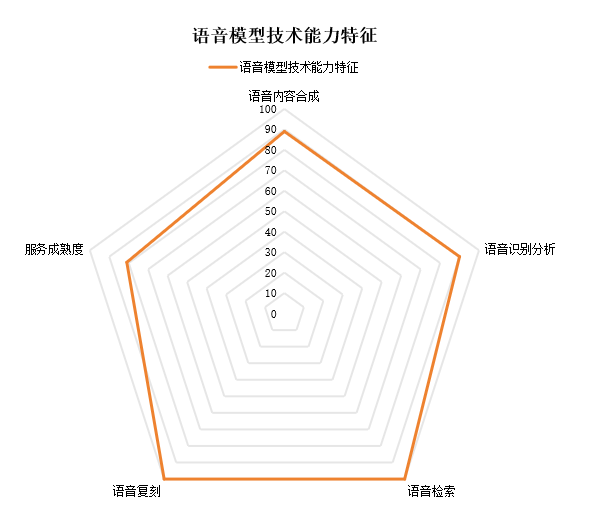
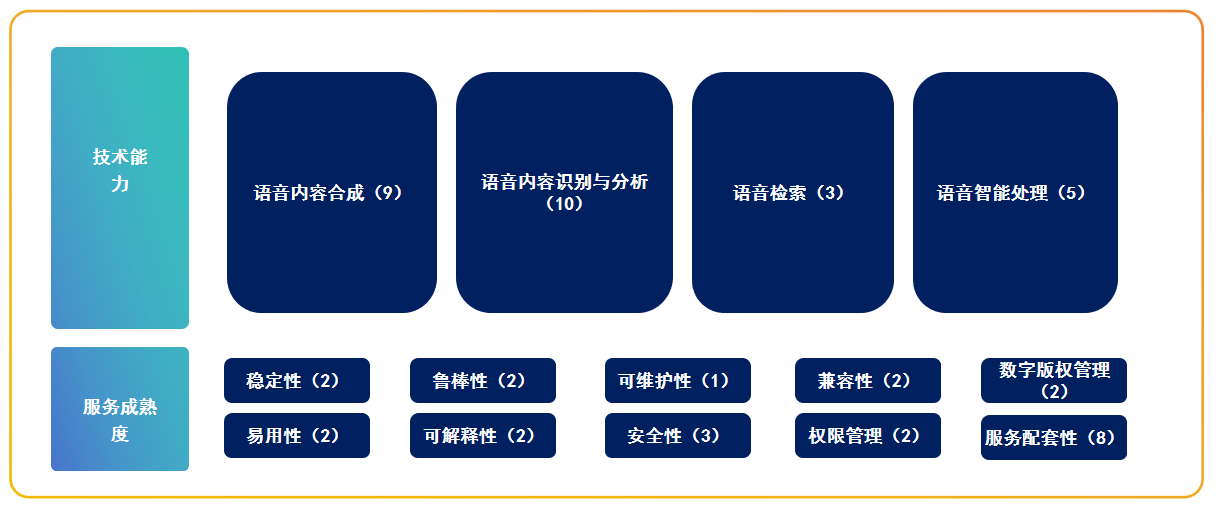
近日,火山引擎提供的豆包大语音模型成为首家“引领级”通过中国信通院语音大模型能力评估的产品,经相关标准和评估测试显示,豆包大语音模型在语音合成、复刻、识别分析等方面能力突出,处于行业领先地位。
近年来,随着人工智能技术的快速发展,语音大模型作为语音理解和生成的关键技术,正不断赋能各行业的智能化转型。在此背景下,中国信通院制定了《语音大模型技术能力要求》标准旨在为行业提供技术参考和规范,提升语音大模型技术能力的可操作性和标准化水平。据介绍,标准共包含两大评估板块的4个方面
能听:
○ 精准的语音识别能力(ASR):具备高准确率,能够精准识别不同场景语音输入,包括噪声环境中的语音、方言和口音。
○ 多语种与跨语言处理:支持多语种语音识别,适配全球化应用场景。
○ 感知语境变化:能区分语气、情感变化,捕捉说话者意图和语义。
会说:
○ 自然语音合成(TTS),实现接近真人语音的合成,支持情感化表达和多种语言发声。
○ 多样化语音风格:支持多种音色、语速和语调的自定义输出,满足个性化需求。
○ 实时生成能力:毫秒级响应时间,支持实时语音交互。
够懂:
○ 深度语义理解:能准确理解语音输入中的复杂语义、上下文关联和用户意图。
○ 多任务协同处理:能同时完成语音识别、情感分析、语言翻译等多任务。
○ 个性化适配:根据用户历史数据调整语音交互方式,实现个性化推荐或对话内容定制。
好用:
○ 广泛的应用场景支持:从个人助手到行业解决方案,覆盖家居、医疗、教育、金融等领域。
○ 轻量化与边缘部署:优化模型适配终端设备,在低算力环境中实现高性能。
○ 高效开发与标准化接口:支持快速集成和跨平台应用,降低开发与部署成本。
据了解在本次评估中,豆包语音大模型全部满足23项功能评估、在4项性能评估得分表现优秀,支持20余项服务能力,成为国内首家引领级通过评估的产品,具备优异的语音合成、复刻、识别、分析等能力。