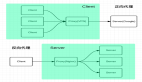
1.Logstash
Logstash是一个开源的服务器端数据处理管道,可以同时从多个来源采集数据,转换数据,然后将数据发送至指定的存储库中。
特点
- 优点:Logstash 支持多种输入源,包括 MySQL,可以轻松配置。
- 缺点:可能对系统资源造成较大消耗,尤其是在大数据量的情况下;配置相对复杂。
- 代码侵入性:低,因为不需要修改应用程序代码。
- 应用场景:适用于小到中等规模的数据同步需求,或者作为临时解决方案。
实现方式
使用 Logstash 的 JDBC 插件连接 MySQL,通过定时任务定期抽取数据并写入 ES。此方法依赖于 MySQL 的 binlog 或者全量扫描表来获取最新数据。
配置示例
2.基于 Binlog 的增量同步工具(如 Canal)
Canal是阿里巴巴集团提供的一个开源产品,能够通过解析数据库的增量日志,提供增量数据的订阅和消费功能。Canal的原理是伪装成MySQL的从节点,从而订阅master节点的Binlog日志。通过订阅binlog的方式实现数据实时同步,在不影响源数据库的情况下,同步延迟可降至毫秒级别。
特点
- 优点:能够实现几乎实时的数据同步,且只传输变更的数据,效率高。
- 缺点:部署和维护成本较高,需要深入理解 MySQL 的 binlog 格式。
- 代码侵入性:低,不改变现有业务逻辑。
- 应用场景:适合大规模生产环境中的高并发、低延迟要求的应用。
实现方式
Canal 模拟 MySQL slave 读取 master 的 binlog 事件,然后将这些更改应用到 ES 上。其他类似工具还有 Maxwell 和 Debezium。
3.同步双写
同步双写是指在进行数据写入操作时,同时向两个或多个数据库写入相同的数据。在MySQL与ES的同步场景中,其主要目的是将MySQL中的业务数据实时同步到ES中。
特点
- 优点:实现简单直接,对于开发人员来说易于理解和实施。
- 缺点:增加了系统的复杂性和潜在的错误点,可能导致数据一致性问题。
- 代码侵入性:高,需要在应用层面上进行额外编码以确保每次更新都同时作用于 MySQL 和 ES。
- 应用场景:适用于小型项目或初期开发阶段,当性能不是主要考虑因素时。
实现方式
每当有数据变化时,在应用程序中同时向 MySQL 和 ES 发出写入请求。
4.异步双写
使用中间件或服务(如Apache Kafka)。在MySQL进行新增/修改操作时,异步地将数据通过Kafka异步写入到ES中。
特点
- 优点:提供了良好的扩展性和容错能力,适合构建复杂的数据流管道。
- 缺点:由于MQ是异步消费模型,用户写入的数据不一定可以马上看到,消息挤压等会造成延时。
- 代码侵入性:取决于具体实现,但一般较低。
- 应用场景:特别适合需要处理大量数据或复杂转换逻辑的企业级应用。
实现方式
Kafka 作为消息队列收集来自 MySQL 的变更记录,异步处理这些消息将结果写入 ES。
5.小结
以上四种方案各有千秋,选择哪一种取决于项目的具体情况,例如数据量大小、实时性要求、团队技术背景等。无论采用哪种方式,保持数据的一致性和正确性都是至关重要的。此外,考虑到 ES 的文档模型与 MySQL 的表格模型之间的差异,在设计索引结构时应充分考虑如何映射字段以及是否需要对原始数据进行预处理。