编辑 | 伊风
有没有人发现——马斯克又又又又跳票了??
你说好“年底”发的Grok 3呢?不会是2025年年底吧
“Grok 3经过100k H100的训练后,2024年底应该会非常特别。”马斯克在7月的一篇X平台帖子中写道,提到xAI在孟菲斯建立的庞大GPU集群。
 图片
图片
在12月15日的帖子表示,“Grok 3将是一次重大的飞跃”。
 图片
图片
然而,今天都1月3日了,也没有听说即将发布Grok 3的消息!
事实上,就算最近xAI有所动作,也只能期待一个折中版的2.5了。
根据推特AI博主Tibor Blaho的帖子,他在xAI网站上发现的某些代码表明,可能即将发布中间模型“Grok 2.5”。
 图片
图片
查看完整代码可移步:https://archive.is/FlmBE
作为马斯克和奥特曼的“打擂台”之作,Grok 系列确实是一个成功的搅局者。
也因此,马斯克预告的Grok 3将带来的“飞跃”,在目前稍显冷清的大模型发布中备受关注。
马斯克本人在做客Fridman的播客中似乎预想到了Grok将会面临的困难。
“你希望Grok 3是最先进的?”主持人问道。
“希望是这样。”马斯克回答。“我的意思是,这是目标。我们可能会失败。但这就是我们的愿景。”
1.AI墙的证明:大模型的下一代集体缺席
这不是马斯克第一次“画饼”没有兑现。众所周知,马斯克关于产品发布时机的声明通常最多只是理想化的目标。
被玩梗后,马斯克自己都跳出来澄清,“对于基于时间的预测,我通常以 50% 的百分位数日期为目标,这意味着我的预测一半会迟到,一半会提前。”
 图片
图片
但Grok 3的缺席却有所不同,因为它是“AI撞墙”论调中不断增加的证据之一。
去年,AI初创公司Anthropic未能按时推出其顶级Claude 3 Opus模型的继任者。在宣布下一代模型Claude 3.5 Opus将在2024年底发布几个月后,Anthropic将该模型的相关信息从开发者文档中删除了。(根据一份报告,Anthropic确实在去年完成了Claude 3.5 Opus的训练,但决定发布它并不符合经济效益。)
据报道,谷歌和OpenAI最近几个月也在其旗舰模型上遭遇了挫折。
这可能是当前AI Scaling Law“过时”的证据——即公司们正在采用的增加模型能力的方法似乎已经失灵。
在不久前,使用大量计算资源和更大规模的数据集来训练模型,能够获得显著的性能提升。但随着每一代模型的推出,增益开始缩小,这促使公司们寻求替代技术。
Grok 3推迟的原因可能有其他方面。例如,xAI的团队规模比许多竞争对手小得多。
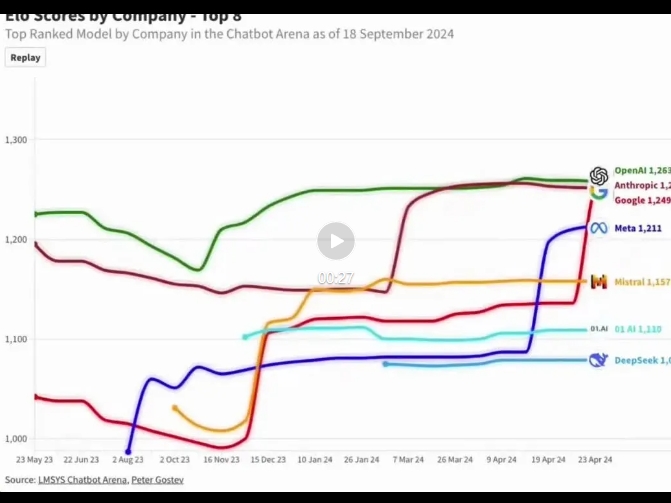
2.变得冷清的模型圈:上一代旗舰模型的推出时间
在AI模型最疯狂的成长期,几乎每一天都能在AI报道的标题中看到“一夜变天”“新王登场”这样的词汇。
曾经有多热闹,现在就有多落寞。
过去的半年,虽然依旧有很多强大的模型推出,但旗舰模型的发布节奏明显变得迟缓了。
以下是一些AI科技巨头,和他们的旗舰模型推出时间,能够更直观地感受到“下一代模型”的空缺已久:
OpenAI - GPT-4
发布时间:2023年3月
Google DeepMind - Gemini 1.5
发布时间:2024年2月
Anthropic - Claude 3.5
发布时间:2024年6月
Meta-Llama 3.1
发布时间:2024年7月
xAI - Grok 2
发布时间:2024年8月
OpenAI-o1
发布时间:2024年9月
许多观点(包括OpenAI前首席研究官)认为o1其实就是“下一代模型”。该模型的计算能力是GPT-4的100倍。
然而,o1 能力增长来源于思维链的加持,而非传统的Scaling Law。
由此可见,从去年下半年开始,大模型的发展似乎已经陷入了集体“哑火”的状态,呈现出传说中的那面无形的“墙”的轮廓。
3.另辟蹊径,大模型要绕过那面墙
年底Ilya一句“预训练走向终结”在AI圈掀起讨论的狂潮。
观之国内,AI大佬也纷纷寻找AI训练的转机与突破。
其中,月之暗面的创始人杨植麟是对预训练仍抱有乐观的少数派。在Kimi数学模型发布的时候,他说自己“对Scaling Law仍然乐观,认为预训练模型还有半代到一代的提升空间,这个空间大概率会由头部大模型在明年释放出来。”
但他也依然承认,Scaling Law的范式有所变化:“做Post-train(后训练)也要Scaling,只是说你Scaling的起点很低。可能很长一段时间,你的算力就不会是瓶颈,这个时候创新能力是更重要的。”
在媒体报道中,上海人工智能实验室主任助理、领军科学家乔宇同样表示“并不是说Scaling Law要被抛弃了,而是应该寻找新的Scaling Law维度,很多难题并不能单纯靠扩大模型规模、数据、算力解决,我们需要更丰富的模型架构和更高效的学习方法,同时也希望在AGI发展过程中,能有来自中国的核心贡献,找到与中国资源禀赋更加匹配的、自主的技术路线”。
阶跃星辰首席科学家张祥雨则更“激进”一些,他直白表示,他对万亿以上参数大模型的能力提升,并不绝对乐观。他说“根据我们的观察,随着大模型规模的不断扩大,归纳相关的能力快速提升,而且可能会继续遵循Scaling Law,但其演绎能力,包括数学和推理方面的能力,随着模型Side进一步提升,不仅没有增长,反而在下降。”
参考链接:
https://techcrunch.com/2025/01/02/xais-next-gen-grok-model-didnt-arrive-on-time-adding-to-a-trend/