或 Zeka)的学生名字。
for (int i = 0; i < 10; i++) {
basketballStudents.parallelStream()
.filter(s -> s.getAge() >= 18)
.findAny()
.map(Student::getName)
.ifPresent(name -> System.out.println("并行流中的 findAny: " + name));
}输出:
并行流中的findAny: Zeka
并行流中的findAny: Zeka
并行流中的findAny: Tom
并行流中的findAny: Zeka
并行流中的findAny: Zeka
并行流中的findAny: Bob
并行流中的findAny: Zeka
并行流中的findAny: Zeka
并行流中的findAny: Zeka这个输出证实了findAny()的不稳定性。
关于并行流的更多知识,我将在后续文章中进一步分析和讨论。
五、注意事项
1. 延迟执行
Stream 是惰性的;只有在启动终止操作时才会对源数据执行计算,并且只在需要时才会消耗源元素。前面提到的peek方法就是一个很好的例子。
2. 避免执行两次终止操作
一旦 Stream 被终止,就不能再用于执行其他操作,否则会报错。看下面的例子:
Stream<Student> stream = students.stream();
stream.filter(s -> s.getAge() >= 18).count();
stream.filter(s -> s.getAge() >= 18).forEach(System.out::println); // 这里会报错输出:
java.lang.IllegalStateException: stream has already been operated upon or closed因为一旦 Stream 被终止,就不能再重复使用。