













译者 | 汪昊
审校 | 重楼
推荐系统自 1992 年基于用户的协同过滤算法诞生以来,经历了一波又一波的革新大潮,发展至今,已经形成了一套体系完善,理论严密的技术领域。随着越来越多的基于深度学习的推荐系统模型诞生,该领域关于准确率的追求似乎已经不再吸引人们的眼球。相反,越来越多的人开始关注其他热点技术,比如大模型算法。
2023 年,来自澳大利亚 RMIT 大学的 Yueqing Xuan 等研究人员在 arXiv 上公布了一篇题为 More Is Less: When Do Recommenders Underperform for Data-rich Users? 的论文,指出推荐系统未必数据越多效果越好。这和最近热潮的大模型 Scaling Law 之类的理论形成了鲜明对比。下面,我们带领读者对该篇论文的理论和实验一探究竟。
因为这篇论文主要通过实验来检验数据量和对应算法的效果的对比情况。我们先来了解一下实验中用到的数据和算法。在实验中,我们用到了如下数据集合:
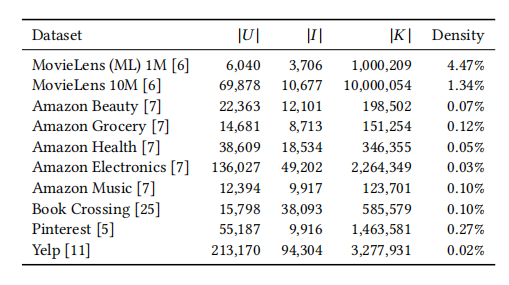
在这个表格中,|U| 代表用户数,|I| 代表物品数,|K| 代表评分数量。作者在实验中用到的都是推荐系统领域经常用到的开源数据集合。
作者在实验中主要检测了如下算法:ItemKNN , Bayesian Personalised Ranking (BPR) , Multi-Variational Auto-encoder (Mult-VAE) , Neural Matrix Factorization (NeuMF) , Light Graph Convolution Network (LightGCN) 和 ADMMSLIM 。 作者使用了开源推荐系统算法库 RecBole 进行对比实验。
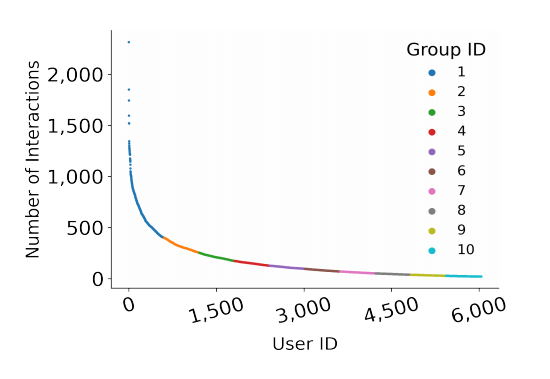
作者按照用户交互数据的丰富程度,把输入数据分成了十份,然后按照八二比率把数据切分成了训练集和测试集。例如,MovieLens 1 M的数据集合的划分如下图所示:
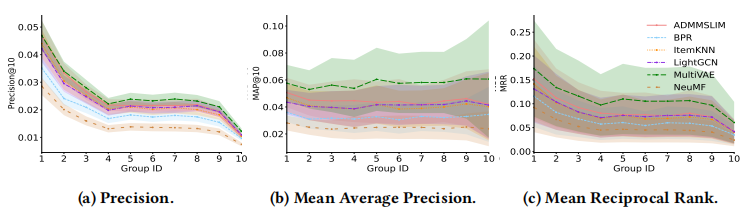
作者在 Pinterest 数据集合上进行了对比测试:
作者随后也在 MovieLens 1M 数据集合上进行了评测,得到了下图:
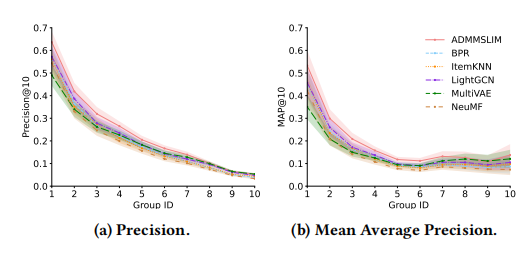
通过进行大量的类比实验和结果可视化,作者得出了以下结论:在所有数据集上,交互丰富的数据类型的精确度(Precision)比其他组要高;Mean Average Precision 指标在各个群组却没有太大的区分度;而对于召回率(Recall)来说,数据越丰富,算法表现却越差。
这篇论文的作者没有用到任何高深的数学知识或者工具,只是利用最普通的数据分析的方法对算法的结果进行统计并用最简单的图形图像工具进行可视化,从而得到了推荐系统不是数据越多越好的重要结论,值得推荐系统从业者认真学习。
我们在互联网行业从事算法相关的工作的时候,除了完成公司制定的 KPI / OKR 指标之外,还应该静下心来思考算法的理论基础和复杂模型背后的原理。这样才能从各个方面深入的理解算法,从而有助于我们设计出更加优秀的技术作品,既满足了工作的需要,也能在学术上给相关领域带来推动作用。
译者简介
汪昊,前达评奇智董事长兼创始人。前 FunPlus 人工智能实验室负责人。在 ThoughtWorks, 百度,联想,网易和 FunPlus 等科技公司有超过 13 年的技术和技术管理经验。精通推荐系统、金融风控、爬虫和聊天机器人等领域。在国际学术会议和期刊发表论文 44 篇。5 次获得国际学术会议最佳论文奖和最佳论文报告奖。2006 年 ACM/ICPC 北美落基山区域赛金牌。2004 年全国大学生英语能力竞赛口语总决赛铜牌。本科(2008年)和硕士(2010年)毕业于美国犹他大学。对外经贸大学(2016 年)在职 MBA 学位。




















