引言
本文介绍了YOLO(You Only Look Once),一种基于卷积神经网络(CNN)的物体检测模型。与依赖基于分类方法的传统物体检测模型不同,YOLO通过基于回归的方法直接推断边界框来预测物体位置。这种端到端的CNN模型以其卓越的处理速度和高预测精度脱颖而出,在这两方面都优于许多现有的物体检测架构。

图1. YOLO检测图
背景
近年来,物体检测的进展主要依赖于基于CNN的架构,包括R-CNN和DPM等著名模型。然而,大多数传统模型涉及多阶段流程,导致推理时间较长且复杂性增加。此外,它们复杂的结构使得优化和参数调整变得困难。相比之下,YOLO引入了一种基于回归的端到端CNN架构,提供了几个关键优势:
- 实时推理:YOLO实现了每秒45帧的惊人处理速度,当使用Titan X GPU时,其变体甚至可以达到每秒150帧。这使得模型能够以极低的25毫秒延迟实时处理视频流。
- 全局推理:在训练阶段,YOLO一次性处理整个图像,捕捉物体外观和上下文信息。这种整体方法有助于减少背景错误,这是滑动窗口或基于区域提议方法的常见问题。
- 学习可泛化的表示:作者通过在自然图像上训练的模型对艺术作品图像进行测试,展示了YOLO的强大泛化能力。这一表现显著优于传统物体检测模型。
方法
统一检测

图2. YOLO流程:该模型通过以下过程推断物体的边界框
如图2所示,YOLO模型通过边界框回归对给定图像进行分割并检测物体。所有这些过程都在单个CNN模型中完成。
首先,模型将输入图像划分为S × S的网格。每个网格单元预测B个边界框并返回相应的置信度分数。置信度分数是模型准确预测目标物体的信心度量。作者将置信度分数定义为以下公式。

图3. 计算不同边界框IOU的示例:绿色框是真实值,红色框是预测值
注意,IOU表示“交并比”,如图3所示。它通过以下方程获得:
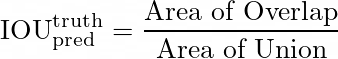
重叠区域表示预测值和真实值重叠的区域,而并集区域是预测值和真实值区域的并集。
预测的边界框有5个值。这些值是x、y、w、h和置信度。x和y值表示框的中心坐标相对于网格单元边界的位置。w和h值表示预测边界框的长度和高度相对于整个图像的比例。最后,置信度表示置信度分数。
在图2中,底部的彩色框表示每个网格单元的类别预测。这些预测表示为条件概率P(Class∣Object),表示在边界框中存在物体的情况下,特定类别出现的可能性。
每个网格单元独立于边界框数量预测这些概率值。然后,通过将条件概率P(Class∣Object)与置信度分数P(Object) × IOU相乘,计算出类别特定的置信度分数。这个最终分数既包含了特定类别出现在边界框中的概率,也包含了预测框与目标物体匹配的准确性。
网络设计

图4. YOLO模型结构
如前文所述,作者将YOLO设计为CNN结构。该网络是一个简单的结构,通过CNN层提取图像特征,并通过最后的全连接层(FC层)输出预测边界框值的概率。
该模型是通过模拟GoogleNet构建的。网络有24个CNN层和两个FC层。所提出的模型与GoogLeNet的区别在于inception模块。YOLO模型使用1 × 1的降维层,后接3 × 3的卷积层,而不是inception模块。
作者还介绍了Fast YOLO,这是YOLO的更快版本。该模型使用9个卷积层,滤波器数量比YOLO少。除了模型大小外,YOLO和Fast YOLO的所有超参数都相同。
模型中的最后一个张量的形状为S × S × (5B + C),其中C是类别概率。由于作者设置B = 2,C = 20,S = 7,最终张量的形状为7 × 7 × 30。
模型训练
(1) 预训练
设计模型的前20个CNN层使用ImageNet数据集进行预训练。该训练一直进行到模型的分类性能达到88%的top-5准确率。然后,这个预训练模型用于物体检测任务,并添加了4个CNN层和2个FC层。这里,添加的层是随机初始化的。为了提高物体检测性能,作者将输入图像分辨率从224 × 224增加到448 × 448。
(2) 模型输出
YOLO的最后一层返回类别概率和边界框坐标。注意,边界框的坐标、宽度和高度通过归一化限制在0到1之间。
(3) 损失函数
损失函数考虑了所有预测边界框的估计类别、坐标、高度和宽度。损失函数表达式如下。
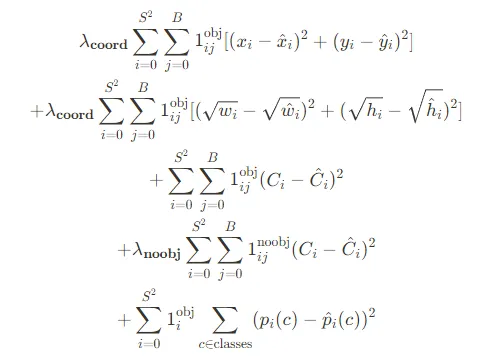
在这种情况下,1ᵢ表示单元格i中是否存在物体,而1ᵢⱼ表示单元格i中的第j个边界框预测器负责进行预测。
作者优先考虑坐标预测的损失,而不是没有物体的单元格的损失。为此,引入了两个加权因子:一个用于坐标预测(λcoord),另一个用于非物体预测(λnoobj)。在本研究中,λcoord设置为5,λnoobj设置为0.5。
推理
YOLO模型预测多个边界框,本文中具体为98个框。作者提到,所提出的模型可以快速推理,因为它只需要一次网络评估。
网格设计强制了边界框预测的空间多样性。大多数目标物体落入一个单元格,模型只为每个物体预测一个框。此外,相对较大的目标可以通过多个单元格很好地定位。作者使用非极大值抑制来处理这些问题。这种抑制方法使mAP提高了23%。
与其他检测系统的比较
本文简要介绍了所提出的模型与其他现有方法的区别。
(1) 可变形部件模型
虽然可变形部件模型(DPM)通过分离的步骤检测目标物体,但所提出的YOLO通过CNN模块整合了这些单独的过程。
(2) R-CNN
现有的R-CNN通过评估候选边界框的分数来预测目标物体的位置。YOLO的不同之处在于它使用较少的候选边界框,并且提取物体特征的过程完全通过CNN完成。
(3) 其他快速检测器
这项工作提到了基于DPM的其他方法,如Fast R-CNN和Faster R-CNN。所提到的研究侧重于提高帧处理速度,而作者则更注重在保持实时处理速度(每秒30帧)的同时提高预测准确性。
(4) Deep MultiBox
所提到的方法SSD(Deep Multibox)无法执行通用物体检测,需要进一步的图像块分类,而所提出的YOLO是端到端的检测框架。
(5) OverFeat
Overfeat和YOLO在目的上相似。然而,所提到的模型侧重于定位,而YOLO则专注于优化检测性能。
(6) MultiGrasp
MultiGrasp和YOLO的检测过程相似,但所提到的方法是用于抓取检测的模型,而所提出的网络则设计用于更具挑战性的任务——物体检测。
实验
数据集

图5. VOC 2007数据中的物体检测示例
使用了物体检测领域的公共数据集PASCAL VOC 2007。该数据集包含许多图像,其中有各种类型的物体,如汽车、狗、人、自行车等。作者还包含了VOC 2012数据集进行额外实验。图5展示了使用VOC数据集的示例结果。
模型设置
(1) 超参数
- 训练轮数:135
- 批量大小:64
- 优化器:随机梯度下降(SGD)
- 动量:0.9
- 衰减:0.0005
- 学习率:0.001(第一轮),0.01(第2 ~ 75轮),0.001(第76 ~ 105轮),0.0001(最后30轮)
- Dropout:0.5
(2) 数据增强
在这项工作中,应用了数据增强以防止训练模型的过拟合。作者随机调整原始图像的大小或平移,最多调整其原始大小的20%。此外,图像的颜色曝光和饱和度在HSV颜色空间中随机调整,最多调整1.5倍。
(3) 评估指标
作者采用了两个测量指标,mAP(平均精度)和FPS(每秒帧数)。前者代表模型的检测准确性,后者是实时处理能力的度量。
结果

图6. PASCAL VOC 2007数据集上的比较结果。一些模型同时使用VOC 2007和VOC 2012进行训练
作者将YOLO与其他现有的物体检测方法(包括Faster R-CNN)进行了比较。这里,FPS达到30或更高的系统被归类为实时检测器。mAP和FPS的比较结果如图6所示。其他现有方法的准确性略高于YOLO,但处理速度非常慢。另一方面,所提出的模型在实时能力和准确性之间取得了适当的平衡。

图7. Fast R-CNN和YOLO检测结果的错误分析图
与当时最先进的Fast R-CNN模型进行了深入比较。作者根据交并比(IOU)指标描述了检测结果如下。
- 正确:类别正确且IOU > 0.5。
- 定位:类别正确且0.1 < IOU < 0.5。
- 相似:类别相似,IOU > 0.1。
- 其他:类别错误,IOU > 0.1。
- 背景:任何物体的IOU < 0.1
两个模型的检测结果图如图7所示。Fast R-CNN在准确性上略优于YOLO,但它也占据了相当大比例的完全错误情况(背景)。而YOLO模型正确推断物体类别的比率高于对比模型。
与Fast R-CNN的结合

图8. 结合模型的mAP结果。测试使用VOC 2007数据集进行
作者设计了以Fast R-CNN为骨干网络的YOLO模型,并观察了检测性能的变化。与原始骨干网络的结果比较如图8所示。图8中不同Fast R-CNN变体的括号中的文本指的是模型训练方法。将Fast R-CNN插入YOLO架构中,结果优于不同的学习方法。此外,YOLO也受到骨干网络的影响。

图9. VOC 2012数据集上的mAP结果。这里,一些是实时模型,一些不是
作者还通过使用VOC 2012数据集进行测试,参考了比较结果。一些实时技术和不考虑处理速度的简单检测方法。实验结果列在图9中。图9中的阴影行表示所提出的方法YOLO。作者提到,所提出的网络在相对较小的准确性牺牲下确保了实时性。
泛化能力
本文还介绍了使用其他数据集的额外实验。作者使用VOC 2007数据集训练YOLO模型,并在未见过的数据集上进行测试。有趣的是,绘画数据集(Picasso、People-art)也包括在内。

图10. 使用Picasso数据集测试的几个模型的精确率-召回率曲线

图11. 几个数据集上的定量结果
作者通过跨数据集实验验证了模型的泛化性能。图10和图11分别展示了精确率-召回率曲线、AP和F1的结果。与其他现有的物体检测模型相比,YOLO表现出更好的泛化性能。特别是在训练数据(VOC 2007)和未见数据集上的实验结果差异相对较小,这意味着YOLO模型对图像外观具有鲁棒性。

图12. 使用各种图像估计的边界框
图12展示了YOLO模型的定性结果。有一些错误的预测,如左下角第二个(一个飞行的人被估计为飞机)。然而,如其他结果所示,所提出的YOLO模型即使在单一类型的训练数据集下,也能准确识别各种类型图像中的物体。
结论
本文介绍了YOLO(You Only Look Once),这是一种非常快速且易于实现的物体检测模型。与基于分类模型的传统物体检测方法不同,YOLO采用基于回归的设计,实现了更直接和高效的物体检测。通过比较分析和泛化实验,作者展示了YOLO在实现高精度和卓越处理速度的同时,也证明了其对各种物体检测任务的适应性。
回顾
YOLO(You Only Look Once)代表了物体检测技术发展的一个重要里程碑,为后续众多版本和改进奠定了基础。其创新的损失函数和简化的检测方法相比早期方法带来了显著的性能提升。然而,正如作者在论文中承认的那样,YOLO也存在一些局限性。这些局限性包括处理同一物体不同长宽比的挑战,以及准确检测非常小物体的困难。尽管存在这些限制,YOLO对实时物体检测的贡献及其对后续模型的影响是不可否认的。
参考文献
(1) GoogleNet:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf
(2) ImageNet:https://www.image-net.org/
(3) Deformable Parts Models(DPM):https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Girshick_Deformable_Part_Models_2015_CVPR_paper.pdf
(4) Fast R-CNN:https://openaccess.thecvf.com/content_iccv_2015/papers/Girshick_Fast_R-CNN_ICCV_2015_paper.pdf
(5) You Only Look Once: Unified, Real-Time Object Detection:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf