













写在前面 & 笔者的个人理解
从自车的驾驶轨迹中生成真实的视觉图像是实现自动驾驶模型可扩展训练的关键一步。基于重建的方法从log中生成3D场景,并通过神经渲染合成几何一致的驾驶视频,但它们对昂贵标注的依赖限制了它们在野外驾驶场景中的泛化能力。另一方面,生成模型可以以更通用的方式合成动作条件驾驶视频,但往往难以保持3D视觉的一致性。本文介绍了DreamDrive,这是一种结合生成和重建优点的4D时空场景生成方法,用于合成具有3D一致性的可推广4D驾驶场景和动态驾驶视频。具体来说,我们利用视频扩散模型的生成能力来合成一系列视觉参考,并通过一种新的混合高斯表示将其进一步提升到4D。给定一个驾驶轨迹,然后我们通过高斯飞溅渲染3D一致的驾驶视频。生成先验的使用使我们的方法能够从野外驾驶数据中生成高质量的4D场景,而神经渲染则确保从4D场景生成3D一致的视频。对nuScenes和室外驾驶数据的广泛实验表明,DreamDrive可以生成可控和通用的4D驾驶场景,以高保真度和3D一致性合成驾驶视频的新视图,以自监督的方式分解静态和动态元素,并增强自动驾驶的感知和规划任务。

论文链接:https://arxiv.org/abs/2501.00601
介绍
基于自车的轨迹生成驾驶视频是自动驾驶中的一个关键问题。动作条件视频生成允许自动驾驶汽车预测未来的场景,做出相应的响应,并超越专家轨迹进行推广,这对于自动驾驶模型的可扩展训练至关重要。为了应对这一挑战,出现了两个系列的工作:基于重建的方法和基于生成的方法。基于重建的方法从log中模拟3D场景,然后通过神经渲染技术(如NeRF或3D高斯飞溅)生成动作条件视觉观察。这些方法可以合成3D一致和真实的视觉观察结果,但它们严重依赖于注释良好的驾驶日志,其中包括标定的相机参数、目标框和3D点云,这限制了它们在室外驾驶数据中的可扩展性。另一方面,基于生成的方法可以从野外驾驶数据中学习,并通过图像或视频扩散模型合成动作条件下的动态驾驶视频。然而,视频生成存在帧间3D几何一致性差的问题,这可能会破坏自动驾驶合成视觉观察的可靠性。因此,为自动驾驶综合通用和3D一致的视觉观察仍然是一个悬而未决的挑战。
为了应对这一挑战,我们提出了DreamDrive,这是一种用于自动驾驶的4D场景生成方法。我们的核心想法是将视频扩散先验的生成能力与3D高斯飞溅的几何一致性渲染相结合。我们将2D视觉参考从视频扩散模型提升到4D时空场景中,其中自车载体通过高斯飞溅导航和合成新的视图观察。视频扩散先验增强了我们方法的泛化能力,能够从野外驾驶数据中生成4D场景,而高斯飞溅确保了新视图合成过程中的3D一致性。这种方法使DreamDrive能够产生高质量、3D一致的视觉观察,并对各种驾驶场景具有很强的泛化能力。
尽管直观,但从生成的视觉参考中准确建模4D场景仍然非常具有挑战性。与标注好的驾驶数据集不同,生成的视觉参考缺乏关键信息,如相机参数、物体位置和深度数据,这阻碍了4D建模。此外,视频扩散模型中固有的3D不一致性加剧了这个问题,导致传统的高斯表示过拟合训练视图,并在新的视图合成中失败。为了解决这些问题,我们引入了一种自监督混合高斯表示。我们的方法利用与时间无关的高斯模型来模拟静态背景,并利用与时间相关的高斯模型对动态目标进行建模,将它们组合成一个统一的4D场景。首先,我们提出了一种自监督方法,可以仅通过图像监督将场景分解为静态和动态区域。接下来,我们引入时空聚类将3D高斯聚类分为静态和动态高斯聚类,有效地减轻了4D建模中的虚假动态。最后,我们优化了具有时间相关和时间无关表示的高斯聚类,以在图像监督下构建4D场景。通过混合高斯表示,我们的方法能够合成3D一致的新视图驱动视频。我们的方法适用于纯图像监控,消除了对数据注释的需求,使其更具可扩展性和通用性,适用于野外驾驶数据。
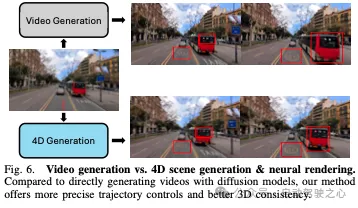
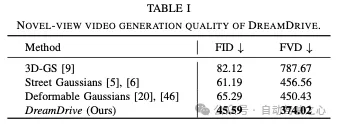
我们在nuScenes数据集和野生驾驶场景中评估了我们的方法,展示了我们4D场景生成的可控性和泛化能力。我们的方法使用混合高斯表示,可以生成高质量、3D一致的新视图驱动视频,视觉质量比以前的方法提高了30%。此外,我们还展示了我们的方法在自动驾驶感知和规划任务中的应用。
相关工作回顾
自动驾驶生成模型。生成模型在基于当前行为合成未来驾驶视频方面显示出巨大的潜力。最近的研究对驾驶数据的稳定视频扩散模型进行了微调,结合了地图、物体、天气和动作等控件来生成不同的驾驶场景。然而,由于这些模型在2D中运行,它们很难捕捉到世界的底层3D几何形状,导致生成的视频中的3D一致性较差。相比之下,我们的方法采用4D场景的神经渲染,确保生成的视频保持3D一致性。
城市景观重建。许多论文专注于从驾驶日志重建3D或4D城市场景,使用多视图图像监控优化基于NeRF或3D-GS的场景。这些方法可以基于驾驶轨迹合成新的视图。然而,大多数方法严重依赖带注释的目标框来跟踪和建模动态目标,限制了它们处理未标记驾驶日志的能力。虽然一些方法使用自监督技术来分离动态目标,但它们仍然依赖于校准良好的相机姿态和3D数据,这使得它们在野外驾驶场景中不太通用。相比之下,我们的方法消除了对姿势或3D信息的需求,直接从视觉参考中实现了精确的4D场景建模。
4D场景生成。许多论文关注3D和4D内容生成,但大多数论文关注目标生成,这不适用于驾驶场景。一些工作引入了4D场景生成的扩散先验。然而,这些方法中的4D场景仅限于以目标为中心的小规模场景,这使得它们很难推广到具有众多动态目标的大规模、无界的驾驶场景。最相关的工作使用扩散先验来生成3D驱动场景,但仅依赖于可变形的3D高斯分布,导致新视图合成中的视觉质量较差。相比之下,我们提出了一种新的自监督方法,用混合高斯表示对4D驾驶场景进行建模,该方法在新的视图驾驶视频合成中表现出更好的泛化能力和视觉质量。
DreamDrive方法详解
DreamDrive是一种用于自动驾驶的4D时空场景生成方法。我们的方法概述如图2所示。DreamDrive遵循2D-3D-4D渐进式生成过程。我们首先利用视频扩散先验来生成2D视觉参考,然后进行高斯初始化将其提升到3D。接下来,我们提出了一种新的自监督场景分解方法,该方法采用基于聚类的分组策略,在4D时空域中分离静态和动态区域。最后,我们引入混合高斯表示来对静态结构和动态目标进行建模,以生成4D场景。

视频扩散先验。视频扩散模型在模拟视觉数据的时间动态方面非常有效,但仅依赖它们进行轨迹条件视频生成可能会导致3D不一致,因为它们是为2D图像生成而设计的,没有考虑底层的3D结构。在我们的方法中,我们使用视频扩散先验来生成初始视觉参考,然后将其提升到4D空间进行场景生成和3D一致的视频渲染。具体来说,我们使用在驱动数据上训练的视频扩散模型来生成一系列参考图像,并从早期层中提取潜在特征,以捕获有价值的视觉动态,用于静态动态分解。该过程正式表示为:

高斯初始化。在没有相机姿态和3D信息的情况下,将生成的图像提升到4D空间是相当具有挑战性的。因此,相机参数和3D结构的稳健估计对于4D场景生成的可靠初始化至关重要。虽然之前的工作使用COLMAP来估计粗略的3D几何,但其稀疏的点云不足以对大规模和无界的驾驶场景进行建模。相反,我们采用端到端的多视图立体网络来生成像素对齐的密集3D几何体,同时恢复相机姿态。具体来说为每张图像生成密集的、与参考像素对齐的3D点云。使用Weiszfeld算法估计相机内参,并通过全局对齐帧间的点云来计算相机外部函数。聚集的点云形成密集的场景级点云,用于初始化3D高斯参数,产生一组高斯Ginit。这些3D高斯分布进一步丰富了像素对齐的潜在特征Zref。整个过程可以表示为:

准确捕捉动态目标的运动。自车监督的场景分解。混合建模的一个关键挑战是在没有额外注释的情况下分离静态和动态区域。为了解决这个问题,我们的关键见解是,图像误差图是区分静态和动态区域的有效指标。具体来说,我们首先通过假设所有初始高斯Ginit都是静态的来优化整个场景。然后,我们将优化的静态高斯分布映射到静态图像Istatic中:



使用高斯聚类进行分组。由于生成的视觉参考中固有的3D不一致性,Iref中经常出现伪动力学,如静态结构中的局部变形。这导致将动态高斯分布错误地分配给静态目标,并对4D场景建模和新的视图合成产生负面影响。为了提高场景分解的鲁棒性,我们引入了一种新的基于聚类的分组策略。我们的关键见解是,目标通常作为一个整体移动,即同一目标中的高斯分布可能具有相同的动态属性。由于我们没有目标注释,我们引入了“时空聚类”来将高斯分布聚类。如果一个簇中的大多数高斯分布是静态的,这意味着整个部分应该是静态的。我们为所有部分分配静态标签,即使有些最初被归类为动态的,反之亦然。该过程可以表示为

混合高斯表示法。场景分解使我们能够用不同的高斯分布表示静态和动态组件。静态高斯模型G静态模型元素,如道路和建筑物,参数G(x,r,s,α,c)随时间保持不变,确保静态结构的准确渲染。

最后,我们将Gstatic和Gdynamic结合到一个4D时空场景中,并通过将它们叠加到图像上来优化它们的参数:

实验结果




结论
本文提出了DreamDrive,这是一种新的自动驾驶4D场景生成方法,将视频扩散模型的生成能力与3D高斯飞溅的几何一致性相结合。使用混合高斯表示,我们的方法在4D驾驶场景中准确地建模静态和动态元素,而无需手动注释。实验表明,DreamDrive可以生成高质量、几何形状一致的驾驶视频,适用于各种驾驶场景,并增强自动驾驶中的感知和规划任务。
























