连接查询算是日常比较常用的数据库关联关键字涉及左外连接、右外连接、内连接三种连接方式,本文将从MySQL 8.0的角度针对连接查询和优化进行深入解析,希望对你有帮助。

一、详解MySQL left join
1. 关联查询案例介绍
我们现在有一个驱动表customer,它存储客户id、姓名以及出生日期,默认情况下id是主键,没有任何索引,对此我们给出DDL语句:
CREATE TABLE `customer` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;customer有一张关联表,c_id记录着与其关联数据的id,并用available_balance记录客户余额,对应DDL如下,可以看到此时我们没有添加任何索引:
CREATE TABLE `customer_balances` (
`id` bigint NOT NULL AUTO_INCREMENT,
`c_id` bigint NOT NULL,
`available_balance` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1863126107830751234 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;假设此时数据库大约有2000w的数据,我们希望查出姓名为if2vbdr1kzk47rdmulrxix48tl2r9finmonxpl25cfrqvv7m0t的用户的出生日期和可用余额,如果没有记录余额则设置为null,对应我们给出这样一条SQL:
SELECT name,birthday from customer c
left join customer_balances cb on c.id =cb.c_id
WHERE name='if2vbdr1kzk47rdmulrxix48tl2r9finmonxpl25cfrqvv7m0t';最终查询结果如下,耗时大约是1s多一些,对于用户而言超过200ms的延迟都是有感知的,所以针对这个查询我们需要进行相应的优化,对此笔者以市面上常见的面经为出发点,逐步拆解并解决这道问题:
name |birthday |available_balance|
--------------------------------------------------+-------------------+-----------------+
if2vbdr1kzk47rdmulrxix48tl2r9finmonxpl25cfrqvv7m0t|2024-12-01 11:02:35| 25853253|2. 讲讲join的原理
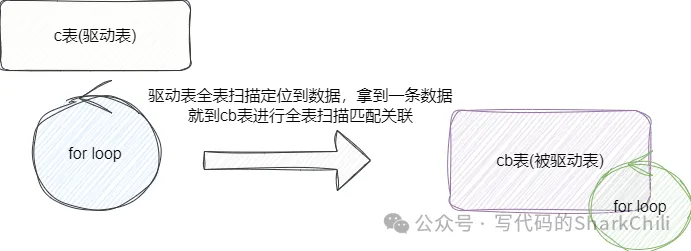
join底层关联本质上都是基于驱动表(上面的c表)的结果到被驱动表(上面的cb表)进行循环扫描定位,这里笔者以MySQL5.7、MySQL 8两个版本对join连接的几种类型进行介绍:
(1) Simple Nested-Loop Join:这也就是我们上文中两张关联表没有加索引关联查询,得到所有驱动表c的数据后,直接给cb表走全表扫描定位匹配,极端情况下要查询count(c)*count(cb)次,也就是我们传说中的时间复杂度为O(n^2):
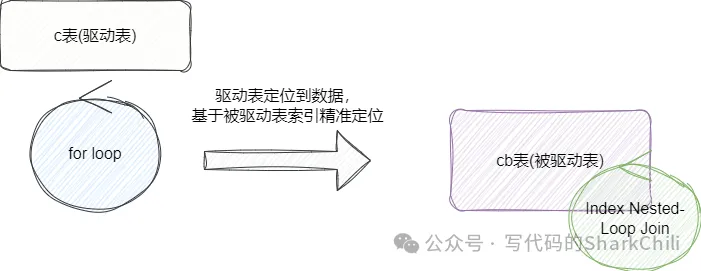
(2) Index Nested-Loop Join:这就是join左右字段都加索引后的查询,这意味着驱动表的选择不在于我们自身,而是由MySQL优化器决定,当驱动表的结果交给被驱动表时,被驱动表直接通过索引定位到关联数据并阻塞。
(3) Block Nested-Loop Join:没有索引列的情况都会选择该算法而不优先考虑Simple Nested-Loop Join,Block Nested-Loop Join相比Simple Nested-Loop Join多了一个中间操作,它会将驱动表查询结果缓存到join buffer,与被驱动表关联时会进行批量内存关联与合并。

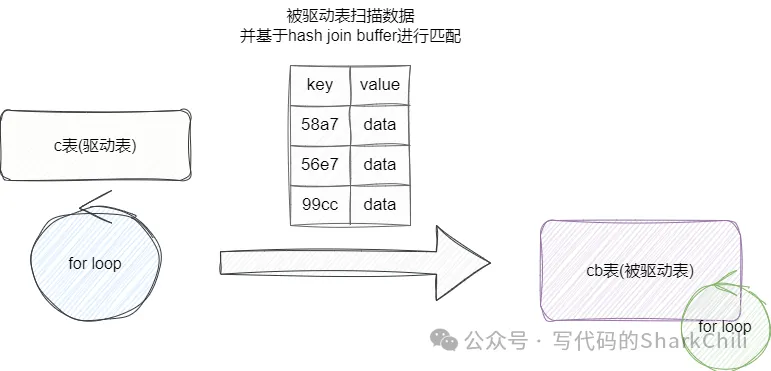
(4) HashJoin:这是8.0.18及其之后的版本对于关联查询的优化,其原理是针对驱动表join字段进行哈希运算生成结果集存入内存中,然后扫描被驱动表并直接通过哈希运算定位到驱动表是否存在关联的值已完成结果合并。当然如果驱动表数据量大的话,驱动表部分数据还会利用磁盘进行分片,生成临时文件,然后被驱动表同样是通过哈希运算定位到磁盘分片编号进行物理磁盘IO获取关联结果。
3. 能不能说说这个LEFT JOIN如何加索引
上文提到查询耗时为1s多,针对索引添加我们优先使用explain 来分析一下SQL的查询过程:
explain SELECT c.name,c.birthday,cb.available_balance
from customer c
left join customer_balances cb on c.id =cb.c_id
WHERE name='if2vbdr1kzk47rdmulrxix48tl2r9finmonxpl25cfrqvv7m0t';以我们的SQL为例该查询首先查询驱动表c,它会基于where条件进行全表扫描获取数据,基于查询结果缓存到hash join buffer再到关联表即被驱动表的聚簇索引进行全表扫描匹配结果:
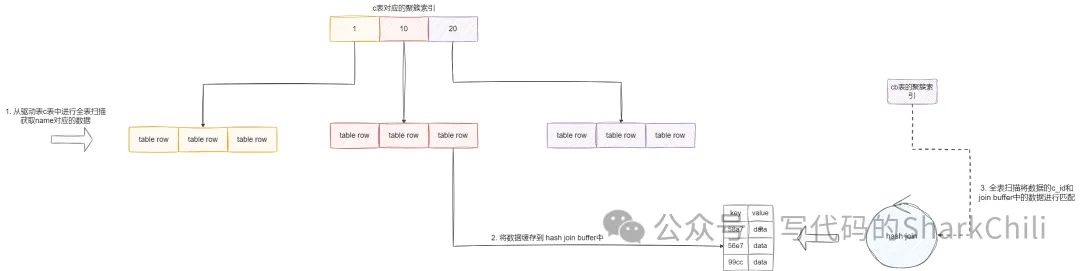
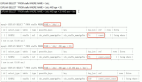
这一点我们也可以从执行计划看出,c表和cb表都走了全表扫描,且关联查询时被驱动表cb用到MySQL 8的hash join关联,这种关联方式本质上就说
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows |filtered|Extra |
--+-----------+-----+----------+----+-------------+---+-------+---+-------+--------+------------------------------------------+
1|SIMPLE |c | |ALL | | | | |3079319| 10.0|Using where |
1|SIMPLE |cb | |ALL | | | | |3447555| 100.0|Using where; Using join buffer (hash join)|针对该执行计划,我们进行逐步的调优,针对驱动表c的查询,因为用到了name字段,所以针对name添加一个索引:
ALTER TABLE db.customer DROP INDEX customer_name_IDX;
CREATE INDEX customer_name_IDX USING BTREE ON db.customer (name);经过调整之后,查询耗时提升为0.739s,查看执行计划,可以看到针对驱动表的慢查询已经走索引了,现在问题就是出在被驱动表cb还是走全表扫描:
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra |
--+-----------+-----+----------+----+-----------------+-----------------+-------+-----+-------+--------+------------------------------------------+
1|SIMPLE |c | |ref |customer_name_IDX|customer_name_IDX|403 |const| 1| 100.0| |
1|SIMPLE |cb | |ALL | | | | |4566577| 100.0|Using where; Using join buffer (hash join)|所以我们针对被驱动表cb的c_id增加一个索引:
CREATE INDEX customer_balances_c_id_IDX USING BTREE ON db.customer_balances (c_id);最终查询耗时优化为0.001s,
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows|filtered|Extra|
--+-----------+-----+----------+----+--------------------------+--------------------------+-------+-------+----+--------+-----+
1|SIMPLE |c | |ref |customer_name_IDX |customer_name_IDX |403 |const | 1| 100.0| |
1|SIMPLE |cb | |ref |customer_balances_c_id_IDX|customer_balances_c_id_IDX|8 |db.c.id| 1| 100.0| |4. left join on 左右字段是否都需要加索引?为什么?
回答这个问题,我们首先需要了解左外连接的工作机制,它本质上就是基于驱动表(也就是上文的c表)的id与被驱动表cb进行链接,如果cb没有数据则结果显示null:
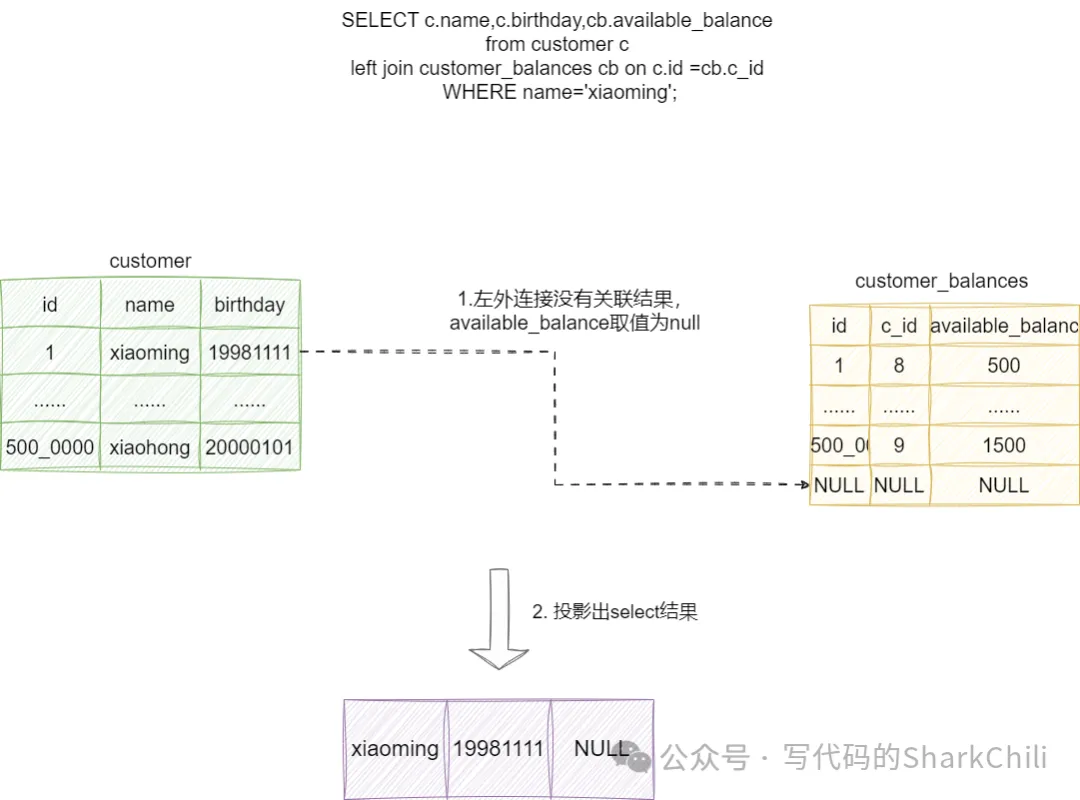
这也就意味着left join左边的字段是基于where条件的查询结果筛选出来的数据,然后遍历并与被驱动表cb进行关联,所以如果left join左边(也就是我们驱动表c的id)如果不作为查询条件的情况下,可以不加索引,当然我们本次关联的id本身就是主键,所以这个问题就没有讨论的必要了。
对于left join的右边,它是作为被驱动表(也就是我们的cb表)的关联查询条件,从执行计划就可以看出如果没添加索引,它会基于驱动表c给的关联条件id进行全表扫描以找到符合条件的数据,所以为了提升被驱动表cb的检索速度,关联条件c_id是需要增加索引的。
5. 你觉得针对联表查询还有那些优化技巧
除了上述优化技巧,针对关联查询我们可以从表结构设计以及SQL查询层面考虑优化:
- 如果业务上允许的话,可以考虑将关联的字段冗余一份到驱动表上,直接避免关联查询开销。
- 如果驱动表和被驱动都具备筛选能力(即关联的表都可以通过where查询到需要的数据),可以考虑用数据量小的表作为驱动表,采用小表驱大表的方式完成关联查询。
- 非必要不采取left join或者right join,尽可能在关联条件上加索引,然后通过inner join让MySQL优化器帮我们选择驱动表并完成数据检索。
二、小结
在数据库操作领域,MySQL 的 LEFT JOIN 无疑是一项极为重要的功能,它为我们提供了从多个表中获取关联数据的强大能力。然而,随着数据量的不断增长以及业务逻辑的日益复杂,LEFT JOIN 的性能问题逐渐凸显,成为开发者和数据库管理员需要重点关注的方面。
本文深入探讨了一系列针对 LEFT JOIN 的性能优化策略。
首先,我们详细分析了合理设计表结构对性能的巨大影响。通过确保表的主键、外键以及索引的正确设置,可以显著减少数据库在执行 LEFT JOIN 操作时的搜索范围,提高查询效率。例如,为频繁用于连接条件的列创建合适的索引,能够让数据库快速定位到相关数据,避免全表扫描带来的性能损耗。 索引优化方面,我们了解到复合索引的巧妙运用以及避免索引失效的重要性。
复合索引可以在多个列上创建单一索引结构,从而在多条件查询时发挥重要作用。同时,要注意查询语句的书写方式,避免因不当的操作符或函数使用导致索引失效,确保索引能够在 LEFT JOIN 操作中充分发挥作用。 查询语句的优化也是关键环节。我们学会了通过简化查询逻辑、合理利用子查询以及使用 STRAIGHT_JOIN 等方式来引导数据库优化器生成更高效的执行计划。这些优化手段能够帮助数据库更好地理解我们的查询意图,合理分配资源,从而提升 LEFT JOIN 的执行速度。
此外,数据库的配置参数对 LEFT JOIN 性能也有着不可忽视的影响。通过调整诸如内存分配、缓存大小等参数,可以为数据库的运行提供更有利的环境,进一步提升 LEFT JOIN 的执行效率。
在实际应用中,我们应当根据具体的业务场景和数据特点,综合运用这些优化策略。同时,持续进行性能测试和监控,及时发现并解决性能瓶颈问题。只有这样,我们才能在充分利用 LEFT JOIN 强大功能的同时,确保数据库系统的高效稳定运行,为业务的发展提供坚实的数据支持。希望本文所介绍的优化策略能够帮助读者在处理 MySQL LEFT JOIN 相关问题时更加得心应手,提升数据库应用的整体性能和质量。