在 Redis中,Set(集合)以其独特的特性和高效的操作模式,在实际应用中得到了广泛的使用。本文将深入分析 Redis Set 的原理、源码实现,并通过示例展示其在实际应用中的使用方式。

一、什么是 Redis Set?
在 Redis 中,Set 是一种无序且不允许重复元素的数据结构,它支持丰富的集合操作,如交集、并集和差集等。这使得 Redis Set 非常适合用于社交网络中的好友列表、标签管理、实时推荐系统等场景。
Redis Set 的特点:
- 无序性:Set 中的元素是无序的,这意味着无法通过索引访问特定元素。
- 唯一性:Set 中的每个元素都是唯一的,重复元素会被自动去重。
- 高效的元素操作:Redis 提供了丰富且高效的命令用于对 Set 进行操作,如添加、删除、获取元素等。
- 丰富的集合操作:支持集合的交集、并集、差集等高级操作。
二、底层实现原理
Redis 对 Set 的实现高度优化,以满足不同场景下的性能需求,具体来说,Redis 使用了两种内部数据结构来表示 Set:
- 整数集合(Intset)
- 哈希表(Hashtable)
1. Intset(整数集合)
当一个 Set 中的所有元素都是整数,并且数量较少时,Redis 会选择使用 Intset 来存储。这种表示方式节省内存,并且在元素较少的情况下提供了较快的访问速度。
结构特点:
- 连续存储:Intset 使用连续的内存块存储整数,类似于一个整数数组。
- 有序性:为了优化查找操作,Intset 会保持内部元素的有序性,使得二分查找成为可能。
- 内存紧凑:由于只是存储连续的整数,内存占用较低。
Intset 的优势:
- 节省内存:对于小规模的整数 Set,Intset 比哈希表节省大量内存。
- 快速查找:有序的结构使得二分查找的时间复杂度为 O(log N)。
Intset 的限制:
- 仅支持整数:如果 Set 中包含非整数元素,无法使用 Intset。
- 动态扩展限制:当元素数量超过阈值,或者出现非整数元素时,需要转换为哈希表。
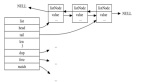
2. Hashtable(哈希表)
当 Set 中包含非整数元素,或元素数量超过某个阈值时,Redis 会将 Set 的内部实现转换为哈希表。这种表示方式虽然在内存占用上稍大,但是支持更丰富的操作和更大的元素规模。
结构特点:
- 散列表存储:使用开放定址哈希表来存储元素,支持快速的插入、删除和查找。
- 支持多种元素类型:不仅支持整数,还支持字符串等其他数据类型。
- 无序性:与 Intset 一样,哈希表中的元素也是无序的。
Hashtable 的优势:
- 高效的操作:哈希表提供了接近 O(1) 的时间复杂度,适用于大规模数据操作。
- 灵活性强:支持多种数据类型,适用于不同的应用场景。
Hashtable 的限制:
- 内存占用较大:相比 Intset,哈希表的内存消耗更高。
- 无序性:尽管支持高效的操作,但无法保证元素的顺序。
3. 内部转换机制
Redis 为了优化性能和内存利用,会根据 Set 的实际内容和规模动态地在 Intset 和 Hashtable 之间进行转换。具体来说:
- 从 Intset 到 Hashtable:当 Set 中的元素个数超过 set-max-intset-entries(默认 512),或者出现非整数元素时,会将内部表示从 Intset 转换为 Hashtable。
- 从 Hashtable 到 Intset:当使用于 Hashtable 的元素数量降至 set-min-intset-entries(默认 128)以下,并且所有元素都是整数时,会将内部表示从 Hashtable 转换为 Intset。
这种动态转换机制保证了 Redis 在不同阶段都能以最佳的方式管理 Set,兼顾性能和内存利用。
三、源码分析
为了深入理解 Redis Set 的实现原理,我们需要分析 Redis 的源代码。以下分析基于 Redis 6.0 版本,但大部分实现逻辑在后续版本中保持稳定。
1. 数据结构定义
在 Redis 的源代码中,Set 的实现主要涉及以下几个关键数据结构:
- robj:Redis 的通用对象结构,用于表示不同的数据类型,包括 Set。
- intset:表示 Intset 的结构。
- dict:Redis 的哈希表实现,表示 Hashtable。
以下是相关结构的简化定义。
2. 创建和销毁 Set对象
当调用 SADD、SREM 等命令时,Redis 首先会检查目标键是否存在。如果不存在,会调用 createSetObject 来创建一个新的 Set 对象。
- 创建 Set 对象的代码片段:
- 销毁 Set 对象的代码片段:
3. Set 操作命令的实现
以 SADD 命令为例,其实现涉及以下几个步骤:
(1) 查找或创建 Set 对象:如果目标键不存在,创建一个新的 Set 对象。
(2) 判断编码类型:根据当前 Set 的编码类型(Intset 或 Hashtable),调用相应的添加元素函数。
(3) 添加元素:
- 如果是 Intset,尝试将元素转换为整数并添加;如果转换失败或超出容量,转换为 Hashtable。
- 如果是 Hashtable,直接进行添加。
(4) 返回结果:返回成功添加的元素数量。
SADD 命令的关键实现代码:
4. Set的集合操作
Redis 支持多种集合操作,如交集(SINTER)、并集(SUNION)和差集(SDIFF)。这些操作通常涉及多个 Set 对象的迭代和元素比较。
以 SINTER 为例,其实现步骤如下:
- 获取所有参与的 Set 对象。
- 选择最小的 Set 作为基准以优化性能。
- 遍历基准 Set 的元素,对每个元素在其他 Set 中进行查找。
- 将存在于所有 Set 中的元素添加到结果 Set。
- 返回结果。
SINTER 命令的关键实现代码:
5. 内部转换逻辑
如前所述,当 Set 的大小或元素类型发生变化时,Redis 会在 Intset 和 Hashtable 之间转换。这一过程涉及内存重新分配和数据拷贝。
从 Intset 到 Hashtable 的转换:
从 Hashtable 到 Intset 的转换:
6. 内存管理和优化
Redis 对 Set 的内存管理进行了深度优化,以确保在不同的使用场景下都能高效地利用内存。具体措施包括:
- 共享对象:对于经常使用的小整数,Redis 通过对象共享机制(Shared Objects)减少内存占用。
- 内存分配器优化:Redis 使用 jemalloc 作为默认的内存分配器,通过优化内存分配策略提升性能。
- 惰性删除:在哈希表中删除元素时,Redis 采用惰性删除策略,避免高频次的重新哈希操作。
四、Redis Set 的使用示例
为了更好地理解 Redis Set的实用性,下面我们将通过几个具体的示例展示它在实际应用中的使用方式。
1. 用户兴趣标签管理
假设有一个应用需要管理用户的兴趣标签,Set 是理想的选择,因为它能有效地保证标签的唯一性,并支持高效的添加、删除和查询操作。
示例场景:
- 一个用户可以拥有多个兴趣标签,如“音乐”、“编程”、“旅游”等。
- 用户可以添加或删除兴趣标签。
- 需要查询用户的所有兴趣标签。
Redis 命令示例:
示例解释:
- SADD 命令用于添加一个或多个元素到 Set 中。重复的元素会被自动忽略。
- SREM 命令用于从 Set 中删除一个或多个元素。
- SMEMBERS 命令返回 Set 中的所有成员。
- SISMEMBER 命令用于检查一个元素是否存在于 Set 中。
2. 共同好友推荐
在社交网络中,推荐共同好友是一个常见功能。Set 的交集操作为实现这一功能提供了高效的手段。
示例场景:
- 用户 A 和用户 B 的好友列表都是 Redis 的 Set。
- 需要找出 A 和 B 的共同好友数量。
Redis 命令示例:
示例解释:SINTER 命令返回所有给定集合的交集成员。在本例中,即为用户 A 和用户 B 的共同好友。
3. 实时在线用户统计
在实时应用中,经常需要统计当前在线的用户列表。Set 的添加、删除和计数功能使其成为理想的选择。
示例场景:
- 当用户上线时,将用户 ID 添加到在线用户 Set 中。
- 当用户下线时,从 Set 中移除用户 ID。
- 统计当前在线用户数量。
Redis 命令示例:
示例解释:SCARD 命令返回 Set 中的元素数量,用于统计在线用户数量。
4. 关键词去重
在数据处理过程中,常常需要对关键词进行去重。Set 的唯一性保证了关键词的唯一性,适合用于此类场景。
示例场景:从大规模文本中提取关键词,并存储到 Redis 的 Set 中,自动去除重复关键词。
Redis 命令示例:
示例解释:重复的"redis"关键词在 Set 中只会存储一次,确保关键词的唯一性。
五、扩展与高级功能
Redis Set 作为基础的数据结构,还支持一些扩展和高级功能,进一步增强了其应用的灵活性和 powerfulness。
1. 集合的交集、并集和差集
Redis 提供了 SINTER, SUNION, SDIFF 等命令,用于执行集合的交集、并集和差集操作。这些操作在群组管理、标签分析等场景中非常有用。
示例:
2. 随机元素获取
有时需要从 Set 中随机获取一个或多个元素,Redis 提供了 SRANDMEMBER 命令来满足这一需求。
示例:
3. 元素迭代
通过 SSCAN 命令,可以对 Set 进行迭代,适用于处理大规模 Set 的场景,有助于避免长时间阻塞 Redis 服务。
示例:
4. 结合其他数据结构
Redis 允许将 Set 与其他数据结构组合使用,构建更加复杂和高效的数据模型。例如,使用 Hash 和 Set 结合,管理用户的详细信息和兴趣标签。
示例:
六、总结
本文,我们详细分析了 Redis 的 Set数据结构,通过深入分析其底层实现原理,包括 Intset 和 Hashtable 的动态转换机制,以及其相关的源码,可以帮助我们更好地利用 Redis Set,实现高性能、高可靠的应用系统。