DINO模型输出的狗冲刺
无标签自蒸馏(DINO)
《从几个“补丁”中重建完整图像 | 构建可扩展学习器的掩模自编码器》这边文章讲了如何构建可扩展学习器,这是我对视觉变换器系列的继续,其中我解释了最重要的架构及其从零开始的实现。
自监督学习
自监督学习(SSL)是一种机器学习类型,模型通过无需手动标记的示例来学习理解数据。相反,它从数据本身生成其监督信号。当标记数据有限且获取成本高昂时,这种方法非常有益。在SSL中,学习过程涉及创建任务,其中输入数据可以用来预测数据本身的某些部分。常见的技术包括:
- 对比学习:模型通过区分相似和不相似的数据对来学习。
- 预测任务:模型从其他部分预测输入数据的一部分,例如预测句子中的下一个词或从其周围环境中预测词的上下文。
DINO模型
DINO(无标签蒸馏)模型是一种应用于视觉变换器(ViTs)的尖端自监督学习方法。它代表了计算机视觉领域的一个重大进步,使模型能够在不需要任何标记数据的情况下学习有效的图像表示。由Facebook AI Research(FAIR)的研究人员开发,DINO利用学生-教师框架和创新的训练技术,在各种视觉任务上取得了卓越的性能。
学生-教师网络
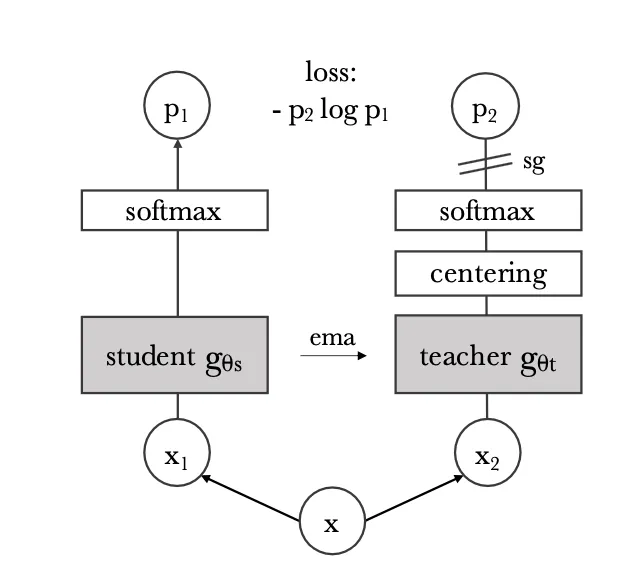
在DINO模型中,学生-教师网络是实现无需标记数据的自监督学习的核心机制。这个框架涉及两个网络:学生网络和教师网络。两个网络都是视觉变换器,它们被设计用来通过将图像处理为序列块来处理图像,类似于变换器处理文本序列的方式。
学生网络的任务是从输入图像中学习生成有意义的表示。另一方面,教师网络提供目标表示,学生网络旨在匹配这些表示。教师网络不是一个静态实体;它通过逐渐整合学生网络的参数随时间演变。这是通过一种称为指数移动平均的技术完成的,其中教师的参数被更新为其当前参数和学生参数的加权平均值。
目标是最小化学生表示和教师表示之间的差异,这些表示是针对相同增强图像视图的。这通常是通过使用一个损失函数来实现的,该函数鼓励学生和教师输出之间的对齐,同时确保不同图像的表示保持不同。
通过根据学生网络的学习进度不断更新教师网络,并训练学生网络以匹配教师的输出,DINO有效地利用了两个网络的优势。教师网络为学生提供了稳定和一致的目标,而学生网络推动了学习过程。这种协作设置允许模型在无需手动标签的情况下从数据中学习强大和不变的特征,从而实现有效的自监督学习。
学生和教师的增强输入
在DINO模型中,X1和X2(见上图)指的是同一原始图像X的不同增强视图。这些视图分别用作学生和教师网络的输入。目标是让学生网络学习在这些增强下产生一致的表示。学生和教师模型根据以下策略接收不同的增强:
- 全局裁剪:从原始图像创建两个全局裁剪。这些是覆盖图像大部分的较大裁剪,通常与原始图像有很高的重叠。除了其他增强(如颜色抖动、高斯模糊、翻转等)之外。
- 局部裁剪:除了全局裁剪外,教师网络还接收几个局部裁剪。这些是关注图像不同部分的较小裁剪,捕捉更多局部细节。
我们将如何为参数图像定义这些增强,这些图像包含我们在训练期间想要转换的一批图像。
蒸馏损失
在这里,我们希望使用某种距离度量来计算学生输出和教师输出之间的损失。我们这样做:
- 获取教师预测输出的中心化Softmax,然后应用锐化。
- 获取学生的Softmax预测,然后应用锐化。
- 中心化:中心化教师的输出确保学生模型更多地关注教师输出分布中最显著的特征或区别。通过中心化分布,鼓励学生更多地关注对准确预测至关重要的显著特征,而不是受数据中的变化或偏差的影响。这有助于更有效的知识传递,并可能导致学生模型的性能提高。
- 锐化:锐化涉及放大数据分布中的特定特征,旨在强调教师模型突出的区分。这个过程使学生模型能够专注于学习教师预测中存在的复杂细节,这对于在数据集上准确复制其输出至关重要。
训练DINO模型

阐明DINO伪代码的图像,取自官方论文
有3个重要的步骤需要强调:
(1) 获取学生和教师架构的不同输入(x1,x2)的增强。
(2) 我们之前讨论的蒸馏损失函数,注意它是如何计算不同增强输入的架构的蒸馏损失的,即gs({x1, x2})和gt({x1, x2})。
(3) 更新(a)学生参数(b)教师参数和(c)中心。这里的关键是我们对更新教师参数执行指数移动平均更新。
- 教师参数:EMA应用于教师模型的参数。而不是在每次训练迭代中直接更新教师参数,EMA随时间维护这些参数的移动平均值。这个移动平均值作为教师模型的更平滑、更稳定的表示,可以帮助指导学生模型的训练。
- 中心:此外,在DINO的一些实现中,EMA也用于更新中心。中心代表教师输出分布的平均值,用于归一化目的。通过应用EMA更新中心,它在整个训练过程中逐渐演变,为归一化提供更稳定的参考点。
DINO模型
为了更新教师的参数,我们使用论文中提出公式,即gt.param = gt.param*beta + gs.param*(1 — beta),其中beta是移动平均衰减,gt、gs分别是相应的教师和学生架构。
进一步,我们在__init__下看到,教师的参数已设置为“required_grads = False”,因为我们不希望在反向传播期间更新它们,而是应用移动平均更新。
此外,在PyTorch中将变量初始化为bugger是一种常见方法,用于将其保持在梯度图之外,并不参与反向传播。
Dino模型进一步需要如下调用
在这里,我们传递学生和教师架构,这不过是标准的视觉变换器,即ViT-B/16或ViT-L/16,正如第一篇论文中提出的。
最终训练
现在可以将整个实现放入训练循环中,正如论文中提出的。
(1) 我们用不同的全局和局部增强计算x1和x2。
(2) 之后,我们根据论文中提出的,为学生和教师模型获取输出,回想上面的算法循环图。
(3) 在这里,我们将torch设置为no_grad()函数,以确保教师的参数不会通过反向传播更新。
(4) 最后,我们再次根据论文中提出的方法计算蒸馏损失。
(5) 在蒸馏损失中,我们首先中心化教师模型的输出,这样学生模型就不容易崩溃,也不会只学习不重要的特征,或者比另一个特征更多地学习一个特征,而是专注于从教师模型中学习最独特和潜在的特征。
(6) 然后我们锐化特征,以便在计算损失时,我们现在能够比较两个特征(学生和教师的)具有非常不同的数据分布,这意味着锐化后,更重要的特征会被锐化,而不太重要的特征则不会,这将创建一个更独特的特征图,使学生更容易学习。
(7) 然后我们执行反向传播并执行optimizer.step(),更新学生模型并通过之前实现的指数移动平均更新教师网络。
(8) 作为最后一步,我们将再次将torch设置为no_grad()并通过移动平均更新中心。我们根据教师的输出更新中心,因此它与训练过程中输出数据分布的变化保持一致。
就这样,这就是如何从零开始训练DINO模型。到目前为止,在视觉变换器系列中,我们已经实现了标准的ViT、Swin、CvT、Mae和DINO(自监督)。希望你喜欢阅读这篇文章。