大型语言模型(LLMs)在生成文本时容易出现“幻觉”,即生成不真实或不忠实的内容,这限制了其在实际场景中的应用。现有的研究主要基于不确定性进行幻觉检测,利用 LLMs 的输出概率计算不确定性,无需依赖外部知识或频繁采样。然而,这些方法通常只关注单个 Token 的不确定性,忽略了 Token 和句子之间复杂的语义关系,导致在多 Token 和跨句子的幻觉检测中存在不足。
在 AAAI2025 上,小红书搜索广告算法团队提出了一种基于语义图增强不确定性建模的幻觉检测方法。首先构建语义图,捕捉实体和句子之间的关系;然后通过实体间的关系进行不确定性传播,提升句子级别的幻觉检测;最后,基于句子与其邻居句子在语义图中的矛盾概率,提出一种图不确定性校准方法,用于不确定性计算。在 WikiBio 和 NoteSum 两个数据集上的实验表明,该方法在段落级别幻觉检测中取得了显著提升,性能提高了 19.78%。
论文标题:Enhancing Uncertainty Modeling with Semantic Graph for Hallucination Detection
论文地址:https://arxiv.org/abs/2501.02020
01、背景
大型语言模型凭借其庞大的参数量和先进的训练方式,在互联网行业的各大业务中得到了广泛应用。然而,由于现有技术的局限性,大语言模型的“幻觉”问题依然无法完全避免。幻觉问题指的是模型生成不真实或忠实性低的内容,这严重影响了模型在实际应用中的可靠性。例如,在小红书的广告创意文本生成中(标题生成、封面二创、笔记辅助创作等业务中),幻觉问题可能导致用户体验下降。因此,幻觉检测成为了一项至关重要的工作。
目前,业内的幻觉检测方法主要分为三类:
1. 基于检索增强的方法:依赖外部知识源,且需要复杂的验证步骤。
2. 基于多次采样的方法:需要多次调用语言模型API进行改写,资源消耗巨大。
3. 基于不确定性的方法:利用文本中每个 Token 的输出概率,通过不确定性度量计算幻觉得分。该方法只需模型执行一次推理,相对高效,因此备受关注。
然而,现有的不确定性方法仍存在两个主要问题:
1. Token 间依赖关系未被充分建模:现有方法通常只关注单个 Token 的不确定性,忽略了 Token 之间复杂的语义关系。
2. 篇章级别不确定性计算不足:现有方法通常通过简单平均句子不确定性来计算篇章级别的不确定性,忽略了句子之间的复杂关系。

02、方法
我们的方法从 Token、句子和篇章三个粒度依次进行不确定性建模,结合语义图技术,显著提升了幻觉检测的准确性。
Token:受幻觉随序列长度增加而累积的启发,我们结合基于 LLMs 的条件概率分布统计与序列衰减,进行 Token 级别的不确定性计算。
句子:考虑到大部分幻觉由句子和段落中的实体及关系引发,我们进一步构建语义图,用于句子和段落级不确定性计算。在句子级别,语义图捕捉实体间的语义关系,支持幻觉传播与计算,实体不确定性沿依赖关系传播至相关实体。
篇章:在段落级别的幻觉检测中,我们结合句子在语义图中的邻居节点进行不确定性校准与汇总。

2.1 Token 级别不确定性
受幻觉随序列长度增加而累积的启发,我们结合基于LLMs的条件概率分布统计与序列衰减,进行 Token 级不确定性计算。具体公式如下:

其中,我们抽取当前 Token 位置的所有词表 Token 中的 Top-K 概率值,计算其最大值和方差。最大值和方差越大,表明模型对该 Token 的置信度越高,幻觉概率越低。同时,我们还引入了序列衰减项,随着序列长度的增加,模型的不确定性也会相应增加。
2.2 句子级别不确定性
考虑到大部分幻觉由句子和段落中的实体及关系引发,我们构建了语义图,用于句子和段落级不确定性计算。在句子级别,语义图捕捉实体间的语义关系,支持不确定性传播与计算。具体公式如下:

其中,实体不确定性通过语义路径进行传播,路径强度由头实体到谓词的注意力分数和谓词到尾实体的注意力分数求平均得到。全局不确定性则通过句子概率的分位点进行计算:

最后,我们将实体不确定性和全局不确定性进行加权求和,得到句子级别的不确定性,如下所示:

2.3 篇章级别不确定性
在篇章级别,我们通过指代消解和实体链接,构建篇章级别的语义图。图中每个节点代表一个句子,边表示句子之间的语义关联强度。我们使用自然语言推理(NLI)模型计算句子之间的冲突概率,并结合句子不确定性进行篇章级别的幻觉检测。具体公式如下:

03、实验
我们在 WikiBio 和 NoteSum 两个数据集上进行了实验。WikiBio 是目前最广泛使用的幻觉检测公开数据集,而 NoteSum 是小红书构建的中文笔记数据集,专门用于验证我们方法的有效性和泛化能力。
3.1 数据集构建
NoteSum 数据集的构建过程分为三个步骤:
- 搜集热门笔记:我们首先收集站内各行业热门的广告笔记素材,并对可能涉及用户隐私的信息进行过滤。
- 生成笔记摘要:利用 LLM 从这些长笔记中生成较短的摘要用于研究,采用了与 WikiBio 相同的标注方法,即也包含事实性和忠实性幻觉。
- 标注幻觉程度:依据 WikiBio 数据集的标注方式,我们对每一条笔记中的每个句子和整个篇章进行了详细标注。每个句子被标注为 Factual(无幻觉)、Non-Factual*(部分幻觉)或 Non-Factual(严重幻觉),而每个篇章则被标注为一个介于 0 到 1 之间的连续性分数,表示整个篇章的幻觉程度。
3.2 评估指标
句子级别:我们使用传统的分类AUC指标,分别评估模型对 Factual、Non-Factual* 和 Non-Factual 三个类别的分类能力。
篇章级别:由于篇章级别的幻觉分数是连续值,我们使用皮尔森相关系数和斯皮尔曼相关系数来评估模型预测的幻觉分数与人工标注的一致性。
3.3 基线方法
我们选择了以下最新的幻觉检测方法作为基线进行对比:
- GPT-3 Uncertainty:该方法使用 GPT-3 模型输出每个 Token 的概率,然后计算各种传统的不确定性分数(如负对数概率和熵)作为幻觉的程度。
- SelfCheckGPT:这是一种基于多次采样的方法,依赖于LLM频繁采样进行一致性检查。我们使用 Gpt-3.5-turbo 进行采样,并应用四种方法来测量一致性,包括 BertScore、QA、Unigram 及它们的组合。
- FOCUS:这是 SelfCheckGPT 的不确定性改良版本,是目前性能最优的基于不确定性的检测方法。我们使用 LLaMA-13B 和 LLaMA-30B 作为其方法的基座模型。
3.4 实验结果
我们的方法在 WikiBio 和 NoteSum 数据集上均取得了最佳性能,尤其在篇章级别幻觉检测中,性能提升了 19.78%,显著优于现有方法。具体实验结果如下:
句子级别:我们的方法在 Factual、Non-Factual* 和 Non-Factual 三个类别上的AUC指标均优于基线方法,尤其是在 Non-Factual 类别上,AUC提升了 12.85%。
篇章级别:我们的方法在皮尔森相关系数和斯皮尔曼相关系数上均取得了最高分,分别达到了 77.60 和 74.44 ,显著优于其他基线方法。

我们还从 Token、句子、篇章三个维度进行了消融实验,验证了各个模块的有效性:
Token 级别不确定性:移除最大值、方差或序列衰减项后,性能显著下降,表明这些项对 Token 级别不确定性建模至关重要。
句子级别不确定性:移除实体不确定性或全局不确定性后,性能均有所下降,尤其是实体不确定性对篇章级别幻觉检测的影响更大。
篇章级别不确定性:移除语义图中的邻居句子矛盾概率后,性能下降了约 2 个百分点,表明图不确定性校准对篇章级别幻觉检测的有效性。

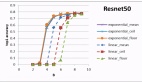
我们进一步对句子级别中的基于语义关系的不确定传播方法、实体和全局不确定性方法和篇章级别中的基于语义图的不确定性检测方法分别进行了可视化分析。
1. 基于语义关系的不确定性传播
与基线方法 FOCUS(所有前置关键词传播到后置关键词)对比,两者对于NonFact(严重幻觉)样本都能有效识别严重幻觉,对于 NonFact*(中等幻觉)和 Factual(无幻觉)样本,FOCUS方法倾向于高估不确定性,导致与真实标签之间存在较大差距。且FOCUS方法的三种不确定性得分非常接近,难以区分不同程度的幻觉。
本文提出的方法通过捕捉语义关系,减少了不确定性高估,能够更精确地检测不同程度的幻觉。

2. 实体和全局不确定性
随着幻觉程度的增加(Factual → NonFact* → NonFact),实体不确定性和全局不确定性的得分均显著上升,且基于两者的分数,三种样本类型之间的重叠较少,能够被较好地区分。进一步验证了实体不确定性和全局不确定性在句子级别幻觉检测中的有效性,能够有效区分不同程度的幻觉。

3. 基于语义图的句子间不确定性检测
与 Adjacent(仅考虑当前句子与前后相邻句子的关系)和 Average(简单平均所有句子的不确定性)两种基线方法相对比,本文提出的基于语义图的句子间不确定性检测在 Pearson 和 Spearman 相关系数上均优于前者,更能有效捕捉长距离语义关系,显著提升了段落级别幻觉检测的性能。

04、结语
本文首次探索了语义图在捕捉 Token 与句子之间复杂关系方面的潜力,提出了一种基于语义图增强不确定性建模的幻觉检测方法。通过对 Token、句子和篇章三个粒度的不确定性建模,我们显著提升了幻觉检测的准确性。实验结果表明,该方法在多个数据集上均取得了显著效果,尤其在篇章级别幻觉检测中表现突出。未来,我们将进一步探索如何将现有知识图与 AMR 图结合,用于事实核查和幻觉检测。
05、作者简介
陈可迪
现硕士就读于华东师范大学,小红书搜索广告团队实习生。在 EMNLP、NAACL、COLING、AAAI 等机器学习、自然语言处理领域顶级会议上发表数篇一作论文,主要研究方向为大语言模型幻觉,大语言模型推理能力增强。
一帆(陶鑫琪)
小红书 NLP 算法工程师(广告创意生成方向),主要研究方向:大模型算法研究、文本可控式生成。
法明(丁博文)
小红书 NLP 算法工程师(广告创意生成方向),主要研究方向:大模型算法研究、文本可控式生成。
清良(谢静文)
小红书 NLP 算法工程师(广告创意生成方向),主要研究方向:大模型算法研究、文本可控式生成。
神宗(谢明宸)
小红书算法工程师(搜索广告方向),主要研究方向:创意生成、模型预估、广告冷启动。