Teachable Machine 是由 Google 开发的一款基于网页的工具,允许任何人在不需要深入了解编程或机器学习的情况下创建机器学习模型。它的设计易于使用且用户友好,适合初学者、教育工作者,甚至是想要探索人工智能概念的孩子们。

Teachable Machine 支持的模型
Teachable Machine 支持以下机器学习模型:
- 图像分类 — 识别图像中的物体
- 音频分类 — 识别声音、语音或其他音频输入
- 姿态分类 — 识别人体姿态或动作
要训练模型,您需要为 Teachable Machine 提供自己的数据集,例如图像或录音。基于这些数据,Teachable Machine 会自动训练模型。
模型训练完成后,您可以直接在 Teachable Machine 的网页界面中进行测试。此外,您还可以选择下载训练好的模型,并将其集成到自己的应用程序中以供编程使用。训练好的模型可以用于各种类型的应用程序,包括:
- 网页应用程序(通过 TensorFlow.js)
- 基于 Python 的桌面应用程序(通过 TensorFlow)
- 移动应用程序(通过 TensorFlow Lite)
开始使用
要开始使用 Teachable Machine,请访问 https://teachablemachine.withgoogle.com/。您将看到以下界面:
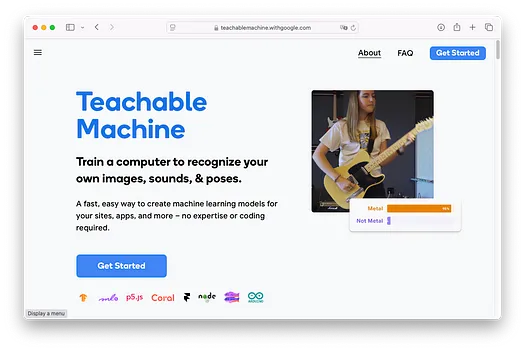
点击Get Started按钮,您将看到以下屏幕:
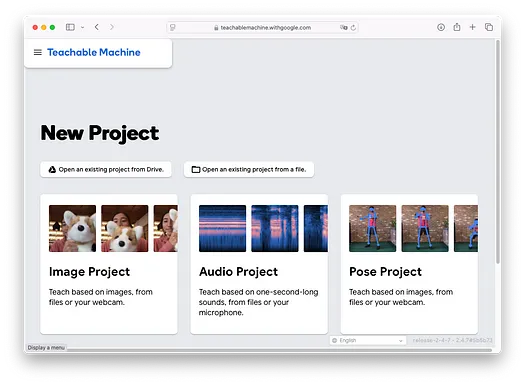
在本文中,我将使用 Teachable Machine 训练一个模型来识别水果。具体来说,我的模型将帮助我们区分香蕉和草莓。选择Image Project,您将看到以下界面:
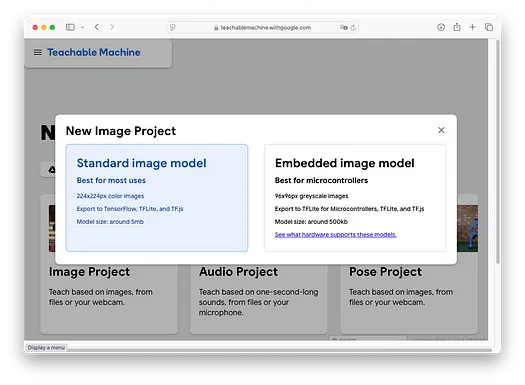
选择Standard image model项目,您将看到以下屏幕:
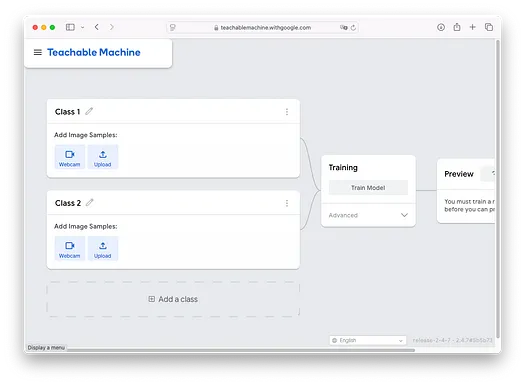
定义类别
在任何分类任务中,第一步是定义您想要识别的类别。在本例中,我们将专注于区分香蕉和草莓的图像,创建两个类别:**Banana** 和 **Strawberry**。要设置此内容,只需双击默认标签“Class 1”和“Class 2”,并将它们重命名为您的类别:

请注意,您可以通过点击屏幕底部的 **Add a class** 按钮来创建更多类别:

为每个类别上传图像
定义类别后,下一步是为每个类别添加图像。您可以直接使用网络摄像头拍摄图像,或者为了方便起见,上传现有的图像。
点击Upload按钮:
您可以将几张图像拖放到下面的框中:
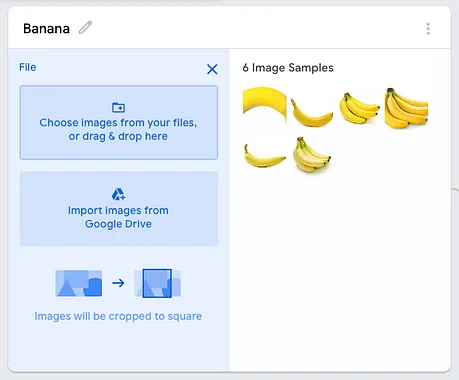
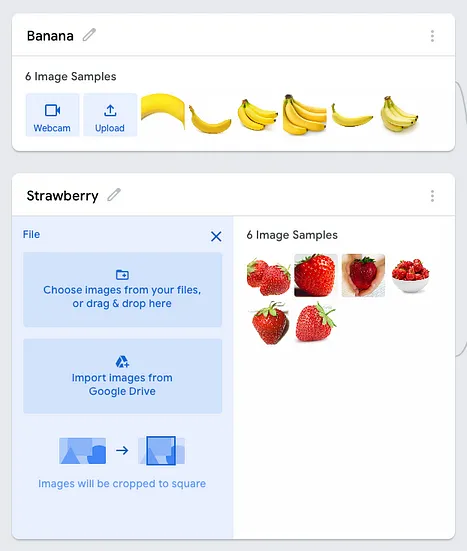
在我的示例中,我已经将一系列图像拖放到两个类别中:
训练模型
为每个类别添加图像后,就可以开始训练模型了。点击 **Train Model** 按钮:
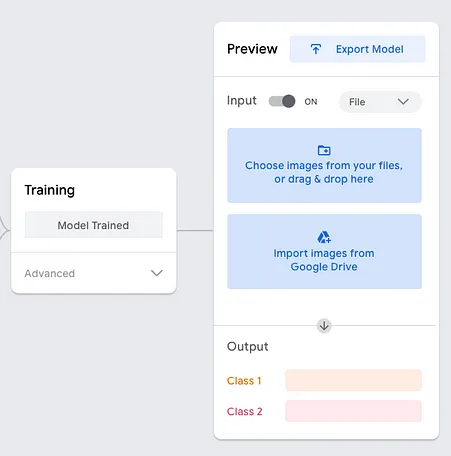
模型训练完成后,您应该能够看到类似以下内容:
测试模型
打开Input选项,您应该能够通过直接将图像拖放到下面的框中来测试模型:
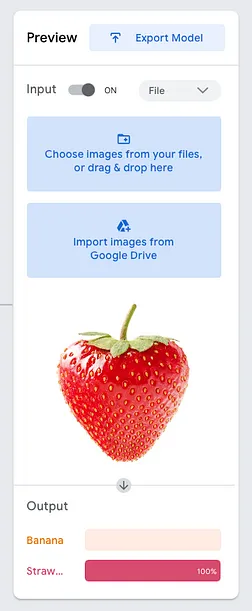
在上面的示例中,模型以 100% 的置信度检测到图像是草莓。您还可以使用网络摄像头测试模型。例如,在下图中,我使用手机显示了一串香蕉的图片,模型准确地预测为“Banana”:

导出模型
虽然在网页上直接测试模型很方便,但将其集成到自己的应用程序中则更具吸引力。幸运的是,您可以将训练好的模型导出为独立文件,从而在应用程序中以编程方式使用它。要导出模型,请点击Export Model按钮:

模型可以导出为:
- TensorFlow.js(用于网页应用程序)
- TensorFlow(用于基于 Python 的应用程序)
- TensorFlow Lite(用于移动应用程序)
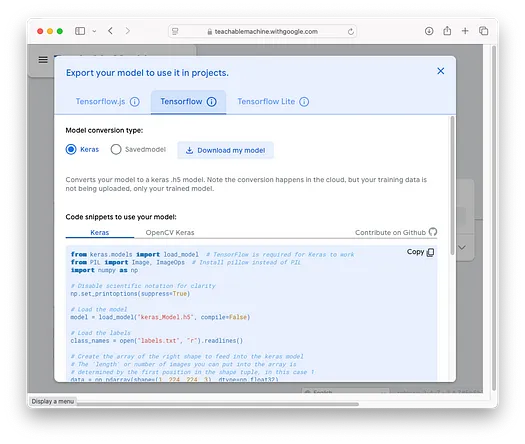
选择您想要的模型类型,然后点击 **Download my model** 按钮。在本例中,我将下载 TensorFlow 模型。一个名为 `converted_keras.zip` 的文件将被下载。解压缩该文件,您将看到其中包含两个文件:
- keras_model.h5 — 训练好的模型
- labels.txt — 包含类别列表的文件,例如 Banana 和 Strawberry
Teachable Machine 还提供了如何使用训练好的模型进行编程的示例代码。我们将在下一节中介绍这一点。
使用 Python 使用导出的模型
训练好的模型导出并下载后,现在是时候看看如何在 Python 应用程序中使用它了。在尝试之前,请注意以下几点:
- Teachable Machine 生成的示例代码基于较旧版本的 TensorFlow。因此,您需要确保您的机器使用较旧版本的 TensorFlow。
- 由于使用了较旧版本的 TensorFlow,您还需要将 Python 的版本限制为较早的版本。
尝试示例代码的最佳方法是创建一个虚拟环境。您可以通过运行以下命令来创建名为 `tf_old` 的虚拟环境,使用 Python 3.11 并安装必要的 Anaconda 包:
虚拟环境创建完成后,激活它并启动 Jupyter Notebook:
Jupyter Notebook 启动后,您可以创建一个新的笔记本并开始编写代码。确保 `keras_model.h5` 和 `labels.txt` 文件与您的 Jupyter Notebook 位于同一文件夹中。
首先,如前所述,您需要安装较旧版本的 TensorFlow。在我的测试中,TensorFlow 2.13.0 版本与 Python 3.11 中的示例代码兼容。为此,请使用以下命令安装 TensorFlow 和 Pillow 包:
现在,您可以使用以下代码片段加载训练好的模型并加载名为 `fruit1.jpg` 的测试图像:
`fruit1.jpg` 的输出如下:

如果您遇到以下错误:
这很可能意味着您正在使用较新版本的 TensorFlow,该版本与示例代码不兼容。
构建网页前端
与其每次测试新图像时都修改代码,不如通过使用 Gradio 包装代码来简化流程。Gradio 提供了一个直观的基于网页的界面,允许用户上传图像并查看预测结果,而无需修改底层代码。首先,安装 Gradio 包:
以下代码片段使用 Gradio 创建了一个网页前端,允许用户上传图像并实时从训练好的模型中获取预测结果。该界面使用户能够轻松地与模型交互,而无需手动修改或运行代码:
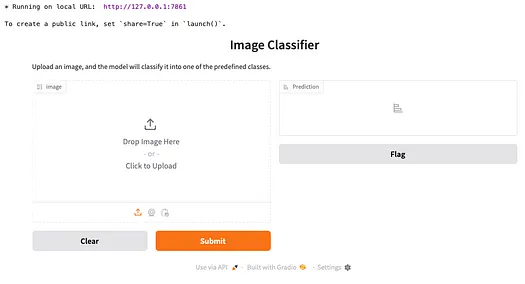
运行代码后,您将看到以下界面:
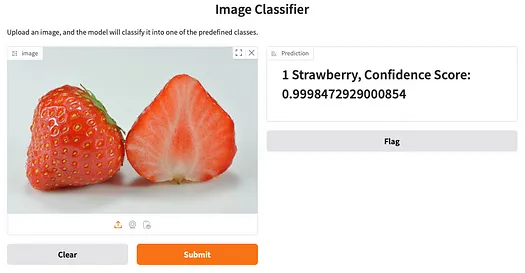
将草莓图像拖放到左侧的框中,然后点击 **Submit** 按钮。您将在右侧看到结果:
总结
在本文中,我探索了 Teachable Machine,这是 Google 提供的一款基于网页的工具,使用户无需编程技能即可创建机器学习模型。我介绍了该工具,并解释了如何为区分香蕉和草莓图像等任务定义类别。我演示了如何为这些类别添加图像、测试模型并将其导出以集成到自定义应用程序中。此外,我还展示了如何使用 Gradio 创建一个简单的网页界面,允许使用导出的模型进行实时预测。