redo log也就是所谓的重做日志,是innoDb存储引擎独有的日志,它使得MySQL在宕机情况下依旧可以redo log完成数据具备恢复能力, 从而保证数据完整性,本文将针对该日志进行分析讲解,希望对你有帮助。

1. redo log的作用
redo log是InnoDB存储引擎独有的日志,用于MySQL工作过程中崩溃或者宕机时进行数据恢复的文件,从而保证数据的持久性以及完整性。
2. redo log是如何运行工作的
我们都知道数据库数据基本单位也是和操作系统一致的,都是以页为单位,我们以MySQL数据查询为例,为了尽可能减少IO次数,MySQL在进行数据查询会优先将数据查询并存储到Buffer Pool中,然后按照一定的调度规则将修改操作写回磁盘中。
当我们需要对数据修改操作之后,这个修改操作就会优先被生成一个redo日志存放到redo log buffer中,最终就会被刷盘并写入到redo log file中。
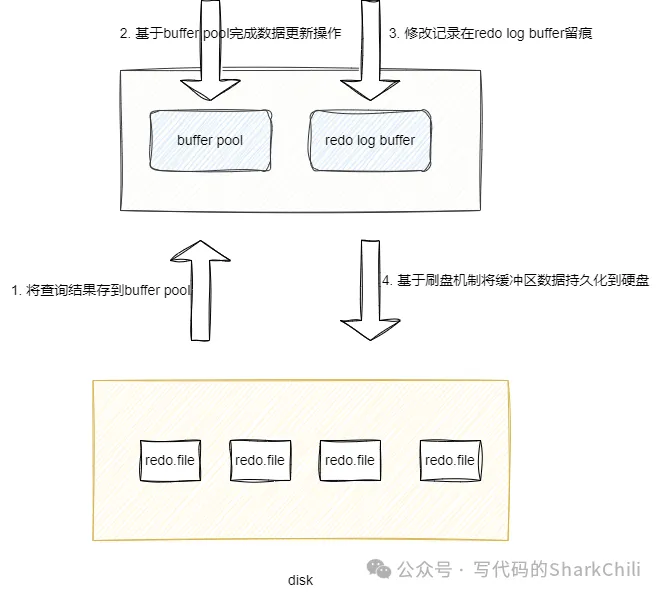
默认情况下日志对应的缓冲区大小为16M,这里面包括了redo.log的缓冲区,该变量我们可以通过如下语句查看:
对应查询结果如下:
redo log的刷盘时机
上文图解的第四步提到了redo log刷盘的操作,当符合以下几种条件时,对应redo log buffer会被刷盘持久化到磁盘中:
- 事务提交:当事务提交时,log buffer里redo log会按照innodb_flush_log_at_trx_commit的刷盘时机将数据持久化到磁盘中。
- log buffer空间不足:log buffer中的redo log已经占满该缓冲区一半时,缓冲区数据就会被刷到磁盘中。
- 事务日志缓冲区已满:InnoDB使用一个事务日志缓冲区(transaction log buffer)存储事务redo log的日志条目,当该缓存区已满时,就会触发日志刷新将日志写入磁盘中。
- checkpoint:线程会定时执行一个checkpoint,将buffer pool已经刷盘对应的redo.log设置为可被覆盖(保证日志空间可以循环复用),这期间对应的redo数据就会被写入磁盘中。
- 服务器关闭:MySQL服务正常关闭时,这些缓冲区的数据就会写入到磁盘中。
redo log的刷盘策略
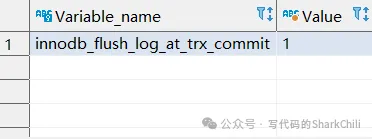
上文事务提交时提到一个刷盘策略的概念,实际上写入磁盘的时机是由MySQL系统参数设置决定的,我们可以键入下面这条SQL查看innodb_flush_log_at_trx_commit这个参数的设定值:
以笔者的MySQL8为例,默认情况下这个参数值为1:
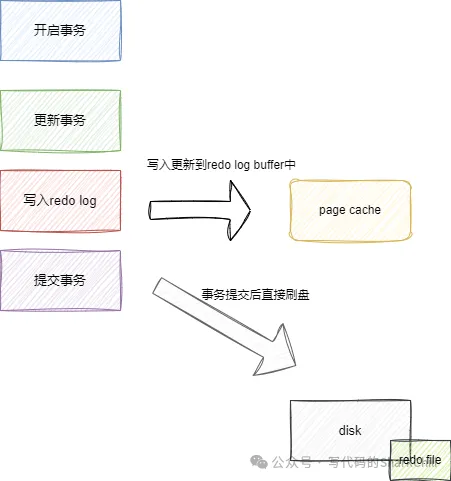
当这个值为0时,每次进行修改写入到redo log buffer,然后redo log buffer会将数据写到page cache中,由log thread每个1s调用操作系统函数fsync将数据写入到redo.file中。很可能因为服务器崩溃或者宕机导致丢失1s的数据。

1为默认值,当参数值设置为1时, 每次进行修改操作后将数据写入到redo log buffer中,一旦事务被提交,就会自动调用操作系统函数fsync将数据写入的磁盘中的redo.file文件中。若设置为这个级别,当服务器宕机,若当前事务没有提交,这部分数据丢失也无妨,事务提交的话,那么这个操作就会被写到磁盘中,照样可以恢复。
配置为2时,每当事务提交后,redo log就会刷入内核缓冲区,这些数据具体何时刷盘则交由操作系统决定,这种情况在MySQL宕机情况下不会造成数据丢失,一旦操作系统崩溃则可能会造成内核缓冲区的redo log数据丢失,导致进行数据备份还原时丢失一部分数据:

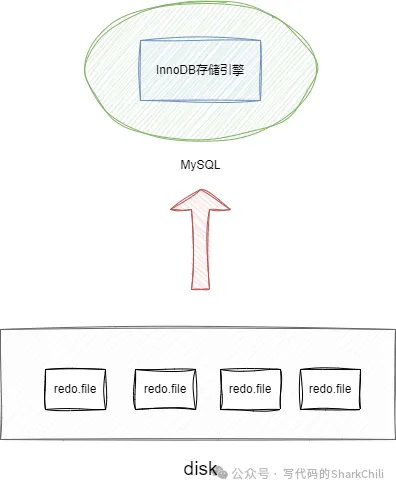
redo log的日志文件组
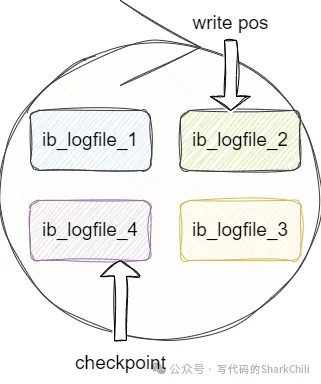
redo log并不是单指一个文件,它是由一组日志文件构成的,如下图所示,这些文件大小都是一样的,写入操作时依次从从1开始写,文件1写满了,就将数据写到文件2,最后写到文件4。
redolog通过write pos标记当前写入的位置,每次完成写入write pos标志位后移,一旦write pos和checkpoint相遇时就说明文件满了,此时innodb就会通过让checkpoint往后移进行一些空间数据擦除,以此来保证一个足够空间容纳新数据。
为什么InnoDB不直接将数据写入磁盘
页是操作系统的基本单位,一页差不多16kb,而我们每次操作的数据可能也就x byte,为了x byte的数据操作将一页的数据进行同步持久化实在有些大材小用了,所以通过redo log buffer记录修改内容,通过刷盘策略进行数据输盘更新,由此提升数据库的并发能力,

bin.log和redo.log对应的二阶段提交
经常有读者面试被问道的为什么我有了undo log,你还需要bin log呢?而且这两个日志我到底要先写哪个才能保证主从数据库的一致性呢?
对此我们不妨用反正法来说明:
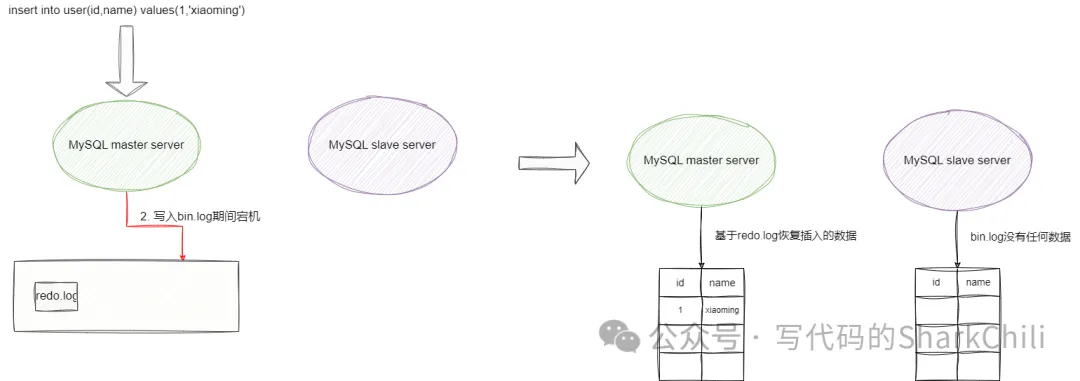
假设我们先写bin.log,当事务提交后bin.log写入成功,结果再写redo.log期间,数据库挂了。重启恢复后,主数据库工具redo.log恢复到bin log写入前的样子,而从数据库在工具bin.log进行数据同步时发现bin log有一条写入操作,最终从数据库比主数据库多了一条数据。

我们再假设写redo log,假设事务执行期间我们就写了redo log,在事务提交之后写bin log数据库挂了,我们重启数据库后主主库恢复。主库根据redo log进行灾备恢复,将我们更新的数据同时恢复回来,而从库根据bin log进行数据同步时,并没有察觉到主库刚刚写入的数据,这就导致了从库比主库少了一条数据。
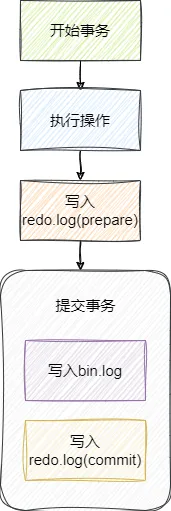
所以MySQL设计者提出了二阶段提交的概念,整体步骤为:
- 在事务开始时,先写redo-log(prepare)。
- 事务提交时,再写bin log。
- 事务提交成功,再写redo-log(commit)。
有了这样一个整体步骤我们不妨用两种情况来举个例子演示一下二阶段提交如何保证数据一致性。
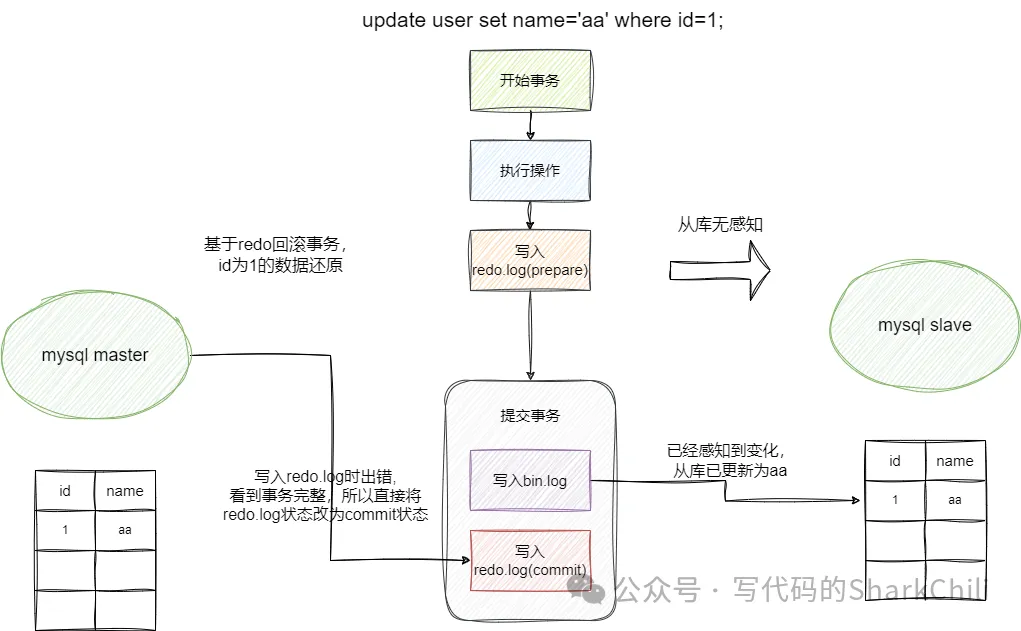
假设我们有一张user表,这张表只有id、name两个字段。我们执行如下SQL:
假如我们在redo.log提交时数据库宕机,二阶段是如何保证数据一致性的呢?
首先数据库重启恢复,然后主库发现redo.log日志处于prepare而且bin.log也没有写入,所以一切恢复到之前的样子(事务回滚),而从库对此无感,同步时也是同步成操作失败之前的样子,一切风平浪静:

假如我们bin.log进行commit成功之后数据库宕机,二阶段提交是如何保证数据库一致性的呢?还是老规矩:
- 数据库重启恢复,然后主库发现bin.log有个commit成功的数据(事务是完整的)
- 然redo.log处于prepare阶段,但是我们还是可以根据情况推断出有个当前主库有个commit成功的事务,所以redo.log会根据bin.log将redo.log设置为commit
- 从库已根据主库的bin.log发现有新增一条新数据,由此同步一条更新数据,双方都有了一条新数据,数据库一致性由此保证: