














1. 导言
Transformer架构已经成为当今大模型的基石,不管是NLP还是CV领域,目前的SOTA模型基本都是基于Transformer架构的,比如NLP中目前的各种知名大模型,或者CV中的Vit等模型
本次介绍的论文标题为:Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters,” 顾名思义,本文提出了Tokenformer架构,其优势在于增量学习能力:在增加模型尺寸时,无需从头开始重新训练模型,大大降低了成本。 本文代码已开源。
2. Transformer vs Tokenformer - 结构比较
首先我们从顶层设计的角度,对于传统 Transformer 架构和 本文提出的 Tokenformer 架构进行比较,如下图所示:

2.1 Transformer 架构
自注意力机制是Transformer的核心,主要包括以下几个步骤:






如上图所示,一个Transformer层主要由两个部分组成:
- 多头自注意力机制(Multi-Head Self-Attention) :输入首先经过一个线性投影模块,以计算注意力模块的输入,即矩阵 Q、K 和 V。然后利用子注意力机制计算出Token之间的权重
- 前馈神经网络(Feed-Forward Network, FFN) :对于注意力层的输出进行投影,计算出下一层的输入
2.2 Transformer 架构的缺陷
传统Transformer在处理token与参数的交互时,依赖于固定数量的线性投影,这限制了模型的扩展性,这句话本身较难理解,因此接下来详细论述架构的缺陷。
2.2.1 模型的拓展性是什么
模型的拓展性(Scalability)指的是模型在需要更强大性能时,能够有效地增加其规模(如参数数量、计算能力等)而不导致性能下降或计算成本过高的能力。
简而言之,拓展性好的模型可以在保持或提升性能的同时,灵活且高效地扩大其规模。
2.2.2 为什么说传统Transformer的固定线性投影限制了模型的扩展性

3. TokenFormer的解决方案
为了解决模型维度固定导致的模型缺乏拓展性的问题,TokenFormer提出了一种创新的方法,通过将模型参数视为tokens,并利用注意力机制来处理token与参数之间的交互,从而实现更高效、更灵活的模型扩展。

3.1 模型参数Token化
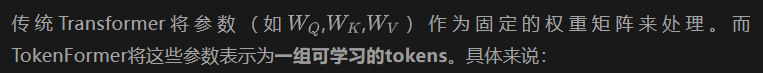
参数Tokens:原本transformer模型的Q、K、V投影层不再是固定的矩阵,而是转化为一组向量(tokens),例如:

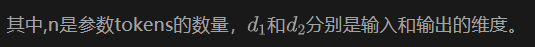
3.2. Token-Parameter Attention(Pattention)层
Pattention层是TokenFormer的核心创新,它通过注意力机制来处理token与参数之间的交互。从而替代原本的Q,K,V,具体过程如下:







4. 总体结构
为方便阅读再把图扔到这:

与传统transformer结构相同,其总体上也包括两层:多头自注意力层和前馈网络层。
4.1 多头自注意力(Single-Head Variant:


4.2 前馈网络(Feed-Forward Network, FFN)


这里也可以看到,相对于Transformer,Tokenformer就是将所有的投影层从固定的全连接网络也变成了Pattention层。
4.3 与transformer的比较

下方公式左侧代表传统Transformer的自注意力机制,右侧代表tokenformer的自注意力机制:

从上边的图中可以清楚看到,相对于transformer,本论文只是将投影层与连接层替换成了新的层。
5. 可扩展性
之前说过,相对于transformer,tokenformer主要是解决可拓展性的问题,那么假设我们要增加参数数量,或者要增加输入维度,tokenformer如何进行增量学习?



这样,模型的参数量可以按需扩展。
初始化策略:新增的参数tokens初始化为零,类似于LoRA技术(Low-Rank Adaptation),确保模型能够在保持原有知识的基础上,快速适应新的参数扩展。
6. 实验部分

与从零重训练的 Transformer 相比,如上图所示,Y 轴代表模型性能,X 轴代表训练成本。蓝线代表使用 3000 亿个 token 从头开始训练的 Transformer 模型,不同的圆圈大小代表不同的模型大小。
其他线条代表 Tokenformer 模型,不同颜色代表不同的Token数量。例如,红线从 1.24 亿个参数开始,扩展到 14 亿个参数,其训练集为从300B token中抽样出的30B Token。最终版本模型的性能与相同规模的 Transformer 相当,但训练成本却大大降低。
黄线显示,使用 60B个Token来训练的增量版本在更低的训练成本下,性能已经比 Transformer 更优。














