这篇文章,我们将从 Redis List 的基本原理出发,深入分析其内部实现机制、源码层面的细节,并结合实际示例,全面解析 Redis List 的工作原理。

一、Redis List 概述
Redis 的 List 是一个简单的字符串列表,按照插入顺序排序。它支持在列表的两端插入或删除元素,具有以下特点:
- 有序:元素按照插入顺序排列,可以通过索引访问。
- 双端操作:支持从左端(头部)和右端(尾部)进行插入和删除操作。
- 高效:在两端插入和删除的时间复杂度为 O(1)。
常用的 List 命令包括 LPUSH、RPUSH、LPOP、RPOP、LINDEX、LRANGE 等。
二、Redis List 的内部实现
Redis 的 List 数据结构内部实现主要依赖于两个数据结构:压缩列表(ziplist)和双端链表(quicklist)。根据 List 的大小和元素的长度,Redis 会自动选择合适的数据结构,以优化存储空间和操作效率。
1. 压缩列表
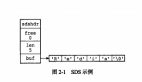
压缩列表 是一种为节省内存而设计的紧凑数据结构。它将多个元素紧密存储在一个连续的内存块中,适用于小型的 List。
- 结构:压缩列表由三个部分组成:ziplist header、entry list 和 ziplist end。
- 性能:适用于含有少量元素且每个元素较短的 List,节省内存但在频繁插入和删除时性能较低。

2. 双端链表
从 Redis 3.2 版本开始,List 的内部实现改为使用 quicklist,它结合了压缩列表和双向链表的优点。
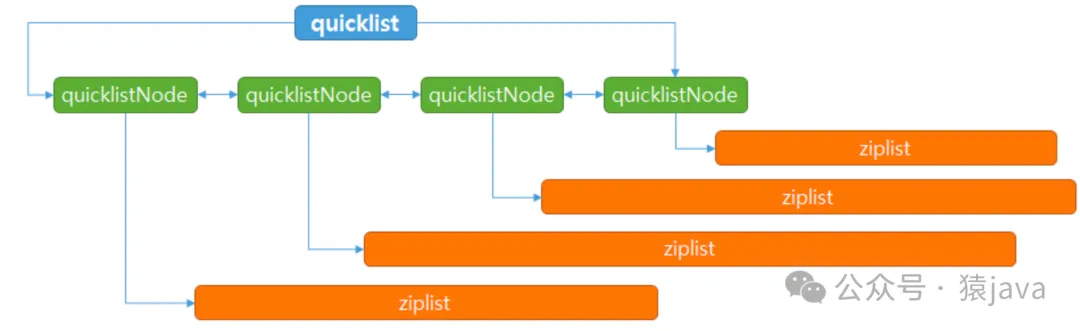
结构:quicklist 是由多个压缩列表(ziplist)组成的双向链表,每个压缩列表称为一个节点(node)。
优势:
- 高效插入与删除:在两端插入和删除元素时,只需要操作链表的头部或尾部节点,时间复杂度为 O(1)。
- 节省空间:每个节点内部仍然使用压缩列表存储元素,节省内存。
灵活性:适用于包含大量元素的 List。
三、源码分析
下面将通过源码分析 Redis List 的实现机制,重点关注 quicklist 相关的代码部分。
1. 数据结构定义
Redis 在 src/quicklist.h 文件中定义了 quicklist 相关的数据结构。
主要的数据结构包括:
- quicklistEntry:表示 quicklist 中的一个条目(entry)。
- quicklistNode:表示 quicklist 中的一个节点,包含一个 ziplist。
- quicklist:整个 quicklist 结构,包含头尾节点、统计信息等。
2. 常用命令的实现
以下将以 LPUSH、RPUSH、LPOP、RPOP、LINDEX、LRANGE 等命令为例,分析它们在源码中的实现。
3. LPUSH 和 RPUSH
LPUSH 和 RPUSH 用于在 List 的左端和右端插入元素。它们在 quicklist 中的实现主要涉及调用 quicklistPush 函数。
核心逻辑:
- 判断插入的位置(头部或尾部)。
- 检查对应位置的节点是否有足够空间插入新元素。
- 如果节点已满,创建一个新的节点并插入。
- 在对应节点的 ziplist 中插入新元素。
- 更新 quicklist 的统计信息。
4. LPOP 和 RPOP
LPOP 和 RPOP 用于从 List 的左端和右端弹出元素。它们主要调用 quicklistPopCustom 函数。
核心逻辑:
- 根据弹出的位置,选择头部或尾部节点。
- 从对应节点的 ziplist 中弹出元素。
- 如果节点为空,删除节点并更新链表指针。
- 更新 quicklist 的统计信息。
5. LINDEX
LINDEX 用于获取 List 中指定索引的元素。它调用 quicklistIndex 函数。
核心逻辑:
- 处理负索引(从尾部开始计数)。
- 遍历 quicklist 的节点,累加每个节点的元素数量。
- 确定目标索引所在的节点。
- 在该节点的 ziplist 中查找目标元素。
6. LRANGE
LRANGE 用于获取 List 中指定范围的元素。它调用 quicklistGetRange 函数。
核心逻辑:
- 创建一个迭代器,指定遍历方向(从头到尾或从尾到头)。
- 遍历 quicklist 的节点和节点内的 ziplist,收集指定范围的元素。
- 返回结果集合。
四、性能优化与选择
Redis 在 List 的内部实现中,通过 quicklist 结构在节省内存和提高操作效率之间取得了平衡。以下是一些性能优化的考虑:
- 节点大小(fill factor):quicklist 中每个节点的 ziplist 有一个填充因子(默认是 4),决定了多少元素被存储在一个节点中。适当的填充因子可以减少节点数量,提高遍历效率。
- 压缩算法:quicklist 支持多种压缩算法,通过配置可以进一步优化内存使用。
- 迭代器机制:通过迭代器遍历 quicklist,提高了操作的灵活性和效率。
在选择使用 List 时,应根据实际需求和数据规模合理设计,避免在极大的 List 上进行频繁的中间位置插入和删除操作,因为这可能导致性能下降。
五、为什么List底层有两种实现
List 数据结构的底层采用了 压缩列表(ziplist) 和 双端链表(quicklist) ,其实是 内存效率 与 操作性能 之间取得最佳平衡。主要原因如下:
1. 压缩列表
内存节省:压缩列表是一种为节省内存而设计的紧凑数据结构。它将多个元素紧密存储在一个连续的内存块中,避免了传统链表中每个节点需要额外指针(如前驱和后继指针)带来的内存开销。对于包含少量元素且每个元素较短的小型列表,压缩列表能够显著减少内存使用量。
缓存友好性:由于压缩列表将所有元素存储在一个连续的内存区域中,这种布局有助于提升缓存命中率。CPU 在访问数据时,能够更高效地预取和缓存数据,从而提高访问速度。
简单数据结构:压缩列表的实现相对简单,适用于不需要频繁插入和删除操作的场景。对于静态或变化不大的小型列表,压缩列表提供了足够的性能和内存效率。
2. 双端链表
高效的两端操作:双端链表允许在列表的头部和尾部进行高效的插入和删除操作,时间复杂度为 O(1)。这对于需要频繁在两端进行操作的应用场景(如队列和栈)尤为重要。
动态扩展能力:与压缩列表相比,双端链表更适合处理动态变化较大的列表。它能够灵活地在任意位置插入和删除元素,而不会像压缩列表那样需要整体移动内存块。
分段存储与性能优化:Quicklist 通过将列表分段存储,每个段使用压缩列表(ziplist)作为节点,实现了分块管理。这种设计兼具了压缩列表的内存效率和双端链表的操作性能。具体来说,每个 quicklist 节点内部是一个压缩列表,多个节点通过双端链表连接起来。这样,在需要进行插入或删除操作时,仅需操作相关的节点,而不影响整个列表结构。
Redis 会根据列表的长度和元素的大小,自动决定使用压缩列表还是双端链表。这种智能选择机制确保了在不同场景下都能获得最佳的性能和内存使用率。例如:
- 小型列表:当列表较小且元素较短时,Redis 会选择压缩列表,最大化内存节省和缓存效率。
- 大型列表:当列表变得较大或元素较长时,Redis 会转而使用 quicklist,以提升操作性能和扩展能力。
六、总结
本文,我们从源码角度分析了 Redis 的 List 数据结构,它是一个高效、灵活的数据结构,适用于多种应用场景,如消息队列、任务管理等。通过内部的 quicklist 结构,Redis 在节省内存和优化操作效率方面做出了平衡。通过学习本文,我们也可以发现 Redis 对性能的追求。