












在AI技术日新月异的今天,大型语言模型已成为推动AI发展的重要力量。2024年12月26日,DeepSeek AI正式发布了其最新的大型语言模型——DeepSeek-V3。这款开源模型采用了高达6710亿参数的混合专家(MoE)架构,每秒能够处理60个token,比V2快了3倍。一经发布,就在AI领域引起了轩然大波。
值得注意的是,DeepSeek-V3不仅支持GPU训练与推理,并且发布即支持昇腾平台,在昇腾硬件和MindIE推理引擎上实现高效推理,为用户提供了更多计算硬件的选择。
与GPT-4o不分伯仲,中国大模型领先全球
DeepSeek-V3是一款拥有6710亿总参数和每个令牌激活370亿参数的混合专家(Mixture-of-Experts,MoE)语言模型,由人工智能公司DeepSeek发布。它在继承DeepSeek-V2核心架构的基础上,进行了多项创新,显著提升了模型的性能与效率。
DeepSeek-V3采用了创新的知识蒸馏方法,将DeepSeek R1系列模型中的推理能力迁移到标准LLM中,显著提高了模型的推理性能。
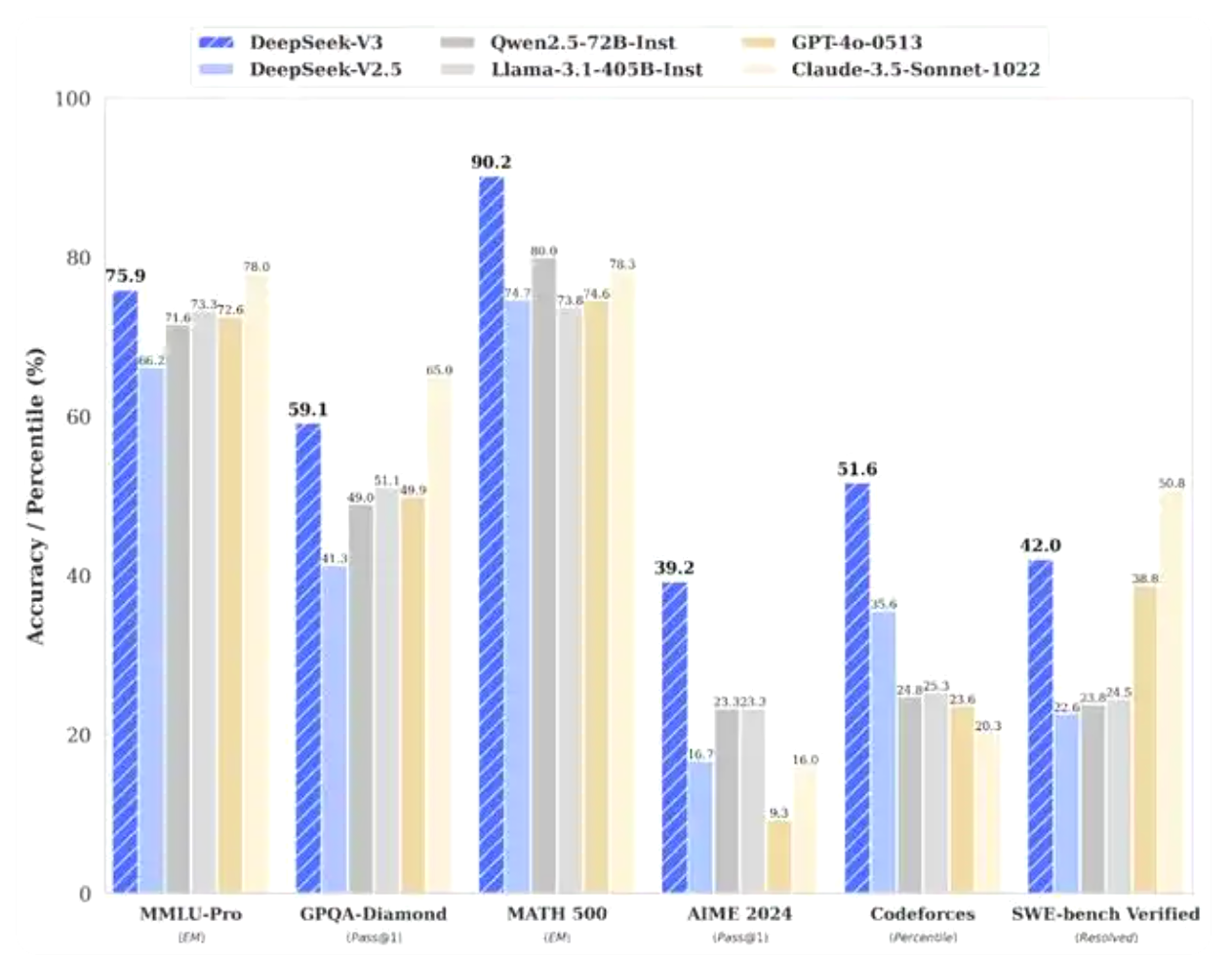
根据DeepSeek公布的测试结果,其运行了多项基准测试来比较性能,V3模型已明显优于包括Meta公司的Llama-3.1-405B和阿里云的Qwen 2.5-72B等一众领先开源模型。在大多数基准测试中,它甚至部分超越了OpenAI的闭源模型GPT-4o。
根据DeepSeek公布的资料显示,V3在知识类任务上的水平相比前代DeepSeek-V2.5显著提升,接近当前表现最好的模型Anthropic公司于10月发布的Claude-3.5-Sonnet-1022。在美国数学竞赛(AIME 2024,MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅超过了其他所有开源闭源模型。在生成速度上,DeepSeek-V3的生成吐字速度从20TPS大幅提高至60TPS,相比V2.5模型实现了3倍的提升,能够带来更加流畅的使用体验。
由于DeepSeek-V3模型首次在大规模模型上验证了FP8训练的可行性和有效性,通过协同优化有效克服了跨节点MoE训练中的通信瓶颈,因此使得DeepSeek-V3在保持高性能的同时,实现了训练成本的极大降低。据DeepSeek官方透露,该模型的训练成本仅为557.6万美元,远低于同类模型的数亿美金训练成本。
作为开源大模型,DeepSeek-V3支持多种开源框架的本地部署,包括SGLang、LMDeploy和TensorRT-LLM,为开发者提供了丰富的选择。与此同时,DeepSeek-V3还支持更多推理引擎,为用户提供了更多计算产品的选择,推动了中国AI产业的创新与发展。
原生支持昇腾AI,为用户提供更多计算产品选择
DeepSeek-V3不仅在技术上取得了重大的突破,而且还实现了对更多推理引擎的原生支持。以昇腾平台为例,DeepSeek-V3发布即支持昇腾平台,让用户能够在昇腾硬件和MindIE推理引擎上实现高效推理,为国内用户提供了软硬件一体化的解决方案。
在魔乐社区上,已经发布了在昇腾硬件和MindIE推理引擎上实现DeepSeek-V3模型的推理的部署方式,用户可以根据操作手册,进行服务框架的调优、监控运维、指定NPU卡、在单机上启动多实例等,优化服务性能和定制运行环境,充分发挥昇腾硬件设备的算力,提升模型推理的效率。(点击了解详细部署方式)
作为昇腾针对AI全场景业务的推理引擎,MindIE在通信加速、解码优化、量化压缩、最优并行、调度优化等方面展现出了显著的优势。
首先,通过高效的RPC(Remote Procedure Call,远程过程调用)接口,MindIE实现了业务层与推理引擎之间的快速通信。这一接口支持Triton和TGI等主流推理服务框架,使得应用部署更加便捷,能够在小时级内完成。
 通信加速示意图
通信加速示意图
其次,在解码优化方面,MindIE提供了针对LLM(Large Language Model,大语言模型)和文生图(SD模型)等特定应用场景的加速参考代码和预置模型。这些优化措施使得MindIE在解码阶段能够更快地生成推理结果,提高了整体性能。特别是针对大模型推理,MindIE支持Continuous Batching、PageAttention、FlashDecoding等加速特性,进一步提升了推理效率。
 解码优化示意图
解码优化示意图
在量化压缩方面,MindIE中的量化方法基于业界先进的量化技术,如SmoothQuant、AWQ等,这些技术能够在保持模型精度的同时,显著减少模型大小和计算量。
 量化压缩示意图
量化压缩示意图
另外,MindIE提供了最优并行策略,以充分利用多核处理器和GPU等硬件资源。在并行计算方面,MindIE支持Tensor Parallelism(张量并行)等策略,这些策略能够使得模型在多个处理器核心上并行运行,从而加快推理速度。通过最优并行策略,MindIE能够在保持模型精度和稳定性的同时,实现更高的推理性能。
 最优并行策略示意图
最优并行策略示意图
在调度优化方面,MindIE提供了多并发请求的调度功能,能够高效地处理大量并发请求。此外,MindIE还支持统一内存池管理KV缓存,这一功能能够减少内存碎片和访问延迟,提高内存利用率。在任务调度方面,MindIE基于调度策略实现用户请求组batch,通过合理的任务分配和调度,使得资源得到充分利用,提高了整体性能。
 调度优化 两阶段混合调度解码 示意图
调度优化 两阶段混合调度解码 示意图
由于DeepSeek-V3能够原生支持昇腾硬件和MindIE昇腾推理引擎,使得用户能够更加轻松地部署和使用DeepSeek-V3模型,进一步推动了AI技术在各个领域的广泛应用。
加速AI技术创新发展,中国大模型迎来新机遇
51CTO认为,DeepSeek-v3的成功,不仅展示了中国在AI创新方面的实力,提升了中国大模型在全球科技竞争中的地位,并且降低了大模型的开发门槛,促进了中国AI软硬件产业的发展,全面推动了AI技术的创新与发展。
首先,DeepSeek-V3充分展示了中国在AI创新方面的实力,提升了中国大模型在全球科技竞争中的地位。随着DeepSeek-V3的成功,越来越多的国际目光将聚焦到中国AI领域,为中国公司争取更多的合作机会和市场空间。
其次,DeepSeek-V3的开源策略和API定价策略,降低了AI技术的应用门槛,促进了技术分享和行业内的合作。开源的DeepSeek-V3不仅促进了AI技术的分享与交流,也进一步降低了行业内的应用门槛,为广大开发者和企业提供了更为经济实惠的选择。
此外,DeepSeek-V3的成功也为中国大模型在垂直领域的深耕细作提供了范例。DeepSeek-V3可以应用于智能家居、智能客服、安防、医疗、写作辅助等多个场景,这为中国大模型在垂直领域的发展提供了广阔的空间和无限的可能。
最后,DeepSeek-V3由于支持更多推理引擎,有助于构建更加完善的AI生态系统。通过与更多推理引擎的紧密合作,DeepSeek-v3可以更好地适应国内用户的需求,推动中国AI技术的普及和应用。
总结:
DeepSeek-V3的成功,不仅展示了中国在AI领域的创新实力,更为中国大模型的未来发展带来了前所未有的新机遇。随着技术的不断进步和应用场景的不断拓展,中国大模型将在全球科技竞争中发挥越来越重要的作用,为人们的生活带来更多的便利和乐趣。
展望未来,随着人工智能技术应用场景的不断扩展,AI行业将迎来更为广阔的发展空间。DeepSeek-V3的成功只是开端,中国大模型将在技术进步和广泛应用的推动下,不断实现新的突破。为此,我们有理由相信,中国大模型在未来的发展中能够不断创新和进步,为全球AI技术的未来发展贡献更多的中国智慧和力量。



















