













在现代软件开发中,高效的数据结构和算法设计对于构建高性能系统至关重要。有序集合(Sorted Set)作为一种常用的数据结构,在许多应用场景中发挥着重要作用,例如缓存、索引、排名等。本文将深入探讨有序集合的内部机制,分析其源代码,并揭示其实现细节。
注意,本着对核心数据结构的剖析,本文有序集合的所有指令操作都是以字典+跳表这两个编码展开讨论,对于压缩列表的实现细节就不会涉及。

一、详解有序集合核心指令实现
1. 跳表相关导读
本文着重于讲解有序集合内部核心实现,会涉及大量跳表的知识点,需要了解的读者建议阅读一下笔者下面这篇关于跳表设计与实现的文章:
2. 元素添加指令zadd
有序集合添加指令就是zadd,它支持添加一个或者多个指令,对应的操作示例如下,可以看到操作成功之后就会返回添加的元素数:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 1 "uno"
(integer) 1
redis> ZADD myzset 2 "two" 3 "three"
(integer) 2对应的指令函数源码的实现是zaddCommand,该函数大体按照如下步骤进行:
- 检查元素是否能被2整除来校验参数个数是否正确。
- 检查有序集合的key是否存在且类型确实是有序集合。
- 逐个遍历元素及其score查看该元素是否存在,如果不存在则先插入操有序集合底层的跳表中来维护元素之间的先后顺序。确保这步操作成功后再将元素指针添加到有序集合的字典中,保证单元素检索的效率。
- 如果元素已存在,则会将该元素从跳表中删除,保证关于这个元素的索引都清理干净后在进行插入,以保证跳表的正确性,因为元素已经在有序集合字典中存在了,所以更新操作就不会操作字典了。
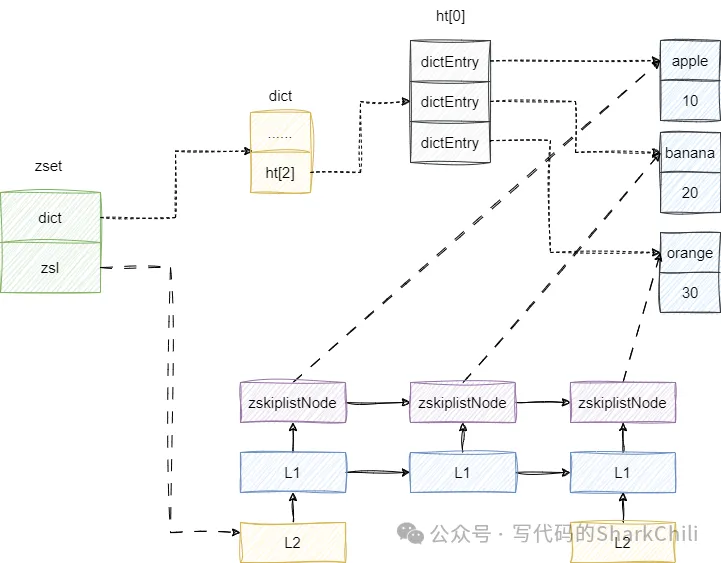
对应我们也给出操作的源码细节,读者可以参照笔者的上述的讲解了解一下源码的细节:
//调用zaddGenericCommand并传入0,意为告知zaddGenericCommand要返回本次操作的添加数(不包括更新)
void zaddCommand(redisClient *c) {
zaddGenericCommand(c,0);
}
/* This generic command implements both ZADD and ZINCRBY. */
void zaddGenericCommand(redisClient *c, int incr) {
//.......
//拿到有序集合里面element和score有几对
int j, elements = (c->argc-2)/2;
int added = 0, updated = 0;
//检查参数是否是基数个,如果是则报错
if (c->argc % 2) {
addReply(c,shared.syntaxerr);
return;
}
//创建score数组
scores = zmalloc(sizeof(double)*elements);
//遍历score转为double类型,将转换后的结果存到scores数组中,后续元素的score都依次按照顺序从数组中获取
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[2+j*2],&scores[j],NULL)
!= REDIS_OK) goto cleanup;
}
//查看这个有序集合是否在redis中存在
zobj = lookupKeyWrite(c->db,key);
//如果不存在则进行初始化,然后添加到redis数据库中
if (zobj == NULL) {
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[3]->ptr))
{
//创建有序集合对象
zobj = createZsetObject();
} else {
//......
}
//添加到内存数据库中
dbAdd(c->db,key,zobj);
}
//遍历传入的每一个元素
for (j = 0; j < elements; j++) {
//拿到元素的score
score = scores[j];
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {//如果转为跳表,则直接走跳表的逻辑
//......
//将元素进行编码转换
ele = c->argv[3+j*2] = tryObjectEncoding(c->argv[3+j*2]);
//查看字典中是否存在这个元素
de = dictFind(zs->dict,ele);
//如果存在,则进行更新操作
if (de != NULL) {
//......
//比对socre与之前的结果是否一致,,如果不一致则说明该元素的排名要改变,需将其从跳表中移除再插入维护节点之间新的关系
if (score != curscore) {
redisAssertWithInfo(c,curobj,zslDelete(zs->zsl,curscore,curobj));
znode = zslInsert(zs->zsl,score,curobj);
incrRefCount(curobj); /* Re-inserted in skiplist. */
dictGetVal(de) = &znode->score; /* Update score ptr. */
server.dirty++;
updated++;
}
} else {
//先插入到跳表,然后再插入到字典中
znode = zslInsert(zs->zsl,score,ele);
incrRefCount(ele); /* Inserted in skiplist. */
redisAssertWithInfo(c,NULL,dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
incrRefCount(ele); /* Added to dictionary. */
server.dirty++;
added++;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
//因为我们传入的值是0,所以返回添加结果added
if (incr) /* ZINCRBY */
addReplyDouble(c,score);
else /* ZADD */
addReplyLongLong(c,added);
//......
}3. 有序集合元素数量查询指令zcard
zcard常用于查看当前有序集合的长度,对应的使用示例如下所示:
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2
redis> 因为上述的操作,有序集合底层都会通过压缩列表或者跳表维护长度,所以调用zcard的时候,本质上就是通过length字段返回当前有序集合的长度:
void zcardCommand(redisClient *c) {
robj *key = c->argv[1];
robj *zobj;
//查看key是否存在,如果不存在则返回0,如果不是有序集合则返回错误码
if ((zobj = lookupKeyReadOrReply(c,key,shared.czero)) == NULL ||
checkType(c,zobj,REDIS_ZSET)) return;
//调用zsetLength返回有序集合中的元素数
addReplyLongLong(c,zsetLength(zobj));
}4. 有序集合顺序遍历指令zrange
ZRANGE指令用于顺序遍历有序集合中所有元素,如果加上WITHSCORES关键字那么该指令就会返回元素及其score:
redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示整个有序集成员
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"
redis 127.0.0.1:6379> ZRANGE salary 1 2 WITHSCORES # 显示有序集下标区间 1 至 2 的成员
1) "tom"
2) "5000"
3) "boss"
4) "10086"我们以下面这张图为例,假设我们希望查询索引1即orange及其之后的元素,有序集合会从最高层索引开始,依次按照下述步骤执行:
- 在L3的头节点开始,走两步就到达orange的索引。
- 基于该索引定位到orange元素。
- 基于orange的forward指针不断向前进即完成后续元素遍历。
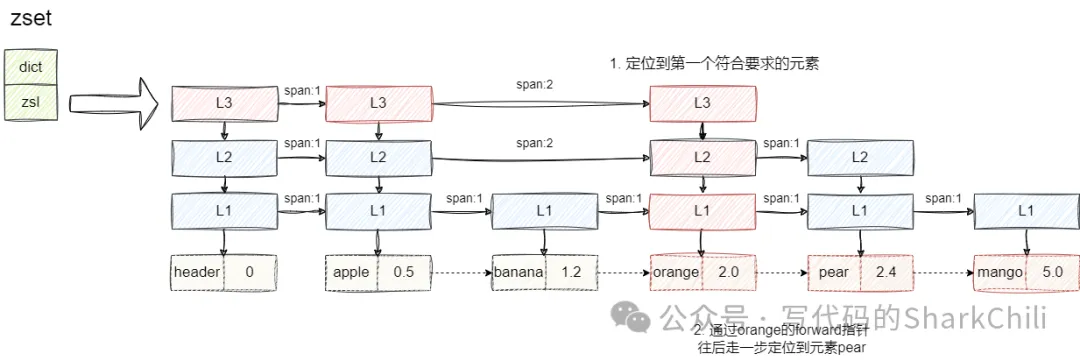
对此我们给出zrange指令实现的函数zrangeCommand,可以看到其底层是调用zrangeGenericCommand并传入0进行顺序查找遍历输出的:
void zrangeCommand(redisClient *c) {
//传入0,代表找到后进行顺序遍历输出
zrangeGenericCommand(c,0);
}我们再给出zrangeGenericCommand的核心代码段,可以看到在进行必要的数值类型转换后,有序集合就会调用跳表的方法zslGetElementByRank按照我们上图所讲解的方式定位到元素,然后基于该元素的forward指针不断步进遍历元素并输出:
void zrangeGenericCommand(redisClient *c, int reverse) {
//......
//判断数值转换是否正常
if ((getLongFromObjectOrReply(c, c->argv[2], &start, NULL) != REDIS_OK) ||
(getLongFromObjectOrReply(c, c->argv[3], &end, NULL) != REDIS_OK)) return;
//如果参数5个且最后一个是withscores,说明需要输出对应的节点和score
if (c->argc == 5 && !strcasecmp(c->argv[4]->ptr,"withscores")) {
withscores = 1;
} else if (c->argc >= 5) {//大于5个则报错
addReply(c,shared.syntaxerr);
return;
}
//非空查询和类型判断
if ((zobj = lookupKeyReadOrReply(c,key,shared.emptymultibulk)) == NULL
|| checkType(c,zobj,REDIS_ZSET)) return;
//......
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
zskiplistNode *ln;
robj *ele;
/* Check if starting point is trivial, before doing log(N) lookup. */
if (reverse) {
ln = zsl->tail;
if (start > 0)
ln = zslGetElementByRank(zsl,llen-start);
} else {//顺序遍历,从索引0层开始遍历
ln = zsl->header->level[0].forward;
if (start > 0)//如果大于0 则定位到要查询的元素位置,传入start+1即走start+1步到指定位置
ln = zslGetElementByRank(zsl,start+1);
}
//基于range不断步进完成后续遍历
while(rangelen--) {
redisAssertWithInfo(c,zobj,ln != NULL);
ele = ln->obj;
addReplyBulk(c,ele);
//如果传入withscores则输出对应元素的score
if (withscores)
addReplyDouble(c,ln->score);
//基于forward或者backward向前或者向后遍历
ln = reverse ? ln->backward : ln->level[0].forward;
}
} else {
redisPanic("Unknown sorted set encoding");
}
}5. 基于给定元素值返回元素排名
获取元素排名的指令为zrank,例如我们有序集合中有如下3个元素,查询tom他在索引1位置,所以返回1,即排第2(索引1再加上1):
redis 127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值
1) "peter"
2) "3500"
3) "tom"
4) "4000"
5) "jack"
6) "5000"
redis 127.0.0.1:6379> ZRANK salary tom # 显示 tom 的薪水排名,第二
(integer) 1其内部调用的函数是zrankCommand,然后其内部调用zrankGenericCommand传入0,代表查询当前元素的顺序排名:
void zrankCommand(redisClient *c) {
//传入0顺序查询排名
zrankGenericCommand(c, 0);
}zrankGenericCommand的源码如下所示,以跳表结构为例,该方法首先通过字典定位到这个元素的score,然后通过跳表的zslGetRank查询这个元素,按照我们上文中一直强调的多级索引跳越查询得到元素经过多少个span,以tom也就是要走2个span,那么zslGetRank就会返回2,基于这个查询结果减去1返回给客户端,客户端即可知晓tom在跳表中的索引值是1:
void zrankGenericCommand(redisClient *c, int reverse) {
//......
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplist *zsl = zs->zsl;
dictEntry *de;
double score;
//对象类型转换
ele = c->argv[2] = tryObjectEncoding(c->argv[2]);
//定位跳表
de = dictFind(zs->dict,ele);
if (de != NULL) {
//从字典中定位score
score = *(double*)dictGetVal(de);
//从跳表中获取rank
rank = zslGetRank(zsl,score,ele);
redisAssertWithInfo(c,ele,rank); /* Existing elements always have a rank. */
if (reverse)
addReplyLongLong(c,llen-rank);
else //返回跨度值-1即得到元素在跳表中的索引
addReplyLongLong(c,rank-1);
} else {
addReply(c,shared.nullbulk);
}
} else {
redisPanic("Unknown sorted set encoding");
}
}6. 删除节点指令zrem
当有序集合删除元素时,除了将该元素从字典中移除,还需要将跳表中关于该元素的指针和索引全部移除,如下图,假设我们要删除orange,本质上就是将orange和score到跳表中定位,将其元素和索引全部删除,然后再将其从字典中删除,并返回删除个数。
需要补充的是,跳表完成删除操作后还会检查最高层索引,如果最高层索引没有任何索引,那么跳表的索引层级就会减去1,可能有读者会问为什么只检查最高层索引,其实这和跳表的设计思想有关,当跳表为新建的节点生成随机层级索引时,创建索引的层级永远和生成的等级一致,例如:
- 创建节点orange,生成索引级别为3,那么1、2层索引也会创建。
- 生成banana生成索引为2,那么1层也会创建索引。
生成apple生成索引层为1,那么就只会创建1层索引。
这就导致高层索引的个数永远是最少的,最先出现索引空的情况永远是最高层索引,所以跳表进行节点删除后索引维护工作永远从最高层级开始。
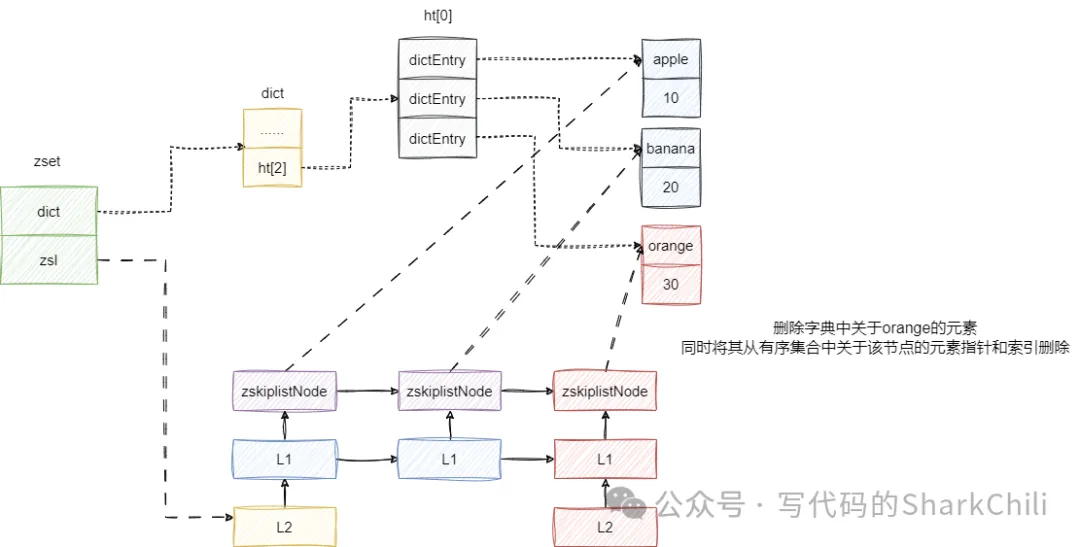
对此我们也给出有序集合中关于zrem操作的源码实现,其核心流程就是笔者说的调用zslDelete从跳表中定位删除,然后再同步删除字典中的元素:
void zremCommand(redisClient *c) {
//......
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
dictEntry *de;
double score;
//遍历key通过字典删除
for (j = 2; j < c->argc; j++) {
//查找有序集合中是否存
de = dictFind(zs->dict,c->argv[j]);
//如果存在则执行删除操作
if (de != NULL) {
deleted++;
/* Delete from the skiplist */
score = *(double*)dictGetVal(de);
//基于元素值和score到跳表进行删除
redisAssertWithInfo(c,c->argv[j],zslDelete(zs->zsl,score,c->argv[j]));
/* Delete from the hash table */
//然后再从字典中删除
dictDelete(zs->dict,c->argv[j]);
//......
}
}
} else {
redisPanic("Unknown sorted set encoding");
}
//......
//返回删除数
addReplyLongLong(c,deleted);
}7. 查询元素数值zscore
该方法并没有利用到跳表,而是直接传入元素值到字典中定位拿到其score返回,在字典冲突较少的情况下时间复杂度为O(1),对应源码如下,比较简单,读者可自行参阅注释了解:
void zscoreCommand(redisClient *c) {
//.......
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
//......
} else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {//通过字典拿到成绩
zset *zs = zobj->ptr;
dictEntry *de;
c->argv[2] = tryObjectEncoding(c->argv[2]);
//将元素待入字典中定位
de = dictFind(zs->dict,c->argv[2]);
//不为空取出它的score返回
if (de != NULL) {
score = *(double*)dictGetVal(de);
//返回score
addReplyDouble(c,score);
} else {
addReply(c,shared.nullbulk);
}
} else {
redisPanic("Unknown sorted set encoding");
}
}
















