引言
紧接上篇的文章,我们继续往上盖大楼,现在我们已经盖到了第 500 楼了,不要往下看,除非你是勇者,不然你会吓到你自己。
这一篇的东西也是挺多的:Prometheus Agent。
Prometheus 一直是 Kubernetes 生态中不可或缺的监控工具。然而,随着分布式系统的复杂性增加以及边缘计算、Serverless 技术的广泛应用,传统的 Prometheus Server 已不再适合所有场景。为了应对这些挑战,Prometheus 引入了一种轻量级运行模式:Prometheus Agent。
Prometheus Agent 专注于指标的采集和推送,省去了存储和查询的功能,使其在资源受限的环境中更加高效。
本文将详细介绍 Prometheus Agent 的运行机制、使用场景以及部署方式,并分享一些最佳实践。
介绍
什么是 Prometheus Agent?
Prometheus Agent 是 Prometheus 自 v2.33.0 版本起引入的一种运行模式,其主要特点包括:
- • 轻量化:专注于数据的采集与推送,不存储数据,也不提供查询能力。
- • 高效:减少了本地存储和查询相关的资源占用。
- • 推送模式:通过 remote_write 将采集到的指标推送到远程存储或中央 Prometheus Server。
这种模式特别适合边缘场景、Serverless 环境以及需要集中化监控的分布式系统。
Prometheus Agent 的适用场景
边缘计算
在边缘计算场景中,设备通常资源有限,难以运行完整的 Prometheus Server。Prometheus Agent 通过其轻量化特性,可以高效采集边缘设备的指标,并将数据推送到中央监控系统。
Serverless 环境
对于 Serverless 服务(如函数计算、API 网关等),Prometheus Agent 可以动态采集相关指标,并避免因存储和查询功能导致的资源浪费。
集中式监控
在大型分布式系统中,可通过在每个子系统中部署 Prometheus Agent,将所有数据集中推送到远程存储(如 Cortex、Thanos),实现统一的存储与查询。
高性能监控
对于大规模集群,Agent 模式可减少单点 Prometheus Server 的负载,将存储和查询功能卸载到远程存储。
为什么需要 Prometheus Agent
Prometheus Agent 其实只是 Prometheus 的一种特殊运行状态,在 prometheus-operator 中以 PrometheusAgent 这个 CRD 体现,但其内部控制逻辑与 Prometheus CRD 一致。
之所以需要 Prometheus Agent,我们其实可以从 Prometheus 的官方文档[1]一窥究竟。Prometheus Agent 本质上就是将时序数据库能力从 Prometheus 中剥离,并优化 Remote Write 性能,从而让其成为了一个支持 Prometheus 采集语义的高性能 Agent。这样一来,Prometheus Agent 还可以部署在一些资源受限的边缘场景进行数据采集。
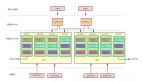
“众所周知”,Prometheus 作为数据库而言,查询性能和可扩展性相对较弱,这也是为什么 Remote Write 会如此流行以至于又成为了一个事实上的标准:因为大家都希望将数据转存在性能更高的数据库上但又希望继续兼容 Prometheus 的采集逻辑(因为很好用)。Agent 模式其实如大家所意,禁用了查询、报警和本地存储功能,并用了一个特殊的 TSDB WAL 来临时存储数据,从而整体架构如下所示:
 图片
图片
这种架构某种程度是推拉结合的模式。Metrics 的采集采用 Pull 模式,而其存储则采用 Push 模式。对于高吞吐的写入,Push 模式其实对写入更友好。因为我们总是可以以 Batch 模式来集中向远端写入大批数据。这种模式下的 Prometheus 其实是无状态,更便于部署和 Scrape Job 的分片。
其实,这类兼容 Prometheus 采集语义的 Agent 社区有不少可供选择,比如 vmagent[2] 和 vector[3]。VictoriaMetrics 还曾经对 Prometheus Agent, vmagant 和 Grafana Agant 做过一个性能报告[4]。不过很快,Grafana Agent 就停止开发并转成维护模式[5]。Grafana 又造了另一个项目 Alloy[6],重点支持 OpenTelemetry,当然又造了一个与 Terraform 语法酷似的配置语言的 DSL。
从长期技术演技来看,Agent 总是兵家必争之地,因为可以守住数据入口可以做的事情比较多。大家总是希望 Agent 能:
• 具有极低的 CPU 和 Memory footprint,因为它们通常会以 sidecar 或者 daemonset 的形式进行部署,资源极度受限;
• 兼容更多的前端采集协议和后端写入逻辑;
• 具备一定的数据的编排能力(或者称为 pipeline ?),即采集后的数据能以一定的规则进行改写和转换;
• 技术中立;
Prometheus Agent 数据采集工作流程
采集目标的发现:
• 如果你使用 scrape_configs,Agent 会直接按照配置中的 targets 抓取数据。
• 如果你使用 ServiceMonitor 或 PodMonitor,Agent 会通过 Prometheus Operator 的自动发现机制,找到符合条件的服务或 Pod(我们使用这种方式)。 数据采集:
• Prometheus Agent 会周期性地访问这些目标的 /metrics 端点,抓取指标数据。 数据推送:
• Agent 使用 remote_write 将采集到的指标数据推送到远程存储(例如 Prometheus Server 或 GreptimeDB)。
开始
与 GreptimeDB 的集成
GreptimeDB[7] 作为一个新款的开源 TSDB 很早就支持了 Prometheus Remote Write[8]。我们其实可以直接使用 PrometheusAgent 这个 CRD 来定义基于 GreptimeDB Remote Write 的 Prometheus Agent。这样以来,用户其实无需做过多 CR 的改动就能直接将数据接入到 GreptimeDB 中。
这边的思路是所有的数据都存储在 远程存储 中,Prometheus 本身不存储数据
部署 greptimedb-operator[9]
greptimedb-operator[10] 同时支持管理 GreptimeDB Standalone 和 Cluster 模式,用户可以根据自己需要创建相应的 CR。
快速启动一个 Standalone 模式下的 GreptimeDB
用的资源比较多,毕竟需要存储大量数据,还要被 Prometheus 读取
我们可以通过观察 GreptimeDBStandalone 的状态来判断其是否启动成功:
Ingress:
优化 GreptimeDB 的配置文件:
更改完成后,等待 Pod 重启,如果不行,就手动重启
数据可视化
自 GreptimeDB v0.2.0 版本以来,控制台已经默认嵌入到 GreptimeDB 的 binary 文件中。在启动 GreptimeDB 单机版[11]或分布式集群[12]后,可以通过 URL http://localhost:4000/dashboard 访问控制台,我这边使用的 Ingress。控制台支持多种查询语言,包括 SQL 查询[13]和 PromQL 查询[14]。
提供不同种类的图表,可以根据不同的场景进行选择。当你有足够的数据时,图表的内容将更加丰富。
 图片
图片
可以看到并没有什么大问题,但是到后面我感觉到有一个 Bug,就是它有时候会莫名其妙地不能访问(可能是我 Mac 本地环境的原因,我使用的 OrbStack[15](可以帮助我迅速启动一个 K8s 集群, 只支持 Mac)),就是 404 Not Found,我后来就是在它的 YAML 文件换一下镜像,然后重新部署就好了,很奇怪,当时弄了半天。
看到这里,如果 GreptimeDB 的相关人员看到了,希望重视下这个问题。
创建 Promethus Agent 实例并将 Remote Write 设置为 GreptimeDB
这边配置下 GreptimeDB,我是用 Ingress 给 GreptimeDB 做的域名解析,你自己可以选择
如果你想要更严谨地找去你想要的数据,可以使用下面的,你们需要替换你们自己的 Label
serviceMonitorSelector 和 podMonitorSelector:Prometheus-Agent 会根据这些选择器,动态发现并抓取符合条件的 ServiceMonitor 和 PodMonitor 还有 namespaceSelector 指定的指标。
matchExpressions 语法
• key: 标签的名称。
• operator:
a.In: 标签值必须在 values 列表中。
b.NotIn: 标签值不能在 values 列表中。
c.Exists: 标签必须存在。
d.DoesNotExist: 标签不能存在。
• values: 用于匹配的值列表(仅适用于 In 和 NotIn 操作符)。
示例逻辑
• 匹配 app 标签的值是 frontend 或 backend。
• 排除 environment 标签的值为 dev 的目标。
• 包含所有有 team 标签的 PodMonitor。
namespaceSelector
• 限定匹配的命名空间,例如 default 和 monitoring。
但是如果你想要匹配所有的话,可以这样:
Resources 优化
它占用的资源也是挺多的
完整 YAML 文件
Apply
我部署完成之后,就一直报错,当时很纳闷:
 图片
图片
弄了半天,问题才发现是版本的问题。
我的 Prometheus-Operator 的 Prometheus 是 3.0.1 版本,而我的 Prometheus Agent 使用的版本是 2.53.0,所以,这边把我的 Prometheus Agent 的版本改成和 Prometheus 的版本,就可以了。
更新 Prometheus YAML 文件
我这边使用的是 Prometheus-Operator 的 Github[16] 仓库,这边没有使用 Helm 安装,使用的 Manifest
最后我们来看下我们上面两个 Pod 的资源占用情况
可以看到,它们的资源占用还是挺夸张的
测试连接 GreptimeDB
安装 MySQL 客户端
我这边使用的是 Mac
在 Linux
如果你使用的是 Ubuntu 或其他基于 Debian 的发行版:
如果你使用的是 CentOS 或基于 RedHat 的发行版:
在 macOS
你可以使用 Homebrew 来安装:
注意:安装完成后,可能需要将 MySQL 客户端的路径加入环境变量。运行以下命令:
在 Windows
• 下载并安装 MySQL Shell 或 MySQL Workbench 客户端工具。
• 官方下载链接:MySQL Community Downloads[17]
使用 MySQL 客户端连接服务
一旦安装完成,你可以通过以下命令连接到目标服务:
通过 kubectl port-forward
确保你暴露了服务端口,例如:
然后使用 MySQL 客户端
测试数据
数据写入成功 !
使用 Grafana 渲染数据
我们可以直接跳过 Remote Read 直接对接 GreptimeDB,将其作为 Prometheus Datasource,设置对应的 URL 为:http://greptimedb.kubernetes.click/v1/prometheus/
我们这里配置我们的 YAML 文件,配置两个数据源,我们可以做个对比。
验证 Grafana
只有一小部分的 Dashboard 有数据,大部分都没有,真的很纳闷
没有数据的
 图片
图片
有数据的

可以看到我们报错了,我这里使用 Prometheus 作为数据源没有问题,但是使用 GreptimeDB 就有点问题,但是我们确实有数据

我们大家可以思考下,这个问题我觉得涉及的范围还是挺大的,我感觉是权限的问题 RBAC 之类的,或者是 Prometheus 写入的问题,或者是 Prometheus-agent 搜集的问题
可能原因
数据源不匹配
当前的 Grafana Dashboard 是基于某些特定的数据源和字段(例如 cluster 字段)设计的。
但是,数据源(比如 Prometheus 或 GreptimeDB)中可能没有这些字段。
不完整的数据
如果 Prometheus 或 GreptimeDB 中没有完整的数据(比如缺少某些 Kubernetes 相关的指标),查询这些字段会导致错误。
比如,你的数据源中没有 kube_namespace_status_phase, kube_pod_info, 等字段。
GreptimeDB 的数据不兼容
如果通过 Prometheus Remote Write 将数据写入 GreptimeDB,但没有正确配置查询映射,GreptimeDB 中的数据结构可能与 Dashboard 的预期不匹配。
Dashboard 配置问题
使用的 Dashboard 是针对不同环境(或数据源)的。比如,这个 Dashboard 可能是为标准的 Prometheus 配置的,而不是你的特定场景。
字段不匹配
GreptimeDB 和 Prometheus 原始格式存在差异。当前的 Grafana Dashboard 很可能是为 Prometheus 数据源设计的,查询语句中引用了 cluster 等字段,而这些字段可能在 GreptimeDB 中不存在或没有被正确映射。
Prometheus Remote Write 不完整
如果 Prometheus 的 Remote Write 配置不正确,写入到 GreptimeDB 的数据可能不包含全部指标。例如,某些 Kubernetes 相关的指标可能被过滤掉了。
GreptimeDB 数据格式的差异
GreptimeDB 存储时可能对 Prometheus 的数据结构进行了优化或调整,导致字段名、格式等与 Dashboard 的查询不匹配。
GreptimeDB 的查询兼容性
GreptimeDB 是否完全兼容 PromQL(Prometheus Query Language)也需要验证。如果不完全兼容,则某些 Grafana 查询可能无法执行。
引用链接
[1] 官方文档:https://prometheus.io/blog/2021/11/16/agent/
[2]vmagent:https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/docs/vmagent.md
[3]vector:https://vector.dev/docs/reference/configuration/sources/prometheus_scrape/#how-it-works
[4]性能报告:https://victoriametrics.com/blog/comparing-agents-for-scraping/
[5]维护模式:https://github.com/grafana/agent
[6]Alloy:https://github.com/grafana/alloy
[7]GreptimeDB:https://github.com/GrepTimeTeam/greptimedb
[8]Prometheus Remote Write:https://docs.greptime.com/user-guide/write-data/prometheus
[9]部署 greptimedb-operator:https://github.com/GreptimeTeam/helm-charts/tree/main/charts/greptimedb-operator
[10]greptimedb-operator:https://github.com/GreptimeTeam/greptimedb-operator
[11]单机版:https://docs.greptime.com/zh/getting-started/installation/greptimedb-standalone[
12]分布式集群:https://docs.greptime.com/zh/getting-started/installation/greptimedb-cluster
[13]SQL 查询:https://docs.greptime.com/zh/user-guide/query-data/sql
[14]PromQL 查询:https://docs.greptime.com/zh/user-guide/query-data/promql
[15]OrbStack:https://orbstack.dev/
[16]Github:https://github.com/prometheus-operator/prometheus-operator[17]MySQL Community Downloads: https://dev.mysql.com/downloads/