在当今数据驱动的时代,高效的数据处理尤其是数据插入操作对于各类应用系统的性能表现至关重要。当我们聚焦到 MyBatis 这个强大的框架时,探索其高效插入数据的方法就成为了提升系统效率的关键一环。
随着业务的不断发展和数据量的持续增长,我们常常面临着如何在保证数据准确性的前提下,尽可能快速地将大量数据插入到数据库中的挑战。MyBatis 作为一款广泛应用的持久层框架,提供了多种途径和策略来实现高效的插入操作。在接下来的文章中,我们将深入剖析 MyBatis 在高效插入数据方面的独特之处,从基本原理到实际应用技巧,逐一揭开其神秘面纱。无论是新手开发者还是经验丰富的技术人员,都能从这里获得对 MyBatis 高效插入数据更深入的理解和实用的指引,从而为构建更高效、更稳定的系统奠定坚实的基础。

一、关于MySQL批量插入的一些问题
MySQL一直是我们互联网行业比较常用的数据,当我们使用半ORM框架进行MySQL大批量插入操作时,你是否考虑过这些问题:
- 进行大数据量插入时,是否需要进行分批次插入,一次插入多少合适?有什么判断依据?
- 使用foreach进行大数据量的插入存在什么问题?
- 如果插入批量插入过程中,因为服务器宕机等原因导致插入失败要怎么办?
基于此类问题,笔者以自己日常的开发手段作为依据演示一下MySQL批量插入的技巧。
二、常见的三种插入方式演示
1. 实验样本数据
为了演示,这里给出一张示例表,除了id以外,有10个varchar字段,也就是说全字段写满的话一条数据差不多1k左右:
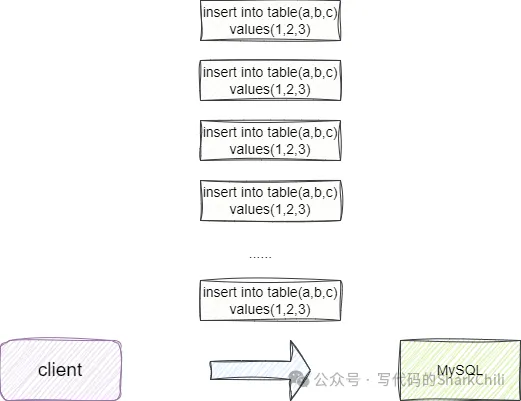
2. 使用逐行插入
我们首先采用逐行插入方式分别插入3000、10w条的数据,这里为了保证实验的准确性,提前进行代码预热,先插入5条数据,然后在进行大批量的插入:
输出结果如下,可以看到当进行3000条数据的逐条插入时耗时在3s左右:
而逐行插入10w条的耗时将其2min,插入表现可以说是非常差劲:
3. 使用foreach语法实现批量插入
Mybatis为我们提供了foreach语法实现数据批量插入,从语法上不难看出,它会遍历我们传入的集合,生成一条批量插入语句,其语法格式大抵如下所示:
批量插入代码如下所示:
对应xml配置如下:
实验结果如下,使用foreach进行插入3000条的数据耗时不到1s:
当我们进行10w条的数据插入时,受限于max_allowed_packet配置的大小,max_allowed_packet定义了服务器和客户端之间传输的最大数据包大小。该参数用于限制单个查询或语句可以传输的最大数据量,我们通过show VARIABLES like '%max_allowed_packet%';默认情况下为67108864大约6M左右,所以这也最终导致了这10w条数据的插入直接失败了。
4. 使用批处理完成插入
再来看看笔者最推荐的一种插入方式——批处理插入,批处理的工作原理是在一次SQL连接通信提交多条SQL执行语句,通过减少网络往返的开销来提升SQL执行效率的一种手段,需要注意使用批处理的时候需要注意以下几点:
- 批处理会以批次为单位提交SQL执行语句,如果涉及大批量的批处理大查询操作,SQL服务器内存资源存在被这批次查询耗尽的风险。
- 批处理提交或者查询的数据过大时会导致传输包过大,也可能导致网络传输耗时长的问题。
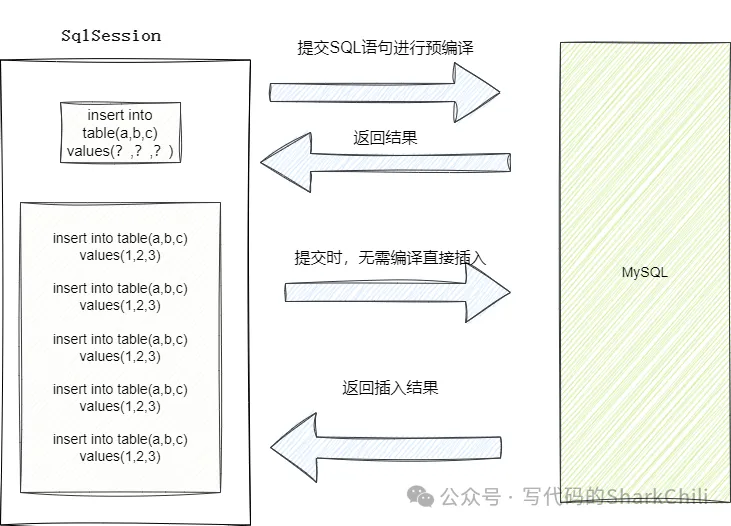
在正式介绍这种插入方式前,读者先确认自己的链接配置是否添加了这条配置语句,只有在MySQL连接参数后面增加这一项配置才会使得MySQL5.1.13以上版本的驱动批量提交你的插入语句。
完成连接配置后,我们还需要对于批量插入的编码进行一定调整,Mybatis默认情况下执行器为Simple,这种执行器每次执行创建的都是一个全新的语句,也就是创建一个全新的PreparedStatement对象,这也就意味着每次提交的SQL语句的插入请求都无法缓存,每次调用时都需要重新解析SQL语句。 而我们的批处理则是将ExecutorType改为BATCH,执行时Mybatis会先将插入语句进行一次预编译生成PreparedStatement对象,发送一个网络请求进行数据解析和优化,因为ExecutorType改为BATCH,所以这次预编译之后,后续的插入的SQL到DBMS时,就无需在进行预编译,可直接一次网络IO将批量插入的语句提交到MySQL上执行。
可以看到进行3000条数据插入时,耗时也只需只需179ms左右:
而进行10w条数据批处理插入的时机只需4s左右,效率非常可观。
三、更高效的插入方式
因为Mybatis对于原生批处理操作做了很多的封装,其中涉及很多校验检查和解析等繁琐的流程,所以通过使用原生JDBC Batch来避免这些繁琐的解析、动态拦截等操作,对于MySQL批量插入也会有显著的提升。感兴趣的读者可以自行尝试,笔者这里就不多做演示了。
四、详解批处理高效的原因
针对上述三种方式,笔者来解释一下为什么在能够确保不出错的情况下,批处理插入的效率最高,我们都知道MySQL进行插入操作时整体的耗时比例如下:
由此可知,进行SQL插入操作时,最耗时的操作是网络连接,这也就是为什么在进行3000条数据插入时,foreach和批处理插入的性能的性能表现最出色。因为逐行插入提交时,每一条插入操作都会进行至少两次的网络返回(如果生成的是stament对象则是两次,PreparedStatement则还要加上预编译的网络往返),在大量的插入情况下,所有的语句都需要经历一次最耗时的链接操作,性能自然是下降了不少。

这里笔者给出逐条插入的时的执行调试日志,可以看到每条插入都会进行一次预编译:

相比之下批处理和foreach一次预编译加上一次网络往返即可完成SQL执行,效率自然是上去的:
对应我们也给出批处理和foreach插入的执行日志印证这一点:

我们再来说说为什么批处理比foreach高效的原因,明明同样是3000条语句的插入,foreach传输的数据包大小也小于批处理,为什么批处理的性能却要好于foreach插入操作呢?
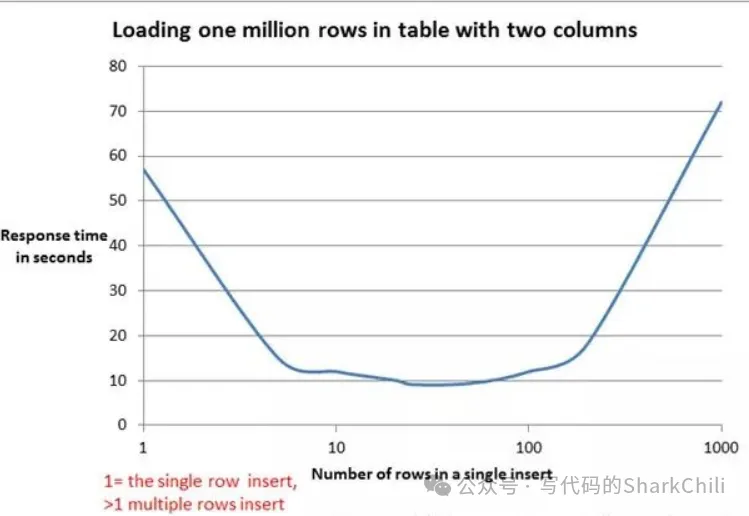
foreach插入进行预编译之后,存在一个字符串解析拼接的操作,这就意味着如果本次插入的数据锅大就会存在一个漫长的SQL拼接耗时,结合mybatis官网给出的压测报告来看,在20~50行左右的插入性能表现最好,超过这个数字之后表现就会逐渐变差:
对此我们也给出mybatis的foreach语法底层的字符拼接的实现,即FilteredDynamicContext 下的appendSql方法:
五、一次插入多少数据量合适
明确要使用批处理进行批量插入之后,我们再来了解下一个问题,一次性批量插入多少条SQL语句比较合适?
对此我们基于100w的数据,分别按照每次10、500、1000、20000、80000条压测,最终实验结果如下:
在经过笔者的压测实验时发现,在2000条差不多2M大小的情况下插入时的性能最出色。这一点笔者也在网上看到一篇文章提到MySQL的全局变量max_allowed_packet,它限制了每条SQL语句的大小,默认情况下为4M,而这位作者的实验则是插入数据的大小在max_allowed_packet的一半情况下性能最佳。
当然并不一定只有上述条件影响批量插入的性能,影响批量插入的性能原因还有:
插入缓存:对于innodb存储引擎来说,插入是需要耗费缓冲池内存的,如果在写密集的情况下,插入缓存会占用过多的缓冲池内存,若插入操作占用大小超过缓冲池的一半,则会影响操其他的操作。
关于缓冲池的大小,可以通过下面这条SQL查看,默认情况下为134M:
索引的维护:这点相信读者比较熟悉,如果每次插入涉及大量无序且多个索引的维护,导致B+tree进行节点分裂合并等处理,则会消耗大量的计算资源,从而间接影响插入效率。
六、使用批处理的注意事项
批处理就是将一批操作提交至MySQL服务器一次性操作,但无法保证事务的原子性,所以读者在使用批处理操作时,若需要保证操作原子性则需要考虑一下事务问题。
七、小结
整篇文章的篇幅不算很大,可以看到笔者针对此类问题常见的做法是:
- 明确问题和要解决的问题,以批量插入为例,首要问题就是现有方案中可以有几种插入方式和如何提高这些插入技术的性能。
- 将问题切割成无数个子问题,笔者将批量插入按步骤分为:如何插入和插入多少的子问题。
- 搜索常见的解决方案,即笔者上述的的逐条插入、foreach、批处理3种插入方式。
- 基于现成方案采用不同量级的样本进行求证,为避免偶然性,笔者将插入的量级设置为几千甚至几万不等。
- 基于实验样本复盘总结,在明确批量插入技术之后,继续查阅资料寻找插入量级,并继续实验从而得出最终研究成果。
- 进阶,对于上述成果继续加以求证了解工作原理,并对后续可能存在的问题查阅更多资料进行兜底。