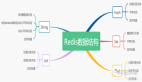
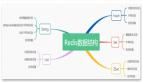
作为一名合格的 Redis 使用者,我们一定要知道 Redis 有哪数据类型,以及每种数据类型的特征,操作方式和应用场景,这样才能帮助我们更好地决策使用哪种数据类型。本文我们将详细地介绍 Redis 9种数据类型:
- 字符串(String)
- 列表(List)
- 集合(Set)
- 有序集合(Sorted Set)
- 哈希(Hash)
- 位图(Bitmap)
- HyperLogLog
- 流(Stream)
- 地理空间索引(Geospatial)

1. 字符串(String)
字符串是 Redis 中最基本、最常用的数据类型。一个字符串值可以包含任何数据,如文本、数字、二进制数据等,最大长度为 512MB。
(1) 常用命令
- SET key value [EX seconds] [PX milliseconds] [NX|XX] :设置指定键的值,可以选择设置过期时间、仅在键不存在时设置(NX)、仅在键存在时设置(XX)。
- GET key:获取指定键的值。
- DEL key:删除指定键。
- INCR key:对存储在指定键的值进行递增,要求该值为整数。
- DECR key:对存储在指定键的值进行递减操作,要求该值为整数。
- APPEND key value:将指定值追加到键的现有值后面。
- MGET key1 key2 ... :批量获取多个键值对。
- MSET key1 value1 key2 value2 ... :批量设置多个键值对。
- GETSET key value:将指定键的值设置为新值,并返回旧值。
(2) 应用场景
- 缓存:由于字符串的存取速度极快,广泛应用于缓存常用数据,如网页内容、用户会话等。
- 计数器:使用 INCR/DECR 命令可以高效地实现访问计数器、点赞数等。
- 分布式锁:通过 SET 命令的 NX 选项,可以实现简单的分布式锁机制。
- 存储小量数据:例如用户的基本信息、配置参数等。
(3) 注意事项
- 内存限制:虽然单个字符串最大可达 512MB,但实际使用中需注意 Redis 的内存容量和内存分配策略。
- 数据类型一致性:在使用 INCR/DECR 等命令时,确保键对应的值是整数类型,否则会引发错误。
2. 列表
列表是 Redis 中的一种简单的有序集合,内部使用双向链表实现。列表中的元素按插入顺序排列,允许重复的元素。Redis提供了一系列操作命令,可以在列表的头部或尾部插入、删除元素,也可以进行范围查询等操作。
(1) 常用命令
- LPUSH key value [value ...] : 将一个或多个值插入到列表的头部。
- RPUSH key value [value ...] :将一个或多个值插入到列表的尾部。
- LPOP key:从列表的头部移除并返回元素。
- RPOP key:从列表的尾部移除并返回元素。
- LRANGE key start stop:返回列表指定范围内的元素。
- LLEN key:获取列表的长度。
- LREM key count value:根据给定的值,从列表中移除元素,count参数定义移除的数量和方向。
- LTRIM key start stop:对列表进行修剪,只保留指定范围内的元素。
- LINDEX key index:获取列表中指定位置的元素。
- LINSERT key BEFORE|AFTER pivot value:在列表中指定元素的前或后插入新的元素。
(2) 应用场景
- 消息队列:由于列表支持先进先出(FIFO)和后进先出(LIFO)的操作,可以用作简单的消息队列。
- 任务调度:将任务放入列表中,通过消费者从列表中取出并处理,实现任务的分发和调度。
- 排行榜:结合其它数据结构,可以实现简单的排行榜功能。
- 实时聊天:存储近期的聊天记录或消息日志。
(3) 注意事项
- 内存消耗:由于列表底层使用双向链表实现,对于大量元素的列表可能会消耗较多内存。
- 性能问题:频繁地在列表的中间进行插入或删除操作,可能会影响性能,建议尽量在两端进行操作。
3. 集合
集合是一种无序的、唯一性的元素集合。Redis 中的 Set 使用哈希表来实现,因此具有快速的成员查找、添加和删除等操作。集合支持丰富的集合运算,如求交集、并集和差集,非常适合处理无序且不重复的数据。
(1) 常用命令
- SADD key member [member ...] :向集合添加一个或多个成员。
- SREM key member [member ...] :从集合中移除一个或多个成员。
- SMEMBERS key:返回集合中的所有成员。
- SISMEMBER key member:判断指定成员是否是集合的成员。
- SCARD key:获取集合的成员数量。
- SRANDMEMBER key [count] :随机返回集合中的一个或多个成员。
- SINTER key [key ...] :计算多个集合的交集
- SUNION key [key ...] :计算多个集合的并集
- SDIFF key [key ...] :分别计算多个集合的差集。
- SMOVE source destination member:将成员从一个集合移动到另一个集合。
(2) 应用场景
- 标签系统:为对象打上多个标签,并通过集合运算实现标签的交叉查询。
- 社交网络:保存用户的关注列表、粉丝列表等,利用集合的唯一性特性防止重复。
- 推荐系统:通过计算用户行为集合的交集或并集,生成个性化推荐。
- 权限管理:存储用户的权限集合,通过集合运算实现权限的继承和组合。
(3) 注意事项
- 无序性:集合不保证元素的顺序,如果需要有序的数据,请考虑使用其他数据类型如有序集合。
- 唯一性:集合中的元素是唯一的,如果需要存储重复的数据,需要使用其他数据结构或在元素中添加唯一标识符。
- 内存优化:对于大量元素的集合,可以通过RDB或AOF持久化策略进行优化,减少内存消耗。
4. 有序集合
有序集合是在集合的基础上增加了“权重”或者“分数”(score)概念的集合类型。每个元素在有序集合中都关联一个分数,Redis通过分数对集合中的元素进行排序。内部实现采用跳表(Skip List)数据结构,允许高效的范围查询和排名操作。
(1) 常用命令
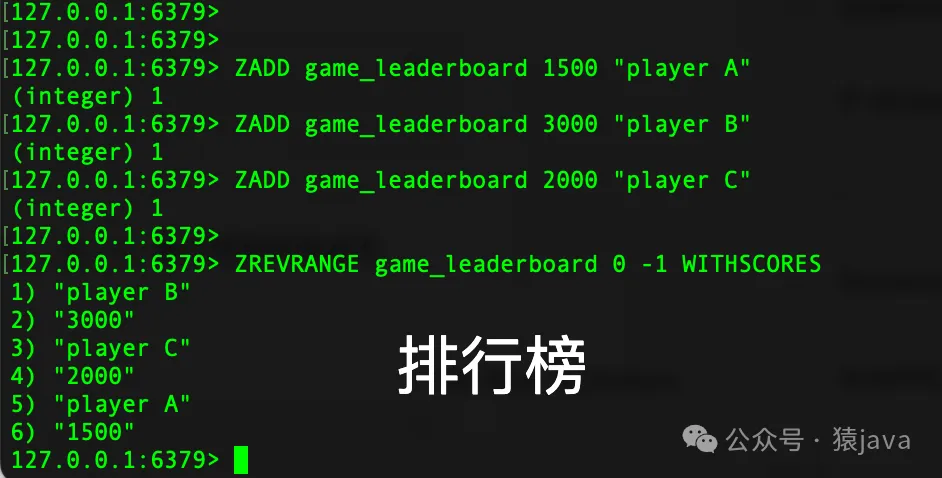
- ZADD key [NX|XX] [CH] [INCR] score member [score member ...] :向有序集合添加一个或多个成员,或者更新成员的分数。
- ZREM key member [member ...] :移除一个或多个成员。
- ZINCRBY key increment member:为有序集合中的成员的分数加上指定的增量值。
- ZRANGE key start stop [WITHSCORES] :返回有序集合中指定范围内的成员,按分数正序排列。
- ZREVRANGE key start stop [WITHSCORES] :返回有序集合中指定范围内的成员,按分数逆序排列。
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] :返回有序集合中分数在指定范围内的成员。
- ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] :返回有序集合中分数在指定范围内的成员。
- ZSCORE key member:返回成员的分数。
- ZCARD key:获取有序集合的成员数量。
- ZCOUNT key min max:统计有序集合中分数在指定范围内的成员数量。
- ZRANK key member:返回成员在有序集合中的排名,从小到大
- ZREVRANK key member:返回成员在有序集合中的排名,从大到小。
- ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] :对多个有序集合进行并集运算,并将结果存储到目标键。
- ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] :对多个有序集合进行交集运算,并将结果存储到目标键。
(2) 应用场景
- 排行榜:有序集合非常适合实现游戏排行榜、销售排行等功能,通过分数来定义排名。
- 延时队列:利用分数表示任务的执行时间,实现延时任务的调度。
- 推荐系统:通过分数表示推荐的相关性或优先级,动态调整推荐结果。
- 地理位置排名:结合地理空间索引,按照距离或其他指标对地理位置进行排序。
- 计时任务:存储定时任务的执行时间,并根据当前时间触发相应的任务。
(3) 注意事项
- 分数的唯一性:有序集合中的成员可以有相同的分数,但成员本身必须唯一。
- 分数的精度:分数是双精度浮点数,可能存在精度问题,需在应用层面做好相应处理。
- 性能优化:对于大量的有序集合操作,合理使用 pipeline 或批量操作命令,提升性能。
5. 哈希
哈希是 Redis 中用于存储键值对映射的数据类型。类似于编程语言中的字典、Map 或对象,哈希适合存储对象的属性信息。内部实现使用哈希表或者压缩列表(ziplist),当字段数量较少时,使用压缩列表可以节省内存。
(1) 常用命令
- HSET key field value [field value ...] : 向哈希中设置一个字段及其值
- HMSET key field value [field value ...] :向哈希中设置多个字段及其值
- HGET key field:获取哈希中指定字段的值
- HMGET key field [field ...] :获取哈希中多个字段的值
- HDEL key field [field ...] :删除哈希中的一个或多个字段
- HEXISTS key field:判断哈希中是否存在指定字段
- HLEN key:获取哈希中字段的数量
- HGETALL key:获取哈希中所有的字段和值
- HINCRBY key field increment:为哈希中的整数字段值加上指定的增量
- HINCRBYFLOAT key field increment:为哈希中的浮点数字段值加上指定的增量
- HKEYS key:分别获取哈希中的所有字段名
- HVALS key:分别获取哈希中的所有字段值
- HSCAN key cursor [MATCH pattern] [COUNT count]:遍历哈希中的字段和值
(2) 应用场景
- 对象存储:将对象的属性存储在哈希中,方便获取和修改单个属性。
- 会话管理:存储用户会话信息,如登录状态、权限等。
- 配置管理:存储应用的配置信息,通过哈希的字段结构组织数据。
- 统计数据:记录页面访问次数、用户行为等统计信息。
(3) 注意事项
- 字段数量:哈希在字段数量较少时性能和内存消耗较优,字段过多时可能不如使用字符串或有序集合高效。
- 数据一致性:在分布式环境中,更新哈希的某个字段时需注意数据的一致性和并发控制。
- 持久化策略:针对频繁更新的哈希数据,需合理配置Redis的持久化策略,避免数据丢失。
6. 位图
位图并不是 Redis 官方的数据类型,而是基于字符串数据类型的二进制位操作,通过对字符串进行位级别的操作,实现高效的位图功能。位图适合用于存在性判断、布隆过滤器、用户签到等场景。
(1) 常用命令
- SETBIT key offset value:将指定偏移量的位设置为0或1。
- GETBIT key offset:获取指定偏移量的位的值。
- BITCOUNT key [start end] :统计位图中值为1的位数量,可以指定范围。
- BITOP operation destkey key [key ...] :对多个位图进行位操作,如AND、OR、XOR、NOT,并将结果存储到目标键。
- BITPOS key bit [start] [end] :查找位图中第一个或最后一个指定值的位的位置。
(2) 应用场景
- 用户签到:通过位图表示用户的每日签到状态,高效存储和查询。
- 在线状态:记录用户的在线状态,通过位图快速判断用户是否在线。
- 侵入检测:利用位图进行数据的快速存在性检测,如防止重复提交。
- 布隆过滤器:与哈希算法结合,实现高效的布隆过滤器,用于防止缓存穿透等问题。
(3) 注意事项
- 偏移量管理:需要合理管理位图的偏移量,确保数据的一致性和正确性。
- 内存优化:位图基于字符串实现,设置较高的偏移量会导致内存浪费,需根据实际需求设计位图的大小。
- 原子性操作:Redis的位图操作是原子性的,但复杂的位操作需要在应用层进行逻辑控制。
7. HyperLogLog
HyperLogLog是一种用于基数估算的数据结构,Redis通过内置支持 HyperLogLog,实现了高效的基数统计功能。HyperLogLog在内存消耗极低的情况下,可以近似计算大规模数据的基数(如唯一用户数),但不支持删除操作。
(1) 常用命令
- PFADD key element [element ...]:将元素添加到HyperLogLog中。
- PFCOUNT key [key ...]:返回一个或多个HyperLogLog的数据基数估算。
- PFMERGE destkey sourcekey [sourcekey ...]:合并多个HyperLogLog,并将结果存储到目标键。
(2) 应用场景
- UV统计:统计网站或应用的独立访客(Unique Visitors)。
- 数据去重:快速估算大规模数据的去重基数。
- 实时分析:在实时数据流中进行基数统计,如消息队列中的唯一消费者数。
- 推荐系统:计算用户的独特行为,如浏览的独特商品数量。
(3) 注意事项
- 精度问题:HyperLogLog提供的是基数的近似值,误差在±0.81%左右,适用于大规模数据的估算场景。
- 不可删除:一旦元素被添加到HyperLogLog中,无法单独删除元素,适用于无需精确删除的场景。
- 多键合并:PFMERGE操作会合并多个HyperLogLog的数据,适用于分布式统计的合并需求。
8. 流
流是 Redis 5.0 引入的一种新的数据类型,用于处理消息队列和事件流。流支持消息的生产和消费,具有持久化、可靠性和可扩展性等特性。内部通过双端链表和索引实现,支持消费者组、消息确认等功能。
(1) 常用命令
- XADD key [MAXLEN ~|= maxlen] * field value [field value ...]:向流中添加一条消息,可以限制流的长度。
- XLEN key:获取流的长度,即消息数量。
- XRANGE key start end [COUNT count]:按时间范围获取流中的消息,支持正向遍历。
- XREVRANGE key end start [COUNT count]:按时间范围获取流中的消息,支持反向遍历。
- XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]:阻塞读取流中的新消息。
- XGROUP CREATE key groupname id [MKSTREAM]:消费者组管理命令。
- XGROUP SETID key groupname id:消费者组管理命令。
- XGROUP DELGROUP key groupname:消费者组管理命令。
- XREADGROUP groupname consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]:消费者组内部的阻塞读取命令。
- XACK key groupname id [id ...]:确认消息已被消费。
- XPENDING key groupname [start end count] [consumer]:查看消费者组的待处理消息。
- XDEL key id [id ...]:删除指定消息或修剪流长度。
- XTRIM key MAXLEN ~|= maxlen:删除指定消息或修剪流长度。
(2) 应用场景
- 消息队列:实现可靠的消息队列,支持消息的持久化和消费者组的负载均衡。
- 实时数据流处理:处理实时生成的数据流,如日志收集、事件追踪等。
- 通知系统:实现实时通知推送,如即时通讯、系统告警等。
- 任务调度:将任务以消息的形式放入流中,由消费者组分发和处理任务。
(3) 注意事项
- 消费确认:使用消费者组时,需要正确进行消息的确认(XACK),以避免消息丢失或重复消费。
- 流长度控制:通过XADD命令的MAXLEN选项或XTRIM命令定期修剪流的长度,防止数据无限增长。
- 消费者组管理:合理设计消费者组和消费者数量,避免消费者过多导致的性能问题。
- 持久化策略:由于流支持持久化,需要根据业务需求合理配置RDB或AOF持久化策略。
9. 地理空间索引
Redis 的地理空间索引基于有序集合实现,通过经纬度数据存储和地理空间计算,支持距离查询和范围查询。常用于实现基于地理位置的应用,如附近的人/商家、地图导航等。
(1) 常用命令
- GEOADD key longitude latitude member [longitude latitude member ...]:向地理空间索引中添加成员及其经纬度信息。
- GEODIST key member1 member2 [unit]:计算两个成员之间的距离,可以指定单位(米、千米、英里、英尺)。
- GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ORDER ASC|DESC] [STORE key] [STOREDIST key]:根据给定的经纬度坐标和半径,查找在指定范围内的成员,可以选择返回坐标、距离、哈希值等附加信息。
- GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ORDER ASC|DESC] [STORE key] [STOREDIST key]:根据给定的经纬度坐标和半径,查找在指定范围内的成员,可以选择返回坐标、距离、哈希值等附加信息。
- GEOHASH key member [member ...]:返回一个或多个成员的Geohash编码。
- GEOPOS key member [member ...]:返回一个或多个成员的经纬度坐标。
- GEOSEARCH key FROMMEMBER member BYRADIUS radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:基于成员或指定经纬度进行地理空间搜索。
- GEOSEARCH key FROMLONLAT longitude latitude BYRADIUS radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:基于成员或指定经纬度进行地理空间搜索。
(2) 应用场景
- 位置服务:实现基于位置的服务,如查找附近的餐厅、加油站、医院等。
- 物流配送:优化配送路线,根据地理位置进行调度和分配。
- 社交网络:查找附近的好友、动态或活动。
- 游戏开发:实现基于位置的游戏元素,如寻宝、位置打卡等。
(3) 注意事项
- 精度选择:通过 GEORADIUS 命令的 unit 参数选择合适的距离单位,确保计算的精度和性能。
- 数据分布:合理分布地理空间坐标,避免数据过于集中导致性能瓶颈。
- 索引维护:在添加或删除地理空间数据时,确保有序集合的索引被正确维护,避免数据不一致。
- 距离计算:GEODIST命令基于地球的球面模型进行距离计算,不适用于需要高度精确距离的场景。
总结
本文我们分析了 Redis中常见的 9种数据类型,从最基本的字符串、列表、集合到复杂的有序集合、哈希,再到位图、HyperLogLog、流和地理空间索引,每种数据类型都有其独特的特性和应用场景。熟练掌握这些数据类型的使用及其底层实现,能够帮助我们设计高效、可扩展的系统架构,充分发挥Redis的性能优势。