特征选择是机器学习中的一个重要过程,通过选择与目标变量最相关的特征,剔除冗余或无关的特征,从而提高模型的性能、减少训练时间,并降低过拟合的风险。

常见的特征选择方法有:过滤方法、包装方法和嵌入方法
过滤方法
过滤方法是一种基于统计特性和独立于模型的特征选择技术。
它通过计算特征与目标变量之间的相关性或其他统计指标来评估特征的重要性。
特点
- 独立于模型:不依赖具体的机器学习算法。
- 计算效率高:通常基于统计指标,计算开销较小。
常见方法
1.单变量统计方法
- 相关系数:计算特征与目标变量之间的相关性(如皮尔逊相关系数)。
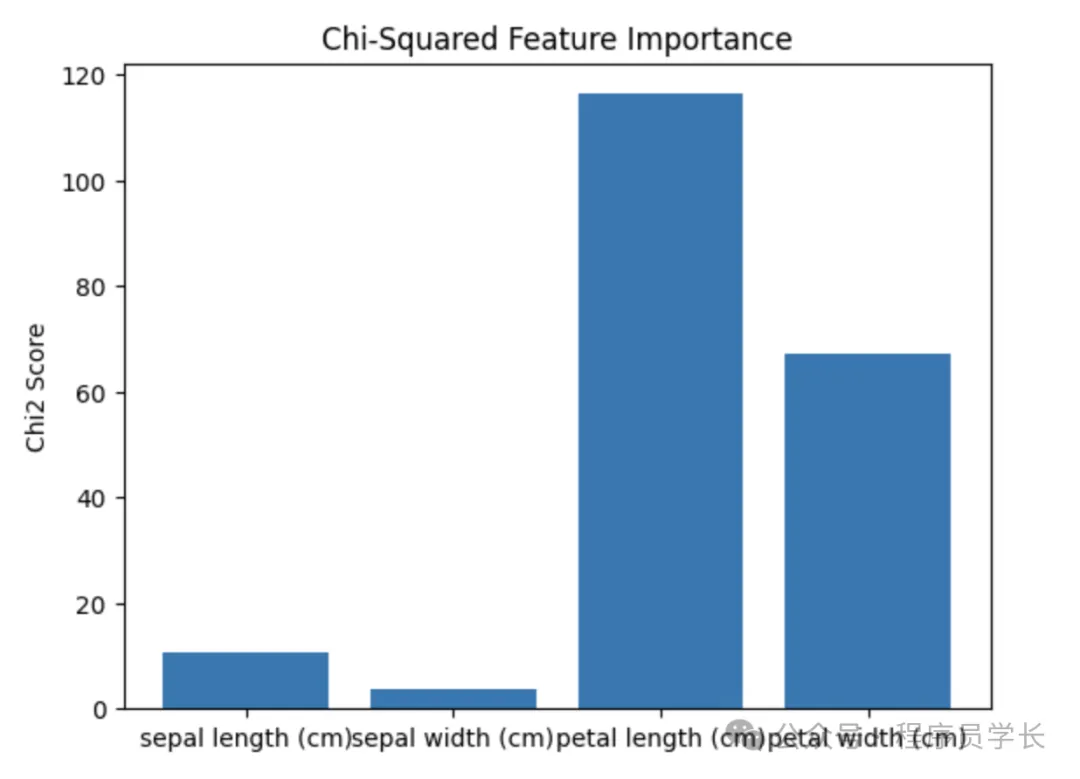
- 卡方检验:用于分类变量和目标变量之间的独立性检验。
- 方差分析(ANOVA):评估连续特征和分类目标变量之间的相关性。
2.基于评分的特征排序
- 信息增益:基于信息论,衡量特征对目标变量的信息贡献。
- 互信息:量化两个变量之间的统计依赖性。
- 方差阈值:通过筛选低方差特征进行降维。
3.基于统计检验的筛选
- t检验:比较两个分布的均值,常用于分类问题。
- F检验:比较多个组别之间的均值差异。
优缺点
优点
- 简单快速,适合大数据集。
- 不依赖特定的模型,通用性强。
缺点
- 忽略特征之间的交互作用。
- 可能选择对目标变量无显著意义的特征。
过滤方法示例
通过 SelectKBest 使用卡方检验来筛选特征。
包装方法
包装方法将特征选择过程嵌入模型训练中,根据模型性能评估特征集的优劣。
它通过搜索最优特征子集来提高模型性能。
特点
- 依赖于模型:通过训练和评估模型来选择特征。
- 能够捕捉特征之间的交互作用:评估子集时考虑了特征间的协同效应。
常见方法
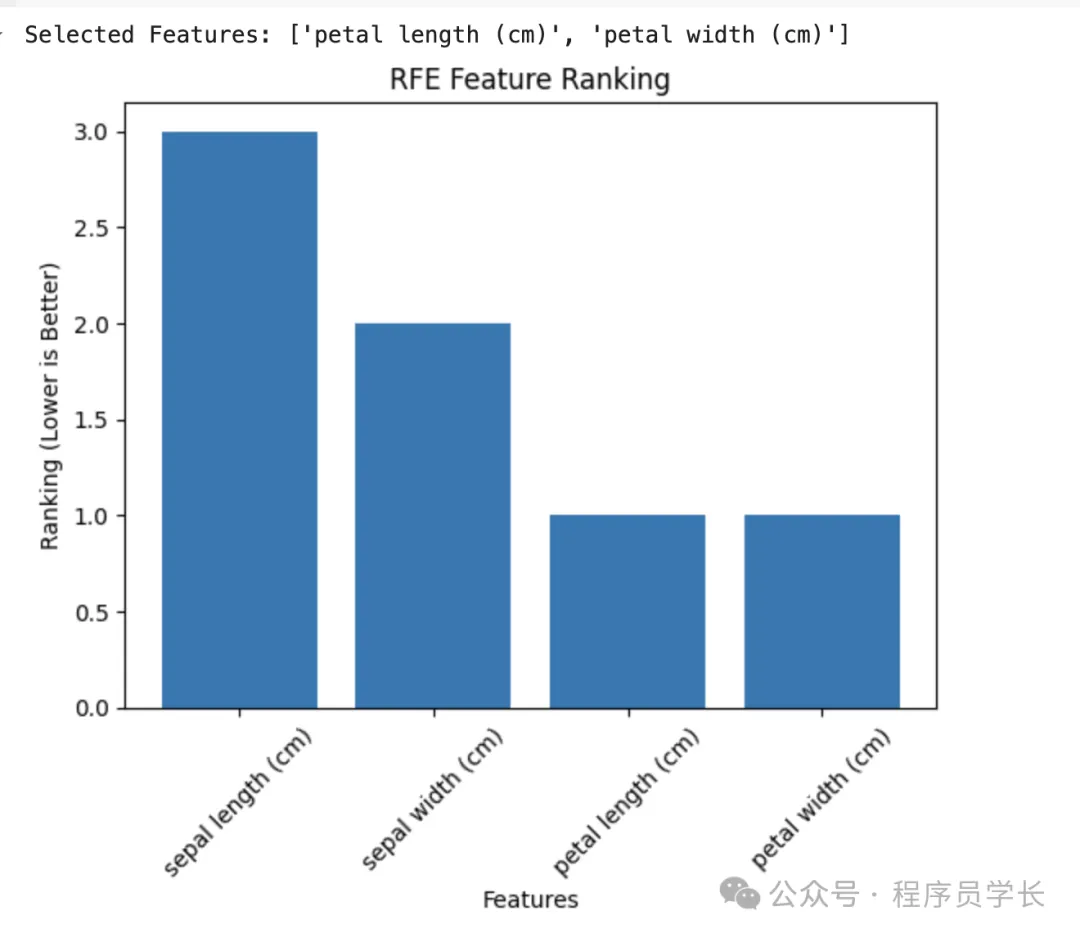
1.递归特征消除(RFE)
基于模型权重递归地移除特征。
例如,训练一个模型(如线性回归或SVM),根据特征重要性删除影响最小的特征。
2.前向选择(Forward Selection)
从空特征集开始,逐步加入使模型性能提高最多的特征。
3.后向消除(Backward Elimination)
从全特征集开始,逐步移除对模型性能影响最小的特征。
4.嵌套交叉验证
在特征选择和模型评估过程中防止过拟合。
优缺点
优点
- 考虑特征之间的交互作用。
- 能找到与特定模型高度匹配的特征子集。
缺点
- 计算开销大,尤其在大数据集上。
- 依赖于所选的学习算法,通用性差。
包装方法示例
通过递归特征消除(RFE)与逻辑回归结合筛选特征。
嵌入方法
嵌入方法将特征选择与模型训练过程结合,在模型训练的同时完成特征选择。
它通过内置的正则化或特征重要性指标评估特征。
特点
- 依赖于模型:模型自带的特征权重或正则化机制决定特征选择。
- 计算效率较高:避免了包装方法中多次训练模型的开销。
常见方法
1.正则化方法
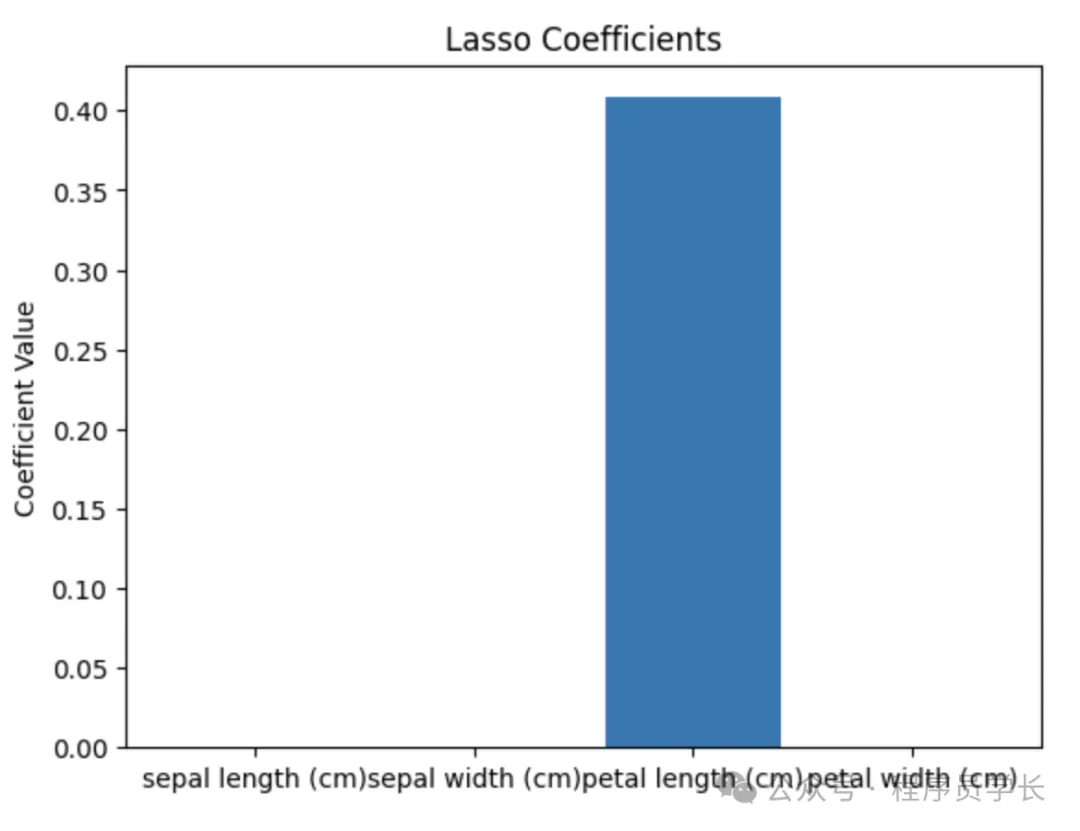
使用 L1正则化(Lasso)将部分特征的权重收缩为零,从而实现特征选择,适用于高维稀疏数据。
2.基于树模型的特征重要性
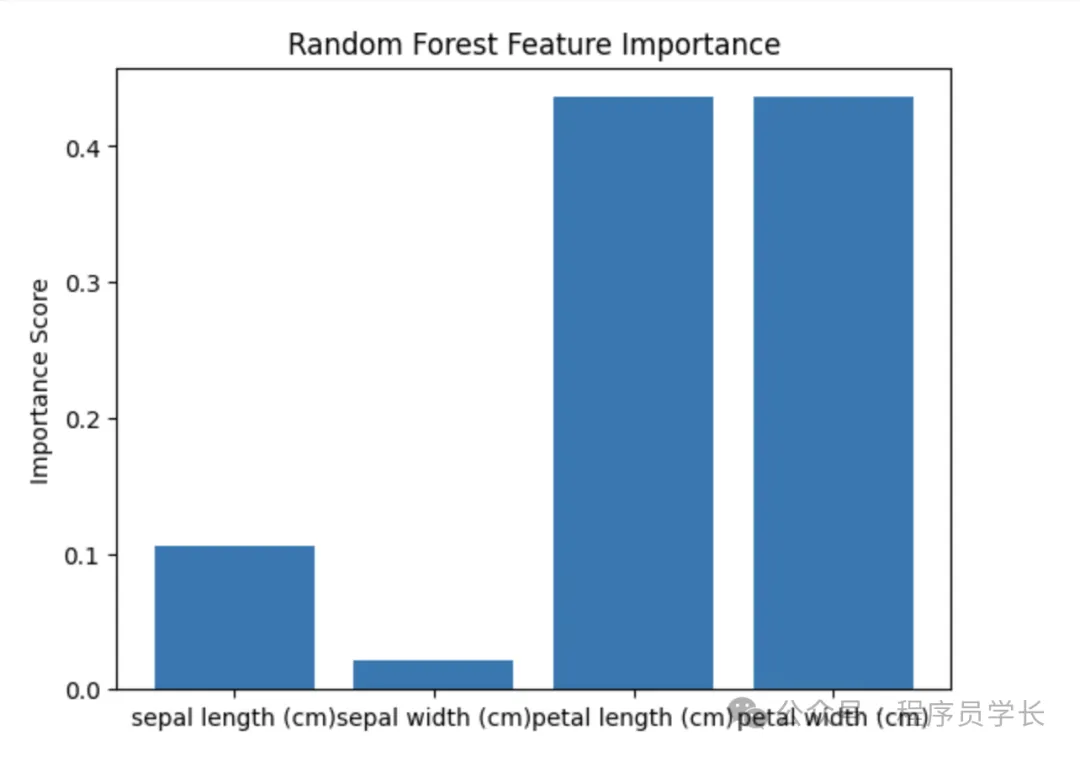
决策树及其衍生算法(如随机森林、XGBoost、LightGBM)可以计算每个特征的重要性得分。
特征重要性可以根据信息增益、基尼指数或分裂增益来衡量。
3.基于系数的重要性评估
对于线性模型,可以直接使用权重系数评估特征的重要性。
4.深度学习中的注意力机制
注意力机制可以用来动态调整特征的重要性。
优缺点
优点
- 计算效率高。
- 综合了特征选择与模型优化的过程。
缺点
- 依赖特定模型,缺乏灵活性。
- 不适用于所有类型的数据或任务。
嵌入方法示例
通过 Lasso 回归筛选特征(L1 正则化)。
通过随机森林评估特征重要性。