在不断发展的深度学习领域,PyTorch 已经成为开发者和研究人员家喻户晓的名字。其动态计算图、灵活性以及广泛的社区支持使其成为构建从简单神经网络到复杂前沿模型的首选框架。然而,灵活性也带来了编写大量样板代码的责任——尤其是在训练循环、日志记录和分布式学习方面。这就是 PyTorch Lightning 的用武之地,它提供了一个结构化的高级接口,自动化了许多底层细节。

在本文中,我们将深入探讨普通 PyTorch 和 PyTorch Lightning 之间的区别,通过实际示例突出它们的关键差异,并探讨每种方法如何适应您的工作流程。我们还将包括一个比较训练流程的流程图、相关引文以供深入研究,以及一些有用的视频链接,以便您可以在这两个框架之间进行有指导的探索。
一、背景:PyTorch 基础
在比较 PyTorch 和 PyTorch Lightning 之前,有必要回顾一下 PyTorch 最初吸引人的地方。
1. 动态计算图
PyTorch 使用动态计算图,这意味着图是即时生成的,使开发者能够编写感觉更自然、更直观的 Python 代码,便于调试。在早期框架(如 TensorFlow 的早期版本)中,您必须在运行之前定义一个静态图,这在处理动态输入或特殊架构时引入了复杂性。
2. Pythonic API
PyTorch 与 Python 深度集成。这种协同作用使其特别适合开发者,因为您可以利用原生 Python 功能和调试工具。代码流畅,使实验变得简单直接。
3. 精细控制
能力越大,责任越大。在普通的 PyTorch 中,您需要负责编写训练循环、更新权重(优化器、调度器)、将数据移动到设备上或从设备上移出,并自行处理任何特殊的日志记录或回调。如果您想要精细控制或正在构建高度专业化的研究模型,这是理想的选择。
二、介绍 PyTorch Lightning
PyTorch Lightning 旨在减少样板代码并促进最佳实践,通常被描述为 PyTorch 上的轻量级封装。它没有重新发明轮子,而是专注于简化训练过程:
- 减少样板代码:您不再需要从头编写训练循环;PyTorch Lightning Trainer 会处理它。
- 强制执行结构:鼓励采用模块化方法构建神经网络。您定义一个包含模型架构、training_step、validation_step 和其他步骤(如果需要)的 LightningModule。
- 内置功能:内置日志记录(通过 Lightning 的日志记录器)、分布式训练支持、检查点、早停等。
PyTorch Lightning 不会限制您,而是保留了 PyTorch 的底层灵活性。如果您需要深入研究,可以覆盖方法或合并自定义逻辑,而不会失去框架结构的好处。
三、一对一差异
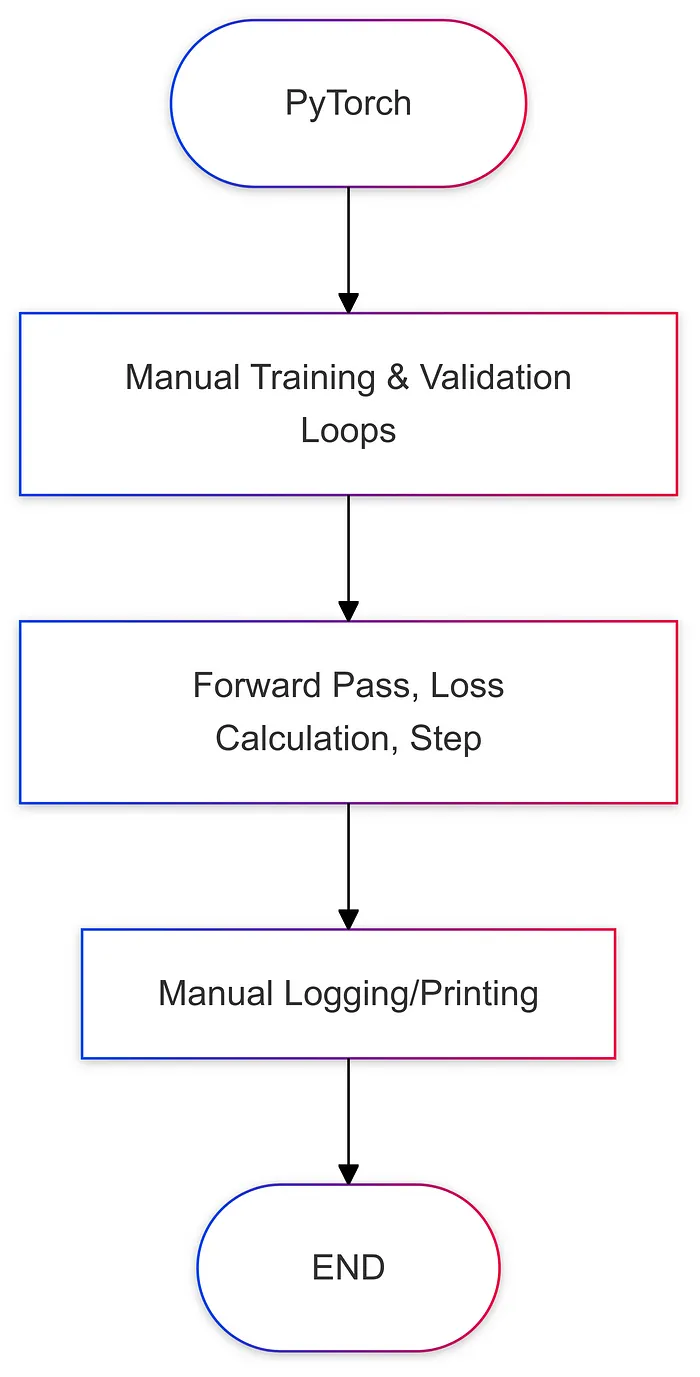
1. 训练循环与样板代码
PyTorch:
- 您需要手动编写训练、验证和测试循环。
- 您必须跟踪批次迭代、前向传播、反向传播、优化器和日志记录(如果需要)。
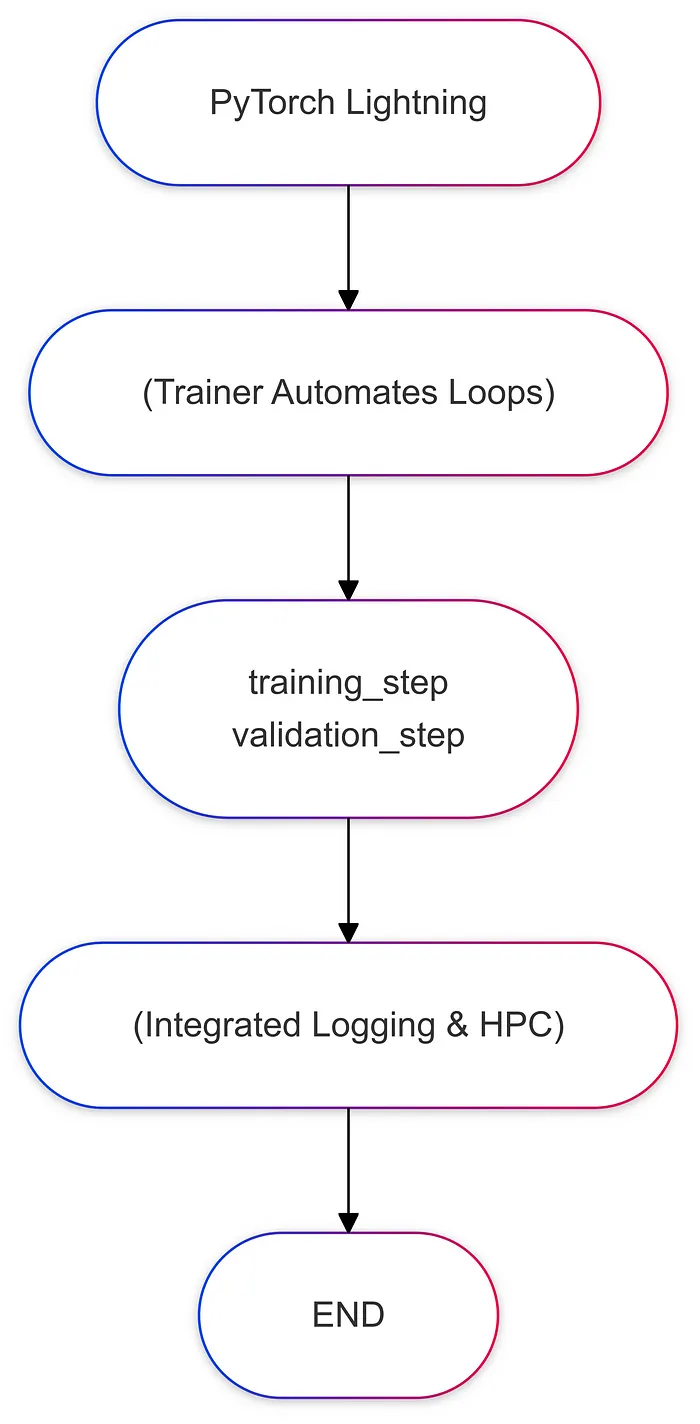
PyTorch Lightning:
- 可以在 LightningModule 中实现 training_step()、validation_step() 和 configure_optimizers() 等方法。
- Trainer 负责协调循环,在后台调用这些方法,并抽象出重复的部分(例如,for batch in train_loader: ...)。
优势:在 Lightning 中,您可以专注于逻辑(如何训练)而不是脚手架(在哪里放置循环、如何记录日志等)。
2. 日志记录与实验跟踪
PyTorch:
- 通常通过自定义解决方案完成:tensorboardX、日志记录库或手动打印语句。
- 您需要编写代码来保存指标、写入日志或生成 TensorBoard 可视化。
PyTorch Lightning:
- 集成日志记录器:TensorBoard、Comet、MLflow、Neptune 等。
- 简单的调用如 self.log('train_loss', loss, on_step=True) 在后台处理指标记录。
- 内置检查点,根据验证指标自动保存最佳或最新模型。
优势:日志记录和检查点几乎自动化,鼓励更好的可重复性。
3. 分布式与多 GPU 支持
PyTorch:
- 需要 nn.DataParallel 或更高级的方法如 DistributedDataParallel。
- 您必须仔细处理设备分配、批次分割和同步。
PyTorch Lightning:
- 通过单个参数启动多进程或多 GPU 训练(例如,Trainer(gpus=2, accelerator='gpu'))。
- Lightning 管理分布式采样、梯度同步等。
优势:它简化了 HPC(高性能计算)或多 GPU 使用,让您专注于模型而不是并行化的细节。
4. 代码组织
PyTorch:
- 灵活,但如果不强制执行一致的代码结构,可能会变得混乱。
- 典型的模式是将模型定义放在一个文件中,训练逻辑放在另一个文件中,但您可以自由选择。
PyTorch Lightning:
- 强制执行最佳实践结构:一个类用于 LightningModule,一个类用于数据模块或数据加载器,一个 Trainer 用于协调运行。
- 这可以在生产场景中创建更易维护的代码。
四、实践示例
为了更好地说明,让我们考虑一个在虚拟数据集上的简单前馈网络。我们将看一个最小的 PyTorch 方法,然后是 PyTorch Lightning 中的等效方法。虽然以下代码片段是简化的,但它们展示了代码结构的典型差异。
1. PyTorch 中的最小训练循环
关键点:
- 手动清零梯度、计算前向传播、反向传播和记录日志。
- 如果要分离训练集和验证集,必须添加额外的代码。
- 除非自己编写代码,否则没有内置的检查点或高级功能。
2. PyTorch Lightning 中的等效训练
关键点:
- 没有手动循环 epoch,也没有手动清零梯度。
- 分离的 training_step 和 validation_step。
- 日志记录通过 self.log("train_loss", loss) 自动完成,并与 Lightning 的系统集成。
五、流程图比较
以下是每个框架中训练流程的简化图示:
六、最佳实践与使用场景
1. 何时坚持使用普通 PyTorch
研究原型:如果您正在试验全新的架构,可能会频繁更改训练循环。
完全控制:您需要做一些高度定制的事情,比如每次迭代修改梯度更新或实现可能不适合 Lightning 回调结构的奇特优化程序。
2. 何时使用 PyTorch Lightning
生产与团队项目:如果您需要一致、可读的代码以便多个开发者加入。
分布式训练或多 GPU:Lightning 大大减少了多 GPU 或多节点训练的开销。
快速实验:如果您重视以最少的样板代码、集成日志记录和易于调试的速度构建实验。
3. 混合方法
这并不总是一个二选一的决定。一些团队在普通 PyTorch 中构建原型,然后将稳定的代码迁移到 Lightning 以用于生产。如果您需要部分自动化和部分自定义逻辑,也可以通过覆盖某些钩子在 Lightning 中编写自定义循环。
七、结论
在 PyTorch 和 PyTorch Lightning 之间做出选择最终取决于您对灵活性与自动化的重视程度。PyTorch 提供了无与伦比的控制水平,非常适合前沿研究或需要大量自定义训练循环的场景。另一方面,PyTorch Lightning 将这种能力封装在一个结构化、一致的接口中,减少了样板代码,简化了多 GPU 训练,并鼓励了内置日志记录和模块化设计等最佳实践。
对于许多从事生产级代码的数据科学家和机器学习工程师来说,Lightning 可以帮助保持代码的可读性、可重复性和效率。如果您是研究人员或喜欢微管理训练过程的每个方面,您可能会继续偏爱普通的 PyTorch。事实上,真正的美在于 PyTorch Lightning 仍然由 PyTorch 驱动:如果您需要深入了解,自由仍然存在。