本文经AIGC Studio公众号授权转载,转载请联系出处。
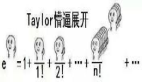
Qwen2vl-Flux 是一种先进的多模态图像生成模型,它利用 Qwen2VL 的视觉语言理解能力增强了 FLUX。该模型擅长根据文本提示和视觉参考生成高质量图像,提供卓越的多模态理解和控制。让 FLUX 的多模态图像理解和提示词理解变得很强。
Qwen2vl-Flux有以下特点:
- 无文本图像直接基于图像生成图像;
- 类似 IPA 将图片和文字结合生成对应风格的图片;
- GridDot控制面板,细致的风格提取;
- ControlNet 集成,支持 Depth 和 canny

相关链接
- 代码:https://github.com/erwold/qwen2vl-flux
- 模型:https://huggingface.co/Djrango/Qwen2vl-Flux
模型架构

该模型将 Qwen2VL 的视觉语言功能集成到 FLUX 框架中,从而实现更精确、更具情境感知的图像生成。关键组件包括:
- 视觉语言理解模块(Qwen2VL)
- 增强型 FLUX 主干
- 多模式生成管道
- 结构控制集成
特征
- 增强视觉语言理解:利用 Qwen2VL 实现卓越的多模式理解
- 多种生成模式:支持变异、img2img、修复和控制网引导生成
- 结构控制:集成深度估计和线路检测,实现精确的结构引导
- 灵活的注意力机制:通过空间注意力控制支持焦点生成
- 高分辨率输出:支持高达 1536x1024 的各种宽高比
生成示例
图像变化
在保持原始图像本质的同时,创造出多样化的变化:



图像混合
通过智能风格转换无缝融合多幅图像:


文本引导的图像混合
通过文本提示控制图像生成:


基于网格的风格迁移
应用网格注意力的细粒度样式控制: